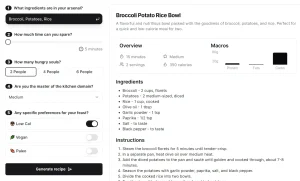
Working with PDFs often feels like trying to edit a printed newspaper – what you see isn’t what you get. For years, I’ve fought with broken formatting when converting technical docs to Markdown, until I found MarkPDFDown.
MarkPDFDown is an open-source, Python-based tool that uses multimodal LLMs (like OpenAI’s models) to transcribe PDF files into clean, well-formatted Markdown. Unlike traditional PDF conversation or OCR tools, this AI-powered tool can “see” and understand PDF documents holistically, rather than just extracting text.
Key Features
- Accurate Structural Preservation: Maintains headings, lists, tables, and other formatting elements.
- Multimodal Understanding: Uses AI to comprehend document layout and content relationships.
- Format Consistency: Produces clean, well-formatted Markdown ready for use in documentation systems.
- Customizable Model Selection: Configure which AI model powers your conversions.
- Simple Command-Line Interface: Straightforward usage with standard input/output operations.
- Docker Support: Run in isolated containers for consistent operation across environments.
Use Cases
- Documentation Migration: Converting legacy PDF documentation into modern knowledge bases
- Content Repurposing: Transforming research papers into blog posts or technical articles
- Data Extraction: Pulling structured information from reports into analyzable formats
- Academic Work: Converting PDF textbooks or papers into study notes
- Technical Writing: Incorporating content from PDF specifications into development docs
How to Use It
Let’s walk through the installation and basic usage. This assumes you have some familiarity with the command line and Python.
1. Prerequisites:
- Python 3.9 or higher.
- An OpenAI API key (you’ll need to sign up for an account at OpenAI).
2. Installation:
The recommended way is to use conda to create a virtual environment:
conda create -n markpdfdown python=3.9
conda activate markpdfdownThen, clone the repository and install the dependencies:
git clone https://github.com/jorben/markpdfdown.git
cd markpdfdown
pip install -r requirements.txt3. Configuration:
You need to set your OpenAI API key as an environment variable:
export OPENAI_API_KEY=<your-api-key>Optionally, you can also set the API base and default model:
export OPENAI_API_BASE=<your-api-base> # Optional
export OPENAI_DEFAULT_MODEL=<your-model> # Optional4. Basic Usage:
To convert a PDF file (input.pdf) to Markdown, run:
python main.py < input.pdf > output.mdThis will create a file named output.md containing the converted Markdown text.
5. Advanced Usage:
You can also specify a starting and ending page:
python main.py page_start page_end < input.pdf > output.md6. Docker Usage (Alternative):
If you prefer using Docker, you can run the tool without installing Python dependencies directly:
docker run -i -e OPENAI_API_KEY=<your-api-key> -e OPENAI_API_BASE=<your-api-base> -e OPENAI_DEFAULT_MODEL=<your-model> jorben/markpdfdown < input.pdf > output.mdTip: I’ve found that it’s often helpful to first run the conversion on a small section of the PDF (using the page_start and page_end arguments) to check the output and make sure the formatting is being handled correctly before converting the entire document.
Practical Tips
- Model Selection Matters: The quality of your conversion depends significantly on which OpenAI model you use. GPT-4o models offer better accuracy for complex layouts than older models.
- Pre-Processing Helps: Clean, high-resolution PDFs convert better. If working with scanned documents, running them through an OCR tool first can improve results.
- Page Batching: For large documents, processing in smaller page batches (10-20 pages) can be more reliable than attempting to convert hundreds of pages at once.
- Handle Images Separately: While the tool recognizes images, you’ll want to extract and manage them separately for best results in your final documents.
- Check Tables Carefully: Complex tables may need manual verification, as table structure is one of the more challenging elements to convert perfectly.
Pros
- Open Source: Free to use and modify.
- Accurate Conversion: Leverages powerful AI models for better accuracy than traditional methods.
- Preserves Formatting: Handles complex layouts surprisingly well.
- Command-Line Interface: Easy to integrate into scripts and workflows.
- Customizable: Allows you to specify the OpenAI model.
Cons
- Requires OpenAI API Key: You need an OpenAI account and API key, which involve costs depending on usage.
- Not Always Perfect: May require some manual cleanup, especially for very complex documents.
- Command-Line Only: No graphical user interface (GUI). It may not be suitable for all users.
- Dependent on External Services: Relies on OpenAI’s API, so it’s subject to their availability and pricing.
Related Resources
- MarkPDFDown GitHub Repository: https://github.com/jorben/markpdfdown
- OpenAI API Documentation: https://platform.openai.com/docs/api-reference
- Markdown Guide: https://www.markdownguide.org/
FAQs
Q: Does MarkPDFDown support OCR (Optical Character Recognition)?
A: MarkPDFDown itself doesn’t perform OCR. It relies on the PDF having selectable text. If you have a scanned PDF, you’ll need to use an OCR tool first to convert it to a text-based PDF.
Q: Can I use a different AI model besides OpenAI’s?
A: Currently, the tool is designed to work with OpenAI’s models. The code would need to be modified to support other models.
Q: Is there a limit on the size of the PDF file I can convert?
A: There isn’t a hard-coded limit within MarkPDFDown itself, but you might be limited by the OpenAI API’s rate limits and token limits. You might need to break very large documents up into smaller chunks.