Scikit-Learn Tutorial: Hur man installerar & Scikit-Learn Exempel
Vad är Scikit-learn?
Scikit lära är en öppen källkod Python bibliotek för maskininlärning. Den stöder toppmoderna algoritmer som KNN, XGBoost, random forest och SVM. Den är byggd ovanpå NumPy. Scikit-learn används ofta i Kaggle-tävlingar såväl som framstående teknikföretag. Det hjälper till med förbearbetning, dimensionsreduktion (parameterval), klassificering, regression, klustring och modellval.
Scikit-learn har den bästa dokumentationen av alla bibliotek med öppen källkod. Det ger dig ett interaktivt diagram på https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html.
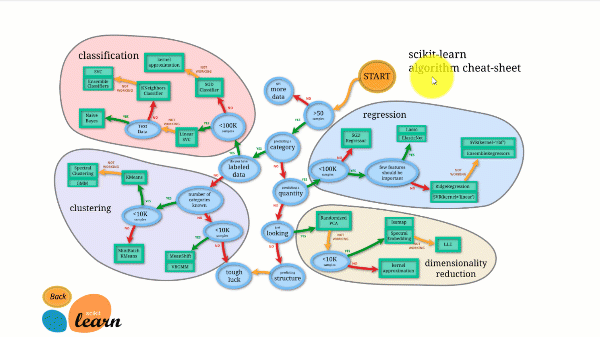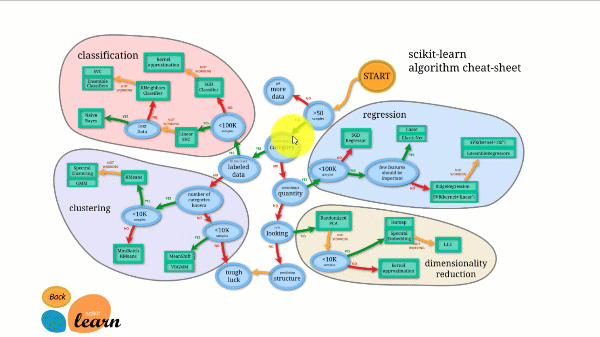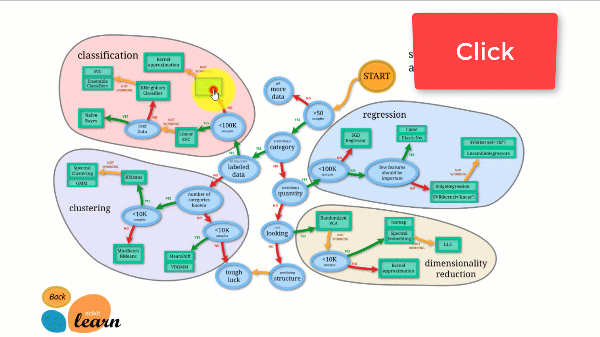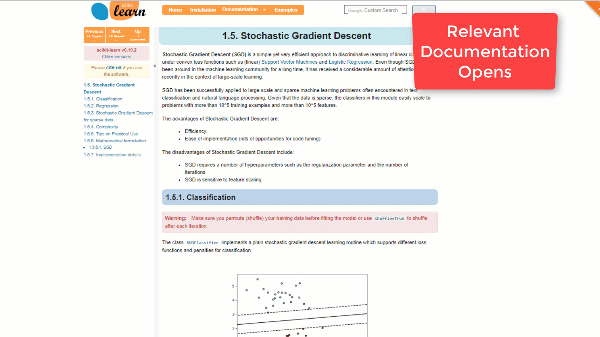
Scikit-learn är inte särskilt svårt att använda och ger utmärkta resultat. Men scikit learning stöder inte parallella beräkningar. Det är möjligt att köra en djupinlärningsalgoritm med den men det är inte en optimal lösning, speciellt om du vet hur man använder TensorFlow.
Hur man laddar ner och installerar Scikit-learn
Nu i detta Python Scikit-learn handledning, vi kommer att lära oss hur du laddar ner och installerar Scikit-learn:
Alternativet 1: AWS
scikit-learn kan användas över AWS. Snälla du hänvisa Docker-avbildningen som har scikit-learn förinstallerat.
För att använda utvecklarversionen använd kommandot i Jupyter
import sys
!{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Alternativet 2: Mac eller Windows använder Anaconda
För att lära dig om Anaconda-installation se https://www.guru99.com/download-install-tensorflow.html
Nyligen har utvecklarna av scikit släppt en utvecklingsversion som tar itu med vanliga problem med den nuvarande versionen. Vi tyckte att det var bekvämare att använda utvecklarversionen istället för den nuvarande versionen.
Hur man installerar scikit-learn med Conda Environment
Om du installerade scikit-learn med conda-miljön, följ steget för att uppdatera till version 0.20
Steg 1) Aktivera tensorflödesmiljön
source activate hello-tf
Steg 2) Ta bort scikit lean med kommandot conda
conda remove scikit-learn
Steg 3) Installera utvecklarversionen.
Installera scikit learn utvecklarversion tillsammans med nödvändiga bibliotek.
conda install -c anaconda git pip install Cython pip install h5py pip install git+git://github.com/scikit-learn/scikit-learn.git
OBS: Windows användaren måste installera Microsoft Visuell C++ 14. Du kan få det från här.
Scikit-Learn-exempel med maskininlärning
Denna Scikit-handledning är uppdelad i två delar:
- Maskininlärning med scikit-learn
- Hur du litar på din modell med LIME
Den första delen beskriver hur man bygger en pipeline, skapar en modell och justerar hyperparametrarna medan den andra delen ger toppmoderna när det gäller val av modell.
Steg 1) Importera data
Under denna Scikit-lärhandledning kommer du att använda vuxendatauppsättningen.
För en bakgrund i denna datauppsättning, se Om du är intresserad av att veta mer om den beskrivande statistiken, använd verktygen Dyk och Översikt.
Se denna handledning läs mer om dyk och översikt
Du importerar datasetet med Pandas. Observera att du måste konvertera typen av de kontinuerliga variablerna i float-format.
Denna datauppsättning innehåller åtta kategoriska variabler:
De kategoriska variablerna listas i CATE_FEATURES
- arbetsklass
- utbildning
- äktenskaplig
- ockupation
- relation
- lopp
- kön
- hemland
dessutom sex kontinuerliga variabler:
De kontinuerliga variablerna listas i CONTI_FEATURES
- ålder
- fnlwgt
- utbildningsnummer
- kapitalvinsten
- kapitalförlust
- timmar_vecka
Observera att vi fyller listan för hand så att du har en bättre uppfattning om vilka kolumner vi använder. Ett snabbare sätt att konstruera en lista med kategoriska eller kontinuerliga är att använda:
## List Categorical
CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns
print(CATE_FEATURES)
## List continuous
CONTI_FEATURES = df_train._get_numeric_data()
print(CONTI_FEATURES)
Här är koden för att importera data:
# Import dataset
import pandas as pd
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
### Define continuous list
CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week']
### Define categorical list
CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
## Prepare the data
features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False)
df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64')
df_train.describe()
| ålder | fnlwgt | utbildningsnummer | kapitalvinsten | kapitalförlust | timmar_vecka | |
|---|---|---|---|---|---|---|
| räkna | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| betyda | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| min | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Du kan kontrollera antalet unika värden för funktionerna native_country. Du kan se att endast ett hushåll kommer från Holand-Nederländerna. Detta hushåll kommer inte att ge oss någon information, men kommer genom ett fel under utbildningen.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Du kan utesluta denna oinformativa rad från datamängden
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Därefter lagrar du positionen för de kontinuerliga funktionerna i en lista. Du kommer att behöva det i nästa steg för att bygga pipelinen.
Koden nedan kommer att gå över alla kolumnnamn i CONTI_FEATURES och få dess plats (dvs. dess nummer) och sedan lägga till den i en lista som heter conti_features
## Get the column index of the categorical features
conti_features = []
for i in CONTI_FEATURES:
position = df_train.columns.get_loc(i)
conti_features.append(position)
print(conti_features)
[0, 2, 10, 4, 11, 12]
Koden nedan gör samma jobb som ovan men för den kategoriska variabeln. Koden nedan upprepar vad du har gjort tidigare, förutom med de kategoriska funktionerna.
## Get the column index of the categorical features
categorical_features = []
for i in CATE_FEATURES:
position = df_train.columns.get_loc(i)
categorical_features.append(position)
print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Du kan ta en titt på datasetet. Observera att varje kategorisk funktion är en sträng. Du kan inte mata en modell med ett strängvärde. Du måste transformera datasetet med en dummyvariabel.
df_train.head(5)
Faktum är att du måste skapa en kolumn för varje grupp i funktionen. Först kan du köra koden nedan för att beräkna det totala antalet kolumner som behövs.
print(df_train[CATE_FEATURES].nunique(),
'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9 education 16 marital 7 occupation 15 relationship 6 race 5 sex 2 native_country 41 dtype: int64 There are 101 groups in the whole dataset
Hela datasetet innehåller 101 grupper som visas ovan. Till exempel har arbetsklassens funktioner nio grupper. Du kan visualisera namnet på grupperna med följande koder
unique() returnerar de unika värdena för de kategoriska funktionerna.
for i in CATE_FEATURES:
print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Därför kommer träningsdatauppsättningen att innehålla 101 + 7 kolumner. De sista sju kolumnerna är de kontinuerliga funktionerna.
Scikit-learn kan ta hand om konverteringen. Det görs i två steg:
- Först måste du konvertera strängen till ID. Till exempel kommer State-gov att ha ID 1, Self-emp-not-inc ID 2 och så vidare. Funktionen LabelEncoder gör detta åt dig
- Transponera varje ID till en ny kolumn. Som nämnts tidigare har datasetet 101-gruppens ID. Därför kommer det att finnas 101 kolumner som fångar alla kategoriska funktioners grupper. Scikit-learn har en funktion som heter OneHotEncoder som utför denna operation
Steg 2) Skapa tåget/testsetet
Nu när datasetet är klart kan vi dela upp det 80/20.
80 procent för träningssetet och 20 procent för testsetet.
Du kan använda train_test_split. Det första argumentet är dataramen är funktionerna och det andra argumentet är etikettdataramen. Du kan ange storleken på testsetet med test_size.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_train[features],
df_train.label,
test_size = 0.2,
random_state=0)
X_train.head(5)
print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Steg 3) Bygg pipeline
Pipelinen gör det lättare att mata modellen med konsekventa data.
Tanken bakom är att lägga rådata i en "pipeline" för att utföra operationer.
Till exempel, med den aktuella datamängden, måste du standardisera de kontinuerliga variablerna och konvertera kategoridata. Observera att du kan utföra vilken operation som helst inne i pipelinen. Om du till exempel har "NA" i datamängden kan du ersätta dem med medelvärdet eller medianen. Du kan också skapa nya variabler.
Du har valet; hårdkoda de två processerna eller skapa en pipeline. Det första valet kan leda till dataläckage och skapa inkonsekvenser över tid. Ett bättre alternativ är att använda rörledningen.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Pipeledningen kommer att utföra två operationer innan den logistiska klassificeraren matas:
- Standardisera variabeln: `StandardScaler()“
- Konvertera de kategoriska funktionerna: OneHotEncoder(sparse=False)
Du kan utföra de två stegen med hjälp av make_column_transformer. Denna funktion är inte tillgänglig i den aktuella versionen av scikit-learn (0.19). Det är inte möjligt med den aktuella versionen att utföra etikettkodaren och en varmkodare i pipeline. Det är en anledning till att vi valde att använda utvecklarversionen.
make_column_transformer är lätt att använda. Du måste definiera vilka kolumner som ska tillämpas på transformationen och vilken transformation som ska användas. Till exempel, för att standardisera den kontinuerliga funktionen kan du göra:
- conti_features, StandardScaler() inuti make_column_transformer.
- conti_features: lista med den kontinuerliga variabeln
- StandardScaler: standardisera variabeln
Objektet OneHotEncoder inuti make_column_transformer kodar automatiskt etiketten.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Du kan testa om pipelinen fungerar med fit_transform. Datauppsättningen ska ha följande form: 26048, 107
preprocess.fit_transform(X_train).shape
(26048, 107)
Datatransformatorn är klar att användas. Du kan skapa pipelinen med make_pipeline. När data har transformerats kan du mata den logistiska regressionen.
model = make_pipeline(
preprocess,
LogisticRegression())
Att träna en modell med scikit-learn är trivialt. Du måste använda objektpassningen som föregås av pipeline, dvs modellen. Du kan skriva ut exaktheten med partiturobjektet från scikit-learn-biblioteket
model.fit(X_train, y_train)
print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Slutligen kan du förutsäga klasserna med predict_proba. Det returnerar sannolikheten för varje klass. Observera att det summerar till en.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Steg 4) Använda vår pipeline i en rutnätssökning
Justera hyperparametern (variabler som bestämmer nätverksstruktur som dolda enheter) kan vara tråkigt och ansträngande.
Ett sätt att utvärdera modellen kan vara att ändra storleken på träningsuppsättningen och utvärdera prestationerna.
Du kan upprepa denna metod tio gånger för att se poängen. Det är dock för mycket arbete.
Istället tillhandahåller scikit-learn en funktion för att utföra parameterjustering och korsvalidering.
Korsvalidering
Cross-Validation innebär under träningen, träningssetet glider n antal gånger i veck och utvärderar sedan modellen n tid. Till exempel, om cv är satt till 10, tränas och utvärderas träningssetet tio gånger. Vid varje omgång väljer klassificeraren slumpmässigt nio veck för att träna modellen, och den 10:e vecken är avsedd för utvärdering.
Rutnätssökning
Varje klassificerare har hyperparametrar att ställa in. Du kan prova olika värden, eller så kan du ställa in ett parameterrutnät. Om du går till den officiella webbplatsen för scikit-learn kan du se att den logistiska klassificeraren har olika parametrar att ställa in. För att göra träningen snabbare väljer du att ställa in C-parametern. Den kontrollerar för regulariseringsparametern. Det ska vara positivt. Ett litet värde ger mer vikt åt regularizern.
Du kan använda objektet GridSearchCV. Du måste skapa en ordbok som innehåller hyperparametrarna för att ställa in.
Du listar hyperparametrarna följt av de värden du vill prova. Till exempel, för att ställa in C-parametern, använder du:
- 'logisticregression__C': [0.1, 1.0, 1.0]: Parametern föregås av namnet, med gemener, på klassificeraren och två understreck.
Modellen kommer att prova fyra olika värden: 0.001, 0.01, 0.1 och 1.
Du tränar modellen med 10 veck: cv=10
from sklearn.model_selection import GridSearchCV
# Construct the parameter grid
param_grid = {
'logisticregression__C': [0.001, 0.01,0.1, 1.0],
}
Du kan träna modellen med hjälp av GridSearchCV med parametern gri och cv.
# Train the model
grid_clf = GridSearchCV(model,
param_grid,
cv=10,
iid=False)
grid_clf.fit(X_train, y_train)
PRODUKTION
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))]),
fit_params=None, iid=False, n_jobs=1,
param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
För att komma åt de bästa parametrarna använder du best_params_
grid_clf.best_params_
PRODUKTION
{'logisticregression__C': 1.0}
Efter att ha tränat modellen med fyra olika regulariseringsvärden är den optimala parametern
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
bästa logistiska regression från rutnätssökning: 0.850891
För att komma åt de förutspådda sannolikheterna:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
XGBoost-modell med scikit-learn
Låt oss prova Scikit-learn-exempel för att träna en av de bästa klassificerarna på marknaden. XGBoost är en förbättring jämfört med den slumpmässiga skogen. Klassificerarens teoretiska bakgrund utanför ramen för detta Python Scikit handledning. Tänk på att XGBoost har vunnit massor av kaggletävlingar. Med en genomsnittlig datauppsättningsstorlek kan den fungera lika bra som en djupinlärningsalgoritm eller ännu bättre.
Klassificeraren är utmanande att träna eftersom den har ett stort antal parametrar att ställa in. Du kan naturligtvis använda GridSearchCV för att välja parametern åt dig.
Låt oss istället se hur man använder ett bättre sätt att hitta de optimala parametrarna. GridSearchCV kan vara tråkigt och väldigt långt att träna om du klarar många värden. Sökutrymmet växer tillsammans med antalet parametrar. En att föredra lösningen är att använda RandomizedSearchCV. Denna metod består av att slumpmässigt välja värdena för varje hyperparameter efter varje iteration. Till exempel, om klassificeraren tränas över 1000 iterationer, utvärderas 1000 kombinationer. Det fungerar ungefär som. GridSearchCV
Du måste importera xgboost. Om biblioteket inte är installerat, använd pip3 install xgboost eller
use import sys
!{sys.executable} -m pip install xgboost
In Jupyter miljö
Härnäst
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Nästa steg i denna Scikit Python handledningen inkluderar att specificera parametrarna som ska ställas in. Du kan hänvisa till den officiella dokumentationen för att se alla parametrar som ska ställas in. För den skull Python Sklearn tutorial, du väljer bara två hyperparametrar med två värden vardera. XGBoost tar mycket tid att träna, ju fler hyperparametrar i rutnätet, desto längre tid behöver du vänta.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Du konstruerar en ny pipeline med XGBoost-klassificerare. Du väljer att definiera 600 estimatorer. Observera att n_estimators är en parameter som du kan ställa in. Ett högt värde kan leda till övermontering. Du kan prova olika värden själv men var medveten om att det kan ta timmar. Du använder standardvärdet för de andra parametrarna
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Du kan förbättra korsvalideringen med den Stratified K-Folds korsvalidatorn. Du konstruerar bara tre veck här för att snabbare beräkningen men sänka kvaliteten. Öka detta värde till 5 eller 10 hemma för att förbättra resultaten.
Du väljer att träna modellen över fyra iterationer.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Den randomiserade sökningen är redo att användas, du kan träna modellen
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False) random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min [Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Som du kan se har XGBoost ett bättre resultat än den tidigare logistiska regressionen.
print("Best parameter", random_search.best_params_)
print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Skapa DNN med MLPClassifier i scikit-learn
Slutligen kan du träna en djupinlärningsalgoritm med scikit-learn. Metoden är densamma som den andra klassificeraren. Klassificeraren finns tillgänglig på MLPClassifier.
from sklearn.neural_network import MLPClassifier
Du definierar följande algoritm för djupinlärning:
- Adam lösare
- Relu aktiveringsfunktion
- Alfa = 0.0001
- satsstorlek 150
- Två dolda lager med 100 respektive 50 neuroner
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Du kan ändra antalet lager för att förbättra modellen
model_dnn.fit(X_train, y_train)
print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN-regressionspoäng: 0.821253
LIME: Lita på din modell
Nu när du har en bra modell behöver du ett verktyg för att lita på den. Maskininlärning algoritmer, särskilt slumpmässiga skogar och neurala nätverk, är kända för att vara black-box-algoritmer. Säg annorlunda, det fungerar men ingen vet varför.
Tre forskare har tagit fram ett bra verktyg för att se hur datorn gör en förutsägelse. Tidningen heter Why Should I Trust You?
De utvecklade en algoritm som heter Lokala tolkbara modellagnostiska förklaringar (LIME).
Ta ett exempel:
ibland vet du inte om du kan lita på en maskininlärningsförutsägelse:
En läkare kan till exempel inte lita på en diagnos bara för att en dator sa det. Du måste också veta om du kan lita på modellen innan du sätter i produktion.
Föreställ dig att vi kan förstå varför någon klassificerare gör en förutsägelse även otroligt komplicerade modeller som neurala nätverk, slumpmässiga skogar eller svms med vilken kärna som helst
kommer att bli mer tillgänglig för att lita på en förutsägelse om vi kan förstå orsakerna bakom den. Från exemplet med läkaren, om modellen berättade för honom vilka symtom som är viktiga skulle du lita på den, är det också lättare att ta reda på om du inte ska lita på modellen.
Lime kan berätta vilka funktioner som påverkar klassificerarens beslut
Förberedelse av data
De är ett par saker du behöver ändra för att köra LIME med pytonorm. Först och främst måste du installera kalk i terminalen. Du kan använda pipinstallera kalk
Lime använder sig av LimeTabularExplainer-objektet för att approximera modellen lokalt. Detta objekt kräver:
- en datauppsättning i numpy-format
- Namnet på funktionerna: feature_names
- Namnet på klasserna: klassnamn
- Indexet för kolumnen med kategoriska funktioner: categorical_features
- Namnet på gruppen för varje kategoriskt inslag: categorical_names
Skapa numpy tågset
Du kan kopiera och konvertera df_train från pandor till numpy väldigt lätt
df_train.head(5) # Create numpy data df_lime = df_train df_lime.head(3)
Få klassnamnet Etiketten är tillgänglig med objektet unique(). Du borde se:
- '<=50K'
- '>50K'
# Get the class name class_names = df_lime.label.unique() class_names
array(['<=50K', '>50K'], dtype=object)
index för kolumnen för de kategoriska dragen
Du kan använda metoden du lutar innan för att få namnet på gruppen. Du kodar etiketten med LabelEncoder. Du upprepar operationen på alla kategoriska funktioner.
##
import sklearn.preprocessing as preprocessing
categorical_names = {}
for feature in CATE_FEATURES:
le = preprocessing.LabelEncoder()
le.fit(df_lime[feature])
df_lime[feature] = le.transform(df_lime[feature])
categorical_names[feature] = le.classes_
print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Nu när datauppsättningen är klar kan du konstruera den olika datauppsättningen som visas i Scikit-lärexemplen nedan. Du transformerar faktiskt data utanför pipelinen för att undvika fel med LIME. Träningsuppsättningen i LimeTabularExplainer bör vara en numpy array utan sträng. Med metoden ovan har du ett träningsdataset redan konverterat.
from sklearn.model_selection import train_test_split
X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features],
df_lime.label,
test_size = 0.2,
random_state=0)
X_train_lime.head(5)
Du kan göra pipelinen med de optimala parametrarna från XGBoost
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))])
Du får en varning. Varningen förklarar att du inte behöver skapa en etikettkodare innan pipelinen. Om du inte vill använda LIME går det bra att använda metoden från den första delen av Machine Learning with Scikit-learn-handledningen. Annars kan du fortsätta med den här metoden, skapa först en kodad datauppsättning, ställ in att hämta den heta kodaren inom pipeline.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Innan vi använder LIME i aktion, låt oss skapa en numpy array med funktionerna i fel klassificering. Du kan använda den listan senare för att få en uppfattning om vad som vilseleder klassificeraren.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1)
temp['predicted'] = model_xgb.predict(X_test_lime)
temp['wrong']= temp['label'] != temp['predicted']
temp = temp.query('wrong==True').drop('wrong', axis=1)
temp= temp.sort_values(by=['label'])
temp.shape
(826, 16)
Du skapar en lambdafunktion för att hämta förutsägelsen från modellen med den nya datan. Du kommer att behöva det snart.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float) X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Du konverterar pandas dataram till numpy array
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
import lime
import lime.lime_tabular
### Train should be label encoded not one hot encoded
explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime ,
feature_names = features,
class_names=class_names,
categorical_features=categorical_features,
categorical_names=categorical_names,
kernel_width=3)
Låt oss välja ett slumpmässigt hushåll från testsetet och se modellförutsägelsen och hur datorn gjorde sitt val.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Du kan använda förklararen med explain_instance för att kontrollera förklaringen bakom modellen
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)
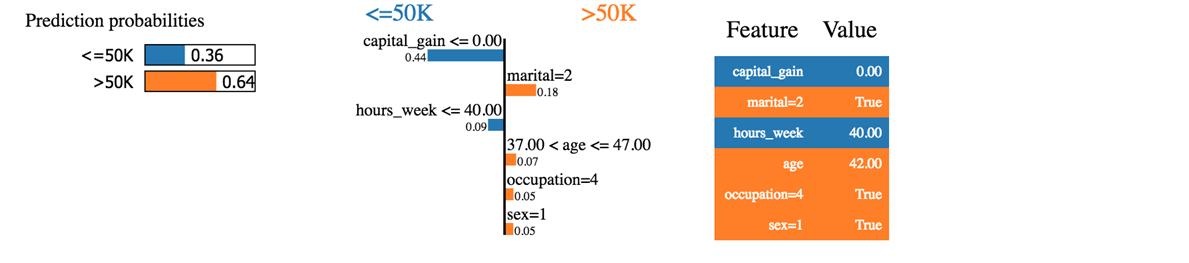
Vi kan se att klassificeraren förutspådde hushållet korrekt. Inkomsten är faktiskt över 50k.
Det första vi kan säga är att klassificeraren inte är så säker på de förutspådda sannolikheterna. Maskinen förutspår att hushållet har en inkomst över 50k med en sannolikhet på 64%. Dessa 64 % består av kapitalvinst och äktenskap. Den blå färgen bidrar negativt till den positiva klassen och den orange linjen, positivt.
Klassificeraren är förvirrad eftersom kapitalvinsten för detta hushåll är noll, medan kapitalvinsten vanligtvis är en bra prediktor för välstånd. Dessutom arbetar hushållet mindre än 40 timmar per vecka. Ålder, yrke och kön bidrar positivt till klassificeraren.
Om civilståndet var singel skulle klassificeraren ha förutspått en inkomst under 50k (0.64-0.18 = 0.46)
Vi kan försöka med ett annat hushåll som har blivit felaktigt klassificerat
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1
print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K predicted >50K Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)

Klassificeraren förutspådde en inkomst under 50k medan det inte är sant. Det här hushållet verkar konstigt. Den har ingen kapitalvinst eller kapitalförlust. Han är skild och är 60 år gammal, och det är ett utbildat folk, dvs education_num > 12. Enligt det övergripande mönstret bör detta hushåll, som klassificeraren förklarar, få en inkomst under 50k.
Du försöker leka med LIME. Du kommer att märka grova misstag från klassificeraren.
Du kan kontrollera GitHub för ägaren av biblioteket. De tillhandahåller extra dokumentation för bild- och textklassificering.
Sammanfattning
Nedan är en lista över några användbara kommandon med scikit learning version >=0.20
| skapa tåg/testdatauppsättning | praktikanter splittras |
| Bygg en pipeline | |
| välj kolumnen och tillämpa omvandlingen | göra kolumntransformator |
| typ av transformation | |
| standardisera | Standardskalare |
| min Max | MinMaxScaler |
| Normalisera | normaliserare |
| Beräkna saknat värde | tillräkna |
| Konvertera kategorisk | OneHotEncoder |
| Anpassa och transformera data | fit_transform |
| Gör rörledningen | make_pipeline |
| Grundmodell | |
| logistisk återgång | Logistisk tillbakagång |
| XGBoost | XGBClassifier |
| Neuralt nät | MLPClassifierare |
| Rutnätssökning | GridSearchCV |
| Randomiserad sökning | RandomizedSearchCV |