Hadoop MapReduce Tham gia & truy cập bằng ví dụ
Tham gia Mapreduce là gì?
Mapreduce Tham gia hoạt động được sử dụng để kết hợp hai bộ dữ liệu lớn. Tuy nhiên, quá trình này liên quan đến việc viết nhiều mã để thực hiện thao tác nối thực tế. Việc nối hai tập dữ liệu bắt đầu bằng cách so sánh kích thước của từng tập dữ liệu. Nếu một tập dữ liệu nhỏ hơn so với tập dữ liệu khác thì tập dữ liệu nhỏ hơn sẽ được phân phối đến mọi nút dữ liệu trong cụm.
Sau khi phân phối liên kết trong MapReduce, Mapper hoặc Giảm tốc sẽ sử dụng tập dữ liệu nhỏ hơn để thực hiện tra cứu các bản ghi trùng khớp từ tập dữ liệu lớn, sau đó kết hợp các bản ghi đó để tạo thành bản ghi đầu ra.
Các loại tham gia
Tùy thuộc vào nơi thực hiện phép nối thực tế, các phép nối trong Hadoop được phân loại thành-
1. Tham gia từ phía bản đồ – Khi phép nối được thực hiện bởi người lập bản đồ, nó được gọi là phép nối phía bản đồ. Trong loại này, phép nối được thực hiện trước khi dữ liệu thực sự được chức năng bản đồ sử dụng. Điều bắt buộc là đầu vào của mỗi bản đồ phải ở dạng phân vùng và theo thứ tự được sắp xếp. Ngoài ra, phải có số lượng phân vùng bằng nhau và phải được sắp xếp theo khóa nối.
2. Tham gia bên giảm – Khi phép nối được thực hiện bởi bộ giảm tốc, nó được gọi là phép nối bên rút gọn. Trong phép nối này không nhất thiết phải có tập dữ liệu ở dạng có cấu trúc (hoặc được phân vùng).
Ở đây, quá trình xử lý phía bản đồ sẽ phát ra khóa nối và các bộ dữ liệu tương ứng của cả hai bảng. Do hiệu ứng của quá trình xử lý này, tất cả các bộ dữ liệu có cùng khóa nối sẽ rơi vào cùng một bộ giảm tốc, sau đó nối các bản ghi có cùng khóa nối.
Luồng quy trình tổng thể của các phép nối trong Hadoop được mô tả trong sơ đồ bên dưới.
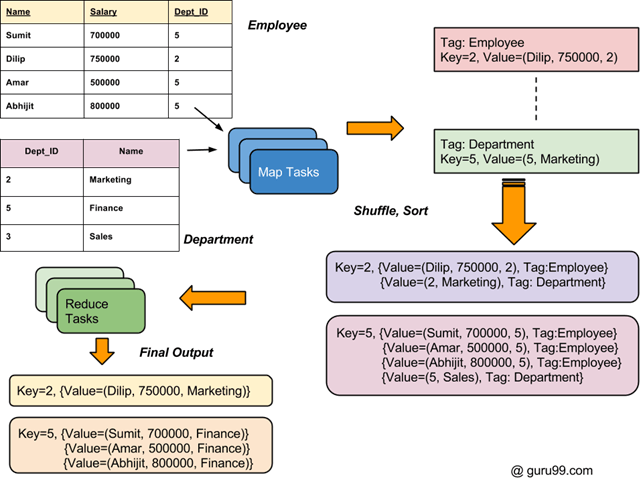
Cách kết hợp hai bộ dữ liệu: Ví dụ về MapReduce
Có hai Bộ dữ liệu trong hai Tệp khác nhau (hiển thị bên dưới). Khóa Dept_ID là chung trong cả hai tệp. Mục đích là sử dụng MapReduce Join để kết hợp các tệp này


Đầu vào: Tập dữ liệu đầu vào là file txt, DeptName.txt & DepStrength.txt
Tải xuống tập tin đầu vào từ đây
Đảm bảo bạn đã cài đặt Hadoop. Trước khi bạn bắt đầu với quy trình thực tế của ví dụ MapReduce Join, hãy thay đổi người dùng thành 'hduser' (id được sử dụng trong khi cấu hình Hadoop, bạn có thể chuyển sang userid được sử dụng trong cấu hình Hadoop của mình).
su - hduser_

Bước 1) Sao chép tệp zip vào vị trí bạn chọn

Bước 2) Giải nén tệp Zip
sudo tar -xvf MapReduceJoin.tar.gz

Bước 3) Chuyển đến thư mục MapReduceJoin/
cd MapReduceJoin/
![]()
Bước 4) Bắt đầu Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh

Bước 5) DeptStrength.txt và DeptName.txt là các tệp đầu vào được sử dụng cho chương trình ví dụ MapReduce Join này.
Những tệp này cần được sao chép sang HDFS bằng lệnh bên dưới-
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal DeptStrength.txt DeptName.txt /

Bước 6) Chạy chương trình bằng lệnh bên dưới-
$HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar MapReduceJoin/JoinDriver/DeptStrength.txt /DeptName.txt /output_mapreducejoin
![]()

Bước 7) Sau khi thực thi, file đầu ra (có tên 'part-00000') sẽ được lưu trữ trong thư mục /output_mapreducejoin trên HDFS
Kết quả có thể được nhìn thấy bằng giao diện dòng lệnh
$HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000

Kết quả cũng có thể được nhìn thấy thông qua giao diện web như-

bây giờ chọn 'Duyệt hệ thống tập tin' và điều hướng tối đa /output_mapreducejoin

Mở phần-r-00000

Kết quả được hiển thị

LƯU Ý: Xin lưu ý rằng trước khi chạy chương trình này vào lần tiếp theo, bạn sẽ cần xóa thư mục đầu ra /output_mapreducejoin
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
Cách khác là sử dụng tên khác cho thư mục đầu ra.
Bộ đếm trong MapReduce là gì?
A Bộ đếm trong MapReduce là một cơ chế được sử dụng để thu thập và đo lường thông tin thống kê về các công việc và sự kiện MapReduce. Bộ đếm theo dõi các số liệu thống kê công việc khác nhau trong MapReduce như số lượng hoạt động đã xảy ra và tiến trình của hoạt động. Bộ đếm được sử dụng để chẩn đoán sự cố trong MapReduce.
Bộ đếm của Hadoop tương tự như việc đặt thông điệp tường trình vào mã cho bản đồ hoặc thu nhỏ. Thông tin này có thể hữu ích cho việc chẩn đoán sự cố trong quá trình xử lý công việc MapReduce.
Thông thường, các bộ đếm này trong Hadoop được xác định trong một chương trình (ánh xạ hoặc rút gọn) và được tăng lên trong quá trình thực thi khi xảy ra một sự kiện hoặc điều kiện cụ thể (cụ thể cho bộ đếm đó). Một ứng dụng rất hay của bộ đếm Hadoop là theo dõi các bản ghi hợp lệ và không hợp lệ từ tập dữ liệu đầu vào.
Các loại bộ đếm MapReduce
Về cơ bản có 2 loại Bản đồGiảm Counters
- Bộ đếm tích hợp của Hadoop:Có một số bộ đếm Hadoop tích hợp tồn tại cho mỗi công việc. Dưới đây là các nhóm truy cập tích hợp-
- Bộ đếm tác vụ MapReduce – Thu thập thông tin cụ thể của nhiệm vụ (ví dụ: số lượng bản ghi đầu vào) trong thời gian thực hiện.
- Bộ đếm hệ thống tập tin – Thu thập thông tin như số byte được đọc hoặc ghi bởi một tác vụ
- Bộ đếm định dạng đầu vào tệp – Thu thập thông tin về một số byte được đọc qua FileInputFormat
- Bộ đếm định dạng đầu ra tệp – Thu thập thông tin về một số byte được ghi thông qua FileOutputFormat
- Bộ đếm công việc – Những bộ đếm này được JobTracker sử dụng. Số liệu thống kê được họ thu thập bao gồm số lượng nhiệm vụ được đưa ra cho một công việc.
- Bộ đếm do người dùng xác định
Ngoài các bộ đếm tích hợp, người dùng có thể xác định bộ đếm của riêng mình bằng cách sử dụng các chức năng tương tự được cung cấp bởi ngôn ngữ lập trình. Ví dụ, trong Java 'enum' được sử dụng để xác định các bộ đếm do người dùng xác định.
Ví dụ về bộ đếm
Một ví dụ MapClass có Bộ đếm để đếm số lượng giá trị bị thiếu và không hợp lệ. Tệp dữ liệu đầu vào được sử dụng trong hướng dẫn này Tập dữ liệu đầu vào của chúng tôi là tệp CSV, Bán hàngJan2009.csv
public static class MapClass
extends MapReduceBase
implements Mapper<LongWritable, Text, Text, Text>
{
static enum SalesCounters { MISSING, INVALID };
public void map ( LongWritable key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException
{
//Input string is split using ',' and stored in 'fields' array
String fields[] = value.toString().split(",", -20);
//Value at 4th index is country. It is stored in 'country' variable
String country = fields[4];
//Value at 8th index is sales data. It is stored in 'sales' variable
String sales = fields[8];
if (country.length() == 0) {
reporter.incrCounter(SalesCounters.MISSING, 1);
} else if (sales.startsWith("\"")) {
reporter.incrCounter(SalesCounters.INVALID, 1);
} else {
output.collect(new Text(country), new Text(sales + ",1"));
}
}
}
Đoạn mã trên hiển thị một ví dụ về triển khai bộ đếm trong Hadoop Map Giảm.
Ở đây, Quầy bán hàng là một bộ đếm được xác định bằng cách sử dụng 'enum'. Nó được dùng để đếm MISSING và KHÔNG HỢP LỆ các bản ghi đầu vào.
Trong đoạn mã, nếu 'quốc gia' trường có độ dài bằng 0 thì giá trị của nó bị thiếu và do đó bộ đếm tương ứng Bộ đếm bán hàng.MISSING được tăng lên.
Tiếp theo, nếu 'việc bán hàng' trường bắt đầu bằng một " thì bản ghi được coi là KHÔNG HỢP LỆ. Điều này được biểu thị bằng bộ đếm tăng dần Bộ đếm doanh số.INVALID.