10 NAJLEPSZYCH danych testowych Generator Narzędzia (2026)

Czy kiedykolwiek czułeś się zablokowany, gdy narzędzia niskiej jakości spowalniały proces testowania? Wybór niewłaściwych często prowadzi do niewiarygodnych zestawów danych, czasochłonnych ręcznych poprawek, częstych błędów w przepływach pracy, a nawet niezgodności danych, które mogą zaburzyć całe projekty. Może to również powodować ryzyko braku zgodności, niespójne pokrycie testami, marnotrawstwo zasobów i niepotrzebne poprawki. Te problemy powodują frustrację i obniżają produktywność. Z drugiej strony, odpowiednie narzędzia upraszczają proces, zwiększają dokładność i oszczędzają cenny czas.
wydałem przez ponad 180 godzin starannie badając i porównując Ponad 40 narzędzi do generowania danych testowych Zanim stworzyłem ten poradnik, wybrałem 12 najskuteczniejszych opcji. Niniejsza recenzja jest poparta moimi osobistymi doświadczeniami z tymi narzędziami. W tym artykule omawiam ich kluczowe funkcje, zalety i wady oraz ceny, aby zapewnić Ci pełną jasność. Przeczytaj do końca, aby wybrać opcję najlepiej odpowiadającą Twoim potrzebom. Czytaj więcej ...
NAJLEPSZE dane testowe Generator Narzędzia: Najlepsze wybory!
| Dane testowe Generator Narzędzie | Kluczowe funkcje | Bezpłatny okres próbny / gwarancja | Połączyć |
|---|---|---|---|
| EMS Data Generator | Obsługa typu JSON, migracja bazy danych, kodowanie danych | Bezpłatna wersja próbna 30 | Dowiedz się więcej |
| Informatica TDM | Automatyczne maskowanie wrażliwych danych, Gotowe akceleratory, Raportowanie zgodności | Dostępne bezpłatne demo | Dowiedz się więcej |
| Doble | Silny nadzór, integracja API bazy danych, zarządzanie danymi | Poproś o Demo | Dowiedz się więcej |
| Broadcom EDMS | Zunifikowane skanowanie PII, skalowalne maskowanie dużych zestawów danych, obsługa baz danych NoSQL | Poproś o Demo | Dowiedz się więcej |
| SAP Test Data Migration Server | Funkcja migawki, paralelizacja wyboru danych, tworzenie aktywnej powłoki | Poproś o Demo | Dowiedz się więcej |
1) EMS Data Generator
EMS Data Generator To intuicyjne narzędzie stworzone do generowania danych syntetycznych z wielu tabel baz danych jednocześnie. Doceniłem łatwość konfiguracji losowych zestawów danych i podglądu wyników przed użyciem. Jego możliwości generowania danych oparte na schematach i szerokie wsparcie dla… typy danych, takie jak ENUM, SET i JSON uczynić go wystarczająco elastycznym, aby sprostać zróżnicowanym potrzebom testowym.
W jednym przypadku wykorzystałem EMS Data Generator do inicjowania testowych baz danych podczas projektu migracji, usprawniając ten proces bez utraty dokładności danych. Możliwość generowania sparametryzowanych zestawów danych i zapisywania ich jako skryptów SQL zapewnia płynne testowanie, co czyni je niezawodnym wyborem dla administratorów baz danych i inżynierów ds. zapewnienia jakości obsługujących zarówno małe, jak i korporacyjne obciążenia.
Cechy:
- Kodowanie danych: Ta funkcja pozwala na płynne korzystanie z różnych opcji kodowania, co jest kluczowe podczas pracy w wielu środowiskach. Obsługuje pliki Unicode, dzięki czemu bez problemu obsługiwane są nawet wielojęzyczne dane testowe. Używałem jej do płynnego zarządzania skryptami, a wyniki były zawsze spójne.
- Instalacja programu: Wygodnie pakuje wygenerowane dane testowe w pakiety instalacyjne, zapewniając, że wszystko pozostaje gotowe do natychmiastowego użycia. Uznałem to za niezwykle przydatne podczas szybkiej konfiguracji środowisk na nowych systemach. Podczas testowania tej funkcji zauważyłem, jak bardzo redukuje ona powtarzalne zadania konfiguracji.
- Migracja bazy danych: Możesz łatwo migrować między systemami baz danych, nie martwiąc się o utratę kluczowych informacji. Pomogło mi to w przeniesieniu dużych zbiorów danych z… MySQL do PostgreSQL Bezproblemowo. Zalecam dokładne sprawdzenie logów migracji w celu weryfikacji zgodności schematu przed wdrożeniem w środowisku produkcyjnym.
- Obsługa typu danych JSON: Obsługuje typy danych JSON dla popularnych baz danych, takich jak Oracle 21c, MySQL 8, Firebird 4 i PostgreSQL 16Dzięki temu jest on odporny na wyzwania przyszłości dla nowoczesnych aplikacji korzystających z przechowywania dokumentów. W jednym przypadku użyłem go do walidacji scenariuszy testowania API poprzez generowanie JSON bezpośrednio do bazy danych.
- Obsługa złożonych typów danych: Oprócz standardowych pól, narzędzie obsługuje typy SET, ENUM i GEOMETRY, co jest dużym plusem w przypadku zaawansowanych modeli baz danych. Przetestowałem to podczas modelowania zbiorów danych opartych na lokalizacji i działało idealnie, bez konieczności ręcznych korekt.
- Podgląd i edycja wygenerowanych danych: Ta funkcja umożliwia podgląd i modyfikację wygenerowanych danych przed ich sfinalizowaniem, co oszczędza czas podczas debugowania. Narzędzie pozwala zapisywać zmiany bezpośrednio w skryptach SQL, co ułatwia integrację z procesami CI/CD. Sugeruję korzystanie z kontroli wersji dla tych skryptów, aby zachować powtarzalność w kolejnych uruchomieniach testów.
ZALETY
Wady
Cennik:
Oto niektóre z oferowanych przez nas planów startowych EMS Data Generator
| EMS Data Generator dla InterBase/Firebird (Business) + 1 rok konserwacji | EMS Data Generator dla Oracle (Biznes) + 1 rok konserwacji | EMS Data Generator dla SQL Server (Business) + 1 rok konserwacji |
|---|---|---|
| $110 | $110 | $110 |
Darmowa wersja próbna: 30-dniowy okres próbny
2) Informatica Test Data Management
Informatica Test Data Management to jedno z najbardziej zaawansowanych rozwiązań, z jakimi miałem do czynienia w zakresie tworzenia syntetycznych danych i ich niezawodnej ochrony. Byłem pod wrażeniem płynności automatyzacji identyfikacji i maskowania danych w złożonych bazach danych, oszczędzając mi czasochłonnych, ręcznych kontroli. Możliwość maskowania wrażliwych danych przy jednoczesnym zachowaniu integralności schematu dała mi pewność, że spełnię wymogi zgodności bez spowalniania projektów.
Okazał się on szczególnie przydatny podczas przygotowywania sparametryzowanych zbiorów danych do zautomatyzowanych przypadków testowych, ponieważ pozwolił mi tworzyć podzbiory bez przeciążania infrastruktury. Takie podejście nie tylko poprawiło wydajność, ale także skróciło cykle testowe i obniżyło koszty. Informatica TDM sprawdza się znakomicie w obsłudze wrażliwych danych produkcyjnych, które wymagają maskowania i ponownego wykorzystania w bezpiecznych środowiskach testowych.
Cechy:
- Automatyczna identyfikacja danych: Ta funkcja szybko identyfikuje wrażliwe dane w wielu bazach danych, co znacznie ułatwia zarządzanie zgodnością i bezpieczeństwem. Funkcja ta stale stosuje maskowanie, zapewniając, że żadne surowe dane nie zostaną ujawnione podczas testów. Uznałem to za szczególnie przydatne podczas pracy z zestawami danych opieki zdrowotnej, gdzie zgodność z HIPAA była koniecznością.
- Podzbiór danych: Można tworzyć mniejsze, wartościowe podzbiory danych, które przyspieszają wykonywanie testów, jednocześnie obniżając koszty infrastruktury. Jest to niezwykle przydatne w testach regresyjnych, gdzie powtarzane przebiegi wymagają szybkiego dostępu do spójnych zestawów danych. Korzystając z tego, zauważyłem, że cykle testowe stały się bardziej wydajne, a obciążenie systemu mniejsze.
- Gotowe akceleratory: Zawiera wbudowane akceleratory maskujące dla typowych elementów danych, co pomaga zachować zgodność z przepisami bez konieczności wymyślania Ameryki na nowo. Te akceleratory oszczędzają czas i zwiększają niezawodność podczas obsługi poufnych pól, takich jak numery ubezpieczenia społecznego czy dane kart. Sugeruję zapoznanie się z opcjami dostosowywania do branżowych formatów danych, aby zmaksymalizować ich wartość.
- Monitorowanie i raportowanie: Funkcja ta zapewnia szczegółowe monitorowanie i raportowanie gotowe do audytu dla ryzyka i zgodności. Wprowadza zespoły zarządzające bezpośrednio do procesu, co pomaga dostosować zapewnienie jakości do polityk danych przedsiębiorstwa. Zalecałbym planowanie automatycznych raportów w procesach CI/CD, aby kontrole zgodności stały się częścią codziennych testów, a nie czymś na ostatnią chwilę.
- Jednolite zarządzanie danymi: Zapewnia spójność polityk w całym przedsiębiorstwie, zmniejszając ryzyko braku zgodności. Widziałem, jak pomaga to dużym organizacjom unikać silosów, jednocześnie utrzymując dokładne i wiarygodne dane.
- Zautomatyzowana inteligencja danych: Wykorzystuje automatyzację opartą na sztucznej inteligencji, aby zapewnić ciągły wgląd w wykorzystanie danych, ich pochodzenie i jakość. To nie tylko poprawia przejrzystość, ale także przyspiesza podejmowanie decyzji. Podczas testów zauważyłem, że znacząco zmniejsza to ręczny nakład pracy związany ze śledzeniem pochodzenia i transformacji danych.
ZALETY
Wady
Cennik:
- Cena: Możesz poprosić dział sprzedaży o wycenę
- Darmowa wersja próbna: Otrzymasz darmową wersję demonstracyjną
3) Podwójny
Doble wyróżnia się jako praktyczny wybór dla organizacji potrzebujących ustrukturyzowanego zarządzania danymi testowymi. Kiedy użyłem go do uporządkowania dużych zestawów losowych danych w różnych działach, zauważyłem, jak bardzo usprawniło to testowanie. Narzędzie ułatwia czyszczenie, konwersję i kategoryzację danych, zapewniając dokładność podczas obsługi zróżnicowanych planów testów. Możliwość integracji z interfejsami API i narzędziami Business Intelligence wnosi realną wartość dodaną do codziennych procesów testowych.
Doceniłem to, jak usprawniło to testy na poziomie terenowym poprzez konsolidację wyników w logicznych folderach, co ograniczyło zamieszanie związane z rozproszonymi zestawami danych. Mając doświadczenie z jego niezawodnością w zarządzaniu zamaskowanymi danymi produkcyjnymi, powiedziałbym, że Doble jest szczególnie przydatny dla zespołów, które priorytetowo traktują spójność i zarządzanie danymi, jednocześnie redukując narzut związany z ręczną organizacją.
Cechy:
- Zarządzanie danymi: Ta funkcja pozwala na spójne zarządzanie różnymi typami danych testowych, takimi jak SFRA i DTA. Pomaga utrzymać produktywność w różnych projektach i obsługuje generowanie danych w oparciu o schematy, gdy jest to potrzebne. Osobiście korzystałem z niej do tworzenia uporządkowanych, wielokrotnego użytku szablonów, które ograniczają ręczną pracę.
- Silny nadzór: Zapewnia nadzór w celu egzekwowania rygorystycznych standardów zarządzania danymi. To nie tylko redukuje zbędne procesy ale także usprawnia przepływy pracy zgodne z przepisami. Podczas testów zauważyłem, jak dobrze integruje się z procesami DevOps klasy korporacyjnej, ułatwiając wykrywanie nieefektywności, zanim się nasilą.
- Zarządzanie danymi: Ta funkcja zapewnia logiczne przechowywanie i tworzenie kopii zapasowych, zapewniając uporządkowaną i dostępną strukturę danych testowych. Zwiększa niezawodność scenariuszy testów wydajnościowych i regresyjnych. Zalecam korzystanie z tej funkcji podczas pracy z maskowanymi danymi produkcyjnymi, ponieważ usprawnia ona audyt, zachowując jednocześnie bezpieczeństwo.
- API bazy danych: Interfejs API bazy danych zapewnia elastyczną warstwę usług do pobierania danych testowych i wyników analitycznych, takich jak wyniki FRANK™. Obsługuje integrację z narzędziami BI, umożliwiając tworzenie gotowych do automatyzacji potoków raportowania. Sugeruję korzystanie z niego do obsługi CI/CD, gdzie analiza danych musi być stale dostępna.
- Standaryzowane procesy: Ta funkcja koncentruje się na eliminacji ręcznych i powtarzalnych procesów poprzez standaryzację sposobu gromadzenia i przechowywania danych. Zapewnia kompatybilność międzyplatformową i zmniejsza ryzyko fragmentacji przepływów pracy. Widziałem, jak oszczędzało to godziny podczas walidacji oprogramowania na dużą skalę, gdzie pokrycie skrajnych przypadków miało kluczowe znaczenie.
- Zasoby wiedzy i szkolenia: Doble zapewnia dostęp do ustrukturyzowanych przewodników i szkoleń, które pomagają zespołom wdrażać najlepsze praktyki. Gwarantuje to spójność w sposobie zarządzania danymi testowymi Między działami. Dodatkowo zauważyłem, że dostosowany materiał edukacyjny przyspiesza wdrażanie, nawet w środowiskach sprzyjających zwinności.
ZALETY
Wady
Cennik:
- Cena: Możesz poprosić dział sprzedaży o wycenę
- Darmowa wersja próbna: Poproś o demo
4) Broadcom EDMS
Broadcom EDMS to potężna platforma do generowania danych testowych, którą uznałem za szczególnie skuteczną w budowaniu zestawów danych opartych na schematach i regułach. Podobało mi się, że umożliwiała wyodrębnianie i ponowne wykorzystywanie danych biznesowych, a jednocześnie stosowanie reguł maskowania, które chroniły poufne informacje. Funkcje podzbiorów – takie jak usuwanie, wstawianie i obcinanie – zapewniały precyzyjną kontrolę nad tworzeniem zestawów danych, co zwiększało elastyczność testów.
W jednym ze scenariuszy użyłem go do wygenerowania losowych zestawów danych do testowania API, zapewniając uwzględnienie przypadków brzegowych bez ujawniania danych produkcyjnych. Szeroko zakrojone wykrywanie poufnych źródeł w połączeniu z opcjami harmonogramowania ułatwiło zachowanie zgodności, przyspieszając jednocześnie automatyczne przypadki testowe. Broadcom EDMS wyróżnia się łączeniem najwyższego poziomu bezpieczeństwa z elastycznością przygotowywania danych.
Cechy:
- Asystent danych Plus: Ta funkcja tworzy realistyczne, oparte na schematach dane syntetyczne za pomocą algorytmów sterowanych regułami, które naśladują logikę produkcji bez ujawniania poufnych informacji. Widziałem, jak przyspiesza ona gotowość przypadków testowych, umożliwiając testerom symulowanie rzadkich błędów bez czekania na dane produkcyjne.
- Zunifikowany proces skanowania, maskowania i audytu danych osobowych: Lokalizuje, klasyfikuje i bezpiecznie przetwarza dane osobowe w ramach płynnego procesu – skanuje, maskuje, a następnie weryfikuje zgodność. Zapewnia zgodność z przepisami o ochronie prywatności, takimi jak RODO/HIPAA, dzięki czemu dane są zgodne z przepisami i bezpieczne przed użyciem testowym.
- Skalowalne maskowanie dużych zestawów danych: Obsługuje maskowanie dużych wolumenów danych przy minimalnym nakładzie pracy związanym z konfiguracją. Umożliwia poziome skalowanie zadań maskowania (np. w klastrach Kubernetes), automatycznie przydzielając zasoby w zależności od wolumenu, a następnie usuwając je po użyciu.
- Wsparcie dla baz danych NoSQL: Teraz możesz zastosować praktyki zarządzania danymi testowymi (maskowanie, generowanie syntetyczne itp.) NoSQL platformy takie jak MongoDB, Cassandra, BigQueryTo rozszerza zakres zastosowania poza systemy relacyjne. Używałem tego w środowiskach, w których mieszane bazy danych relacyjnych i dokumentowych powodowały opóźnienia. Dzięki temu jedno narzędzie zapewnia zarówno lepszą powtarzalność, jak i łatwość integracji.
- Portal samoobsługowy i rezerwacja danych: Testerzy mogą korzystać z portalu, aby zamawiać i rezerwować określone zestawy danych (np. operacje wyszukiwania i rezerwowania) bez kopiowania całych zestawów produkcyjnych. Pomaga to skrócić czas realizacji i uniknąć niepotrzebnego duplikowania danych.
- Integracja CI/CD i DevOps Pipeline: Narzędzie obsługuje osadzanie dostarczania danych testowych, generowania danych syntetycznych, maskowania i operacji na podzbiorach danych w procesach CI/CD. Przesuwa TDM „w lewo” – tj. do faz projektowania i kompilacji – dzięki czemu cykle testowania są krótsze, a testowanie nie stanowi już wąskiego gardła.
ZALETY
Wady
Cennik:
- Cena: Możesz skontaktować się z działem sprzedaży, aby uzyskać wycenę
- Darmowa wersja próbna: Prosisz o demo
5) SAP Test Data Migration Server
SAP Test Data Migration Server jest niezawodnym rozwiązaniem do generowania i migracji realistycznych SAP Dane testowe w różnych systemach. Uznałem to za szczególnie istotne w scenariuszach testowych na dużą skalę, ponieważ usprawniło moje przepływy pracy, zapewniając jednocześnie zgodność ze standardami prywatności danych. Wbudowana funkcja szyfrowania poufnych informacji dała mi pewność, że dane testowe bezpiecznie odzwierciedlają dane produkcyjne.
W praktyce wykorzystałem go do replikacji złożonych zestawów danych w środowiskach szkoleniowych, co drastycznie skróciło czas konfiguracji i koszty infrastruktury. Funkcje takie jak paralelizacja selekcji danych i aktywne tworzenie powłoki sprawiły, że proces był bardzo wydajny, umożliwiając mi przeprowadzanie zautomatyzowanych przypadków testowych z maskowanymi danymi produkcyjnymi oraz symulację kompleksowych testów w rekordowo krótkim czasie.
Cechy:
- Funkcja migawki: Ta funkcja umożliwia utworzenie logicznej migawki wolumenów danych, zapewniając wiarygodny obraz stanu konkretnego magazynu. Pomaga w odtwarzaniu spójnych środowisk do testowania i trenowania bez duplikowania całych zestawów danych. Użyłem jej do usprawnienia testów regresyjnych i naprawdę oszczędza czas.
- Paralelizacja wyboru danych: To pozwala ci uruchamiaj wiele zadań wsadowych jednocześnie podczas wyboru danych. Przyspiesza to proces migracji i zapewnia większą wydajność tworzenia danych testowych na dużą skalę. Zalecałbym stosowanie mniejszych podziałów zadań podczas obsługi złożonych SAP krajobrazy, aby uniknąć wąskich gardeł.
- Tworzenie ról użytkowników: Można zdefiniować dostęp oparty na rolach w całym drzewie procesu migracji danych. Dzięki temu testerzy i deweloperzy widzą tylko te dane, których potrzebują, co zwiększa bezpieczeństwo i zgodność z przepisami. Podczas korzystania z tej funkcji zauważyłem, jak upraszcza ona audyt w cyklach testowych.
- Tworzenie aktywnej powłoki: Funkcjonalność ta umożliwia kopiowanie danych aplikacji z jednej SAP System do innego systemu za pomocą procesu kopiowania systemu rdzeniowego. Jest to niezwykle przydatne do szybkiej konfiguracji systemów szkoleniowych. Przetestowałem to w projekcie, w którym klient potrzebował wielu środowisk testowych, i radykalnie skróciło to czas provisioningu.
- Mieszanie danych: Narzędzie zawiera zaawansowane opcje szyfrowania danych, które umożliwiają anonimizację poufnych danych biznesowych podczas transferu. Pomaga organizacjom zachowaj zgodność z RODO i innymi przepisami dotyczącymi prywatnościZauważysz, jak elastyczne są zasady szyfrowania, zwłaszcza gdy dostosowujesz je do danych finansowych i kadrowych.
- Migracja danych między systemami: Obsługuje przesyłanie danych testowych między niepołączonymi centrami danych, co czyni go niezwykle cennym dla globalnych przedsiębiorstw. Funkcja ta jest szczególnie przydatna dla zespołów pracujących nad ciągłą integracją i procesami DevOps, w których środowiska są rozproszone po całym świecie. Sugeruję planowanie migracji w okresach niskiego ruchu, aby zapewnić optymalną wydajność.
ZALETY
Wady
Cennik:
- Cena: Możesz skontaktować się z działem sprzedaży, aby uzyskać wycenę
- Darmowa wersja próbna: Prosisz o demo
6) Upscene – Advanced Data Generator
Upscene – Advanced Data Generator Doskonale radzi sobie z tworzeniem realistycznych, opartych na schematach zestawów danych testowych dla baz danych. Byłem szczególnie pod wrażeniem intuicyjności interfejsu podczas projektowania modeli danych i egzekwowania ograniczeń w powiązanych tabelach. W ciągu kilku minut mogłem wygenerować losowe zestawy danych, które wydawały się wystarczająco autentyczne, aby zweryfikować wydajność zapytań i przeprowadzić testy obciążeniowe mojej bazy danych.
Podczas pracy nad projektem, który wymagał testów wytrzymałościowych przed wdrożeniem, Upscene mi pomógł generować sparametryzowane zestawy danych Dostosowane do konkretnych scenariuszy bez konieczności ręcznego wysiłku. Obsługa wielu typów danych i makr zapewniła mi pełną elastyczność w budowaniu syntetycznych procesów tworzenia danych, co ostatecznie poprawiło pokrycie testami i zautomatyzowało procesy walidacji.
Cechy:
- Interfejs obsługujący HiDPI: Ta aktualizacja poprawia dostępność dzięki dużym ikonom na pasku narzędzi, skalowanym czcionkom i wyraźniejszej grafice, co znacznie ułatwia korzystanie z aplikacji na nowoczesnych wyświetlaczach o wysokiej rozdzielczości. Zauważysz, że nawet długie sesje testowe są płynniejsze dzięki mniejszemu obciążeniu podczas nawigacji po zbiorach danych.
- Rozszerzone biblioteki danych: Zawiera teraz nazwy, ulice i dane o miastach w języku francuskim, niemieckim i włoskim, co poszerza możliwości symulowania globalnych scenariuszy użytkowników. Jest to szczególnie cenne, jeśli oprogramowanie wymaga zgodnych z przepisami zestawów danych dla rynków wielojęzycznych. Użyłem tych bibliotek do walidacji formularzy w międzyregionalnej aplikacji HR i okazało się to bezproblemowe.
- Zaawansowana logika generowania danych: Teraz możesz generować wartości w wielu przejściach, stosować makra w celu tworzenia złożonych wynikówi tworzyć dane numeryczne, które odwołują się do poprzednich wpisów. Podczas testowania tej funkcji stwierdziłem, że doskonale sprawdza się ona w symulowaniu statystycznych zestawów danych w scenariuszach testów wydajnościowych, zwłaszcza podczas tworzenia symulacji opartych na trendach.
- Automatyczne kopie zapasowe: Każdy projekt korzysta teraz z funkcji automatycznego tworzenia kopii zapasowych, dzięki której nigdy nie utracisz konfiguracji ani skryptów danych testowych. To drobny dodatek, ale dzięki temu zabezpieczeniu udało mi się kiedyś przywrócić nadpisaną konfigurację schematu w ciągu kilku minut – zaoszczędziło to wielu godzin pracy.
- Generuj sensowne dane: Ta funkcja pomaga tworzyć realistyczne, gotowe do prezentacji dane testowe, unikając bezsensownego tekstu, często występującego podczas testów. Zawiera bogate biblioteki danych i obsługuje wiele języków, dzięki czemu można generować nazwy, adresy i inne pola w różnych lokalizacjach. Uznałem to za szczególnie przydatne podczas przygotowywania środowisk demonstracyjnych dla klientów, którzy potrzebowali zlokalizowanych zestawów danych.
- Złożone dane wielotabelowe: Ta funkcja umożliwia generowanie danych testowych w wielu powiązanych ze sobą tabelach, co pozwala zaoszczędzić sporo czasu podczas walidacji relacyjnych baz danych. Zapewnia spójność powiązanych rekordów, zwiększając niezawodność testów regresyjnych i walidacji schematu. Przekonałem się również, jak płynnie zachowuje relacje kluczy obcych, eliminując ryzyko niedopasowania rekordów.
ZALETY
Wady
Cennik:
Oto niektóre plany oferowane przez Upscene:
| Zaawansowane dane Generator dla dostępu | Zaawansowane dane Generator dla MySQL | Zaawansowane dane Generator dla Firebird |
|---|---|---|
| €119 | €119 | €119 |
Darmowa wersja próbna: Możesz pobrać darmową wersję
7) Mockaroo
Mockaroo to potężne i elastyczne narzędzie do generowania danych pozorowanych, które szybko stało się jednym z moich ulubionych. Doceniłem prostotę generowania tysięcy wierszy w formatach takich jak JSON, CSV, Excel czy SQL, idealnie dopasowanych do moich potrzeb w zakresie generowania danych testowych. Bogaty zestaw bibliotek danych pozwolił mi skonfigurować generowanie oparte na schematach z precyzyjną kontrolą nad polami takimi jak adresy, numery telefonów i współrzędne geograficzne.
W jednym przypadku użyłem go do zasilenia bazy danych losowymi zestawami danych do testów API, co pomogło mi odkryć nieprzewidziane przypadki brzegowe. Umożliwiając mi projektowanie pozorowanych interfejsów API i definiowanie niestandardowych odpowiedzi, Mockaroo umożliwiło mi bezproblemowe symulowanie rzeczywistych scenariuszy, zachowując jednocześnie kontrolę nad zmiennością i warunkami wystąpienia błędów.
Cechy:
- Biblioteki drwiące: Zawiera rozbudowane biblioteki obsługujące wiele języków programowania i platform. Dzięki temu integracja z procesami CI/CD lub frameworkami automatyzacji jest praktycznie bezproblemowa. Polecam zapoznać się z opcjami opartymi na API, ponieważ pozwalają one na tworzenie sparametryzowanych zestawów danych, które można ponownie wykorzystać w różnych cyklach testów regresyjnych. Ta elastyczność może zaoszczędzić wiele godzin powtarzalnej konfiguracji.
- Dane z losowych testów: Możesz natychmiast generować losowe zestawy danych w Formaty CSV, SQL, JSON lub ExcelUżyłem tej funkcji podczas projektu testów wydajnościowych i znacząco ograniczyła ona nakład pracy ręcznej, jednocześnie zachowując różnorodność danych. Podczas korzystania z tej funkcji zauważyłem, że dostosowanie ustawień losowości dla przypadków brzegowych – takich jak nietypowo długie ciągi znaków – pomaga wcześnie wykryć ukryte błędy.
- Projektowanie schematów niestandardowych: Ta funkcja umożliwia tworzenie reguł generowania opartych na schematach, dzięki czemu dane odzwierciedlają rzeczywiste struktury produkcyjne. Jest to szczególnie przydatne do seedowania baz danych w sprintach Agile. Pamiętam, jak tworzyłem schemat dla projektu z branży opieki zdrowotnej, który sprawił, że walidacje były bardziej zgodne z wrażliwymi modelami danych bez ujawniania rzeczywistych rekordów.
- Symulacja API: Możesz szybko projektować pozorowane interfejsy API, definiując adresy URL, odpowiedzi i stany błędów. To zbawienne rozwiązanie dla zespołów oczekujących na usługi backendowe, ponieważ zapewnia płynny przebieg prac nad frontendem. Zalecam logiczne wersjonowanie pozorowanych punktów końcowych – zwłaszcza gdy wielu programistów testuje jednocześnie – aby uniknąć konfliktów i nieporozumień.
- Skalowalność i wolumen: Mockaroo obsługuje generowanie dane o dużej objętości do testów na dużą skalęUżyłem go kiedyś do symulacji ponad miliona wierszy w teście regresji finansowej i zachował zarówno szybkość, jak i niezawodność. Jest gotowy do automatyzacji, co oznacza, że można go osadzić w przepływach ciągłej integracji i skalować wraz ze zmieniającymi się wymaganiami projektu.
- Opcje eksportu danych: Narzędzie umożliwia eksport w wielu formatach, zapewniając kompatybilność między systemami i frameworkami testowymi. Przekonasz się, jak wygodne staje się to podczas przełączania się między testami opartymi na SQL a przypadkami testowymi opartymi na Excelu. Narzędzie pozwala płynnie obsługiwać scenariusze międzyplatformowe, co jest szczególnie cenne w środowiskach QA klasy korporacyjnej.
ZALETY
Wady
Cennik:
Oto roczne plany Mockaroo:
| Srebrny | Złoto | Enterprise |
|---|---|---|
| $60 | $500 | $7500 |
Darmowa wersja próbna: Otrzymujesz bezpłatny plan z 1000 wierszami na plik
Połączyć: https://mockaroo.com/
8) GenerateData
GenerateData jest generatorem danych testowych typu open source zbudowanym w PHP, MySQL, JavaSkrypt ułatwiający generowanie dużych wolumenów realistycznych, opartych na schematach zestawów danych do testów. Był szczególnie przydatny, gdy potrzebowałem szybkiego, syntetycznego tworzenia danych w wielu formatach, od CSV do SQL, bez naruszania struktury i integralności. Jego rozszerzalność poprzez niestandardowe typy danych pozwala programistom precyzyjnie dostosowywać zestawy danych do wymagań projektu.
Kiedy użyłem go do zasilenia bazy danych dla zautomatyzowanych przypadków testowych, elastyczność definiowania generowania opartego na regułach i dodawania powiązanych wtyczek dla kodów pocztowych i regionów zaoszczędziła godziny ręcznej konfiguracji. Dzięki prostemu interfejsowi i frameworkowi na licencji GNU, GenerateData okazał się niezawodnym towarzyszem losowych zestawów danych i generowania danych parametrycznych podczas iteracyjnych cykli testowania.
Cechy:
- Połączone dane: Umożliwia generowanie wartości specyficznych dla lokalizacji, takich jak miasta, regiony i kody pocztowe, logicznie ze sobą powiązanych. To połączone podejście zapewnia powtarzalność i realistyczne relacje między zestawami danych. Sugeruję korzystanie z tego rozwiązania podczas testowania zgodnych z przepisami przepływów pracy dotyczących danych, ponieważ bardzo dokładnie odzwierciedla ono warunki panujące w środowisku produkcyjnym.
- Elastyczność licencji GNU: Będąc w pełni Na licencji GNUTo narzędzie zapewnia swobodę personalizacji i dystrybucji bez ograniczeń. Jest szczególnie przydatne dla zespołów, które potrzebują skalowalnego rozwiązania klasy enterprise, bez uzależnienia od dostawcy. Zintegrowałem je z procesem CI/CD, gdzie narzędzia gotowe do automatyzacji były kluczowe, co znacząco zwiększyło produktywność.
- Generowanie wolumenu danych: Funkcja ta umożliwia tworzenie dużych zestawów danych w wielu formatach, takich jak: CSV, JSON lub SQLMożna łatwo zasilić bazy danych do testów regresyjnych lub symulować testy API na dużą skalę. Korzystając z tego, zauważyłem, że generowanie dużych zestawów danych w partiach może zmniejszyć zużycie pamięci i poprawić wydajność.
- Obsługa wtyczek do rozbudowy: GenerateData Obsługuje dodawanie wtyczek, co pozwala rozszerzyć funkcjonalność o nowe zestawy danych krajowych lub opcje generowania danych oparte na regułach. Zwiększa elastyczność i zapewnia przyszłościowe rozwiązania w przypadku unikalnych zastosowań. Praktycznym scenariuszem jest tworzenie środowisk testowych wymagających dostosowanej anonimizacji danych dla zespołów globalnych.
- Eksport wieloformatowy: Możesz natychmiast generować dane testowe w ponad dziesięciu formatach wyjściowych, w tym JSON, XML, SQL, CSV, a nawet w fragmentach kodu. Python, C# lub Ruby. Zapewnia to bezproblemową integrację z różnymi procesami DevOps. Zalecam najpierw wyeksportować małe partie podczas konfiguracji, aby walidacja schematu przebiegała sprawnie.
- Zapisywanie i ponowne wykorzystywanie zbioru danych: Dostępna jest również opcja zapisywania zestawów danych na koncie użytkownika, co ułatwia ponowne wykorzystywanie konfiguracji w wielu projektach. Zmniejsza to nakład pracy ręcznej i zapewnia powtarzalność. Korzystałem z tej opcji w środowiskach ciągłej integracji, aby zachować spójność przebiegów testów w czasie.
ZALETY
Wady
Cennik:
To projekt typu open source
9) Delphix
Delphix to potężna platforma do generowania i zarządzania danymi testowymi, zapewniająca zamaskowane dane produkcyjne i bezpieczne syntetyczne zestawy danych, co przyspiesza rozwój. Najbardziej utkwiła mi w pamięci możliwość wirtualizacji środowisk danych — umożliwiająca dodawanie zakładek, resetowanie i udostępnianie wersji bez zakłóceń. Szczególnie istotne okazało się to podczas pracy nad równoległymi, zautomatyzowanymi przypadkami testowymi, gdzie… zgodność z RODO i CCPA nie podlegało negocjacjom.
W jednym scenariuszu użyłem Delphix do dostarczania podzbiorów danych na żądanie, zapewniając szybszą integrację CI/CD przy jednoczesnym zachowaniu poufnych informacji dzięki predefiniowanym algorytmom maskowania. Rozszerzalna obsługa API i płynna synchronizacja z różnymi środowiskami testowymi uczyniły z niego fundament niezawodnego seedingu baz danych, sparametryzowanych zestawów danych i ciągłego dostarczania danych.
Cechy:
- Błąd udostępniania zakładek: Ta funkcja ułatwia udostępnianie programistom migawek problematycznych środowisk, co znacznie skraca czas debugowania. Korzystałem z niej podczas testów regresyjnych i pomogła mojemu zespołowi szybko lokalizować powtarzające się problemy. Sugeruję logiczne nazywanie zakładek, aby każdy mógł bez problemu śledzić błędy.
- Zgodność danych: Zapewnia spójną anonimizację poufnych informacji w milionach wierszy, zgodnie z RODO, CCPA i innymi przepisami. Używając go w projekcie finansowym, zauważyłem, jak płynne było maskowanie bez naruszania relacji schematów. Zauważysz, że raportowanie zgodności staje się płynniejsze po zintegrowaniu z procesami audytu.
- Rozszerzalny i otwarty: Delphix oferuje elastyczne opcje dzięki interfejsowi użytkownika, interfejsowi wiersza poleceń i interfejsom API, umożliwiając zespołom zarządzanie operacjami na danych w różnych konfiguracjach. Uważam, że integracja z procesami CI/CD Szczególnie przydatna do ciągłego testowania. Funkcja ta obsługuje również połączenia z wieloma narzędziami do monitorowania i zarządzania konfiguracją, co zwiększa zwinność w procesach DevOps.
- Kontrola wersji i resetowanie: Podobało mi się Delphix Pozwala mi dodawać zakładki i resetować zestawy danych do dowolnego wcześniejszego stanu, co poprawia powtarzalność podczas testów wydajnościowych. Używałem go podczas przywracania do czystej linii bazowej przed uruchomieniem testów pokrycia przypadków brzegowych. Oszczędza to godziny pracy i zapewnia spójność scenariuszy testowych.
- Dane Syncronizacja: Można stale utrzymywać zgodność środowisk testowych z zestawami danych zbliżonymi do produkcyjnych, bez zakłóceń. Podczas projektu w służbie zdrowia zaobserwowałem, jak zsynchronizowane dane zmniejszają rozbieżności między usługami pozorowanymi a testowanym systemem. Ta spójność poprawia powtarzalność i buduje zaufanie do wyników testów.
- Maskowanie niestandardowe i predefiniowane Algorithms: Oferuje solidne techniki maskowania, które chronią wrażliwe pola, jednocześnie zachowując użyteczność. Zalecałbym eksperymentowanie z maskowaniem sterowanym regułami w środowiskach testowych przed zastosowaniem go do danych produkcyjnych, ponieważ pomaga to wcześnie identyfikować wszelkie anomalie. Równowaga między bezpieczeństwem a funkcjonalnością to jedna z jego najmocniejszych stron.
ZALETY
Wady
Cennik:
- Cena: Aby otrzymać wycenę, skontaktuj się ze sprzedażą.
- Darmowa wersja próbna: Użytkownicy mogą poprosić o wersję demonstracyjną
10) Original Software
Original Software zapewnia kompleksowe podejście do generowania danych testowych, wspierając oba testowanie na poziomie bazy danych i interfejsu użytkownikaDoceniłem jego zdolność do zachowania integralności referencyjnej podczas tworzenia podzbiorów syntetycznych danych testowych, co zapewniało, że losowe zbiory danych odzwierciedlały rzeczywiste warunki. Możliwość integracji narzędzia z innymi frameworkami testowymi poprawiła ogólną jakość i zmniejszyła redundancję w moich przepływach pracy.
Podczas pracy nad scenariuszem obejmującym testowanie API, polegałem na szczegółowym śledzeniu wstawień, aktualizacji i usunięć, aby walidować stany pośrednie podczas przetwarzania wsadowego. To oparte na regułach generowanie danych, w połączeniu z silnymi metodami zaciemniania danych wrażliwych, dało mi pewność, że zarówno bezpieczeństwo, jak i wydajność zostały zachowane. To doskonały wybór dla zespołów ceniących elastyczne tworzenie danych syntetycznych z automatyczną walidacją przypadków testowych.
Cechy:
- Maskowanie danych pionowych: Ta funkcja pozwala maskować wrażliwe dane w zbiorach danych produkcyjnych lub testowych, zachowując poufność przy jednoczesnym zachowaniu realistycznych wartości. Obsługuje selektywne maskowanie według kolumny lub pola („pionowe”), dzięki czemu ukrywane są tylko te fragmenty, które są naprawdę wrażliwe. Korzystałem z podobnych narzędzi i odkryłem, że konfigurowalne reguły maskowania (np. zachowanie formatu, długości i typu) pozwalają uniknąć przeróbek.
- Przywracanie punktu kontrolnego: To narzędzie umożliwia tworzenie migawek bazy danych i przywracanie ich w razie potrzeby, zapewniając precyzyjną kontrolę podczas testów. Zmniejsza zależność od administratorów baz danych i umożliwia powtarzalność cykli regresji. Kiedyś udało mi się przywrócić całe schematy w ciągu kilku minut po nieudanych testach migracji, co pozwoliło zaoszczędzić sporo czasu.
- Walidacja danych Operatory: Ta funkcja przynosi ponad 20 operatorów do kontroli, np. obecności, wykrywanie zmienionych wartości, wartości oczekiwane i rzeczywiste oraz walidację międzyplikową. Zapewnia elastyczność w testowaniu poprawności w złożonych scenariuszach. Podczas testów zauważyłem, że połączenie walidacji SUM i EXISTS zapewnia zachowanie integralności relacji podczas aktualizacji.
- Walidacja baz danych i aplikacji podczas testów: Dzięki tej funkcji można walidować nie tylko dane testowe, ale także zmiany w bazie danych wyzwalane przez logikę aplikacji, takie jak wyzwalacze, aktualizacje i usunięcia. Jest to niezwykle skuteczne rozwiązanie w testach regresyjnych, zapewniające zgodność i niezawodność procesów w dół strumienia.
- Śledzenie wymagań i ich zakres: Ta funkcja łączy przypadki testowe bezpośrednio z wymaganiami i mapuje wyniki testów na nie, wskazując luki w pokryciu. Zapewnia transparentność widoczności między zespołami i jest szczególnie cenna podczas audytów.
- Ręczne i automatyczne wykonywanie testów z integracją CI/CD: Funkcja ta umożliwia ręczne lub automatyczne wykonywanie testów, dzięki czemu można ją dostosować do testów eksploracyjnych lub regresyjnych. Bezproblemowo integruje się z procesami CI/CD, rejestrując wyniki i statusy wykonania.
ZALETY
Wady
Cennik:
- Cena: Aby otrzymać wycenę, skontaktuj się ze sprzedażą.
- Darmowa wersja próbna: Użytkownicy mogą poprosić o wersję demonstracyjną
Tabela porównawcza
Oto krótka tabela porównawcza powyższych narzędzi:
| Cecha | EMS Data Generator | Informatica TDM | Doble | Broadcom |
|---|---|---|---|---|
| Generowanie danych syntetycznych | ✔️ | ✔️ | ❌ | ✔️ |
| Maskowanie/anonimizacja danych | ograniczony | ✔️ | ❌ | ✔️ |
| Podzbiór danych / próbkowanie | ✔️ | ✔️ | ❌ | ✔️ |
| Referencyjne Integrity Ochrona | ✔️ | ✔️ | ✔️ | ✔️ |
| CI/CD / Integracja automatyzacji | ograniczony | ✔️ | ✔️ | ✔️ |
| Biblioteka danych testowych / Wersjonowanie | ograniczony | ✔️ | ✔️ | ograniczony |
| Wirtualizacja / Podróże w czasie | ✔️ | ograniczony | ❌ | ograniczony |
| Samoobsługa / Łatwość użytkowania | ✔️ | ✔️ | ✔️ | ograniczony |
Czym są dane testowe Generator?
Dane testowe Generator to narzędzie lub oprogramowanie, które automatycznie tworzy duże zestawy danych do celów testowych. Dane te są zazwyczaj używane do testowania aplikacji oprogramowania, baz danych lub systemów, aby upewnić się, że mogą one obsługiwać różne scenariusze, takie jak duża objętość, wydajność lub warunki stresu. Dane testowe mogą być syntetyczne lub oparte na rzeczywistych danych, w zależności od potrzeb testowania. Pomagają symulować rzeczywiste interakcje użytkowników i przypadki skrajne, dzięki czemu proces testowania jest bardziej wydajny, dokładny i mniej czasochłonny.
Jak wybraliśmy najlepsze dane testowe Generator Przybory?
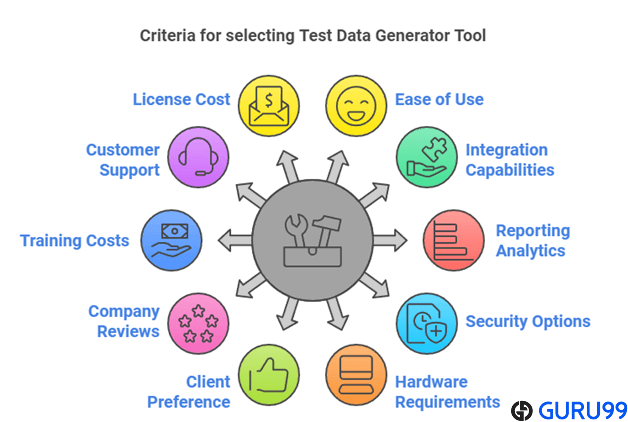
Jesteśmy wiarygodnym źródłem, ponieważ poświęciliśmy ponad 180 godzin na badanie i porównywanie ponad 40 narzędzi do generowania danych testowych. Na podstawie tej obszernej analizy starannie wybraliśmy 12 najskuteczniejszych opcji. Nasza recenzja opiera się na bezpośrednich, praktycznych doświadczeniach, zapewniając czytelnikom rzetelne, obiektywne i praktyczne informacje, które pomogą im w podejmowaniu świadomych decyzji.
- Łatwość użycia: Nasz zespół priorytetowo traktował narzędzia z intuicyjnymi interfejsami, zapewniając testerom i deweloperom możliwość szybkiego generowania danych bez konieczności przechodzenia przez skomplikowaną naukę.
- Szybkość działania: Skupiliśmy się na rozwiązaniach umożliwiających szybkie generowanie danych na dużą skalę, umożliwiając przedsiębiorstwom wydajne testowanie dużych aplikacji przy minimalnym przestoju.
- Różnorodność danych: Nasi recenzenci wybrali narzędzia obsługujące szeroką gamę typów i formatów danych, aby symulować realistyczne scenariusze testowe w różnych środowiskach.
- Możliwość integracji: Oceniliśmy kompatybilność z procesami CI/CD, bazami danych i strukturami automatyzacji, zapewniając płynniejszy przepływ pracy dla zespołów programistycznych i testujących.
- Opcje dostosowywania: Nasi eksperci podkreślili znaczenie narzędzi oferujących elastyczne reguły i konfiguracje, dzięki którym zespoły mogą dostosowywać dane testowe do wyjątkowych wymagań biznesowych.
- Środki bezpieczeństwa: Podczas tworzenia danych testowych braliśmy pod uwagę narzędzia z solidnymi funkcjami zgodności, maskowania i anonimizowania, aby chronić poufne informacje.
- Skalowalność: Grupa badawcza sprawdziła, czy narzędzia mogą obsługiwać zarówno małe projekty, jak i potrzeby przedsiębiorstw, bez obniżania wydajności i stabilności.
- Obsługa wielu platform: Uwzględniliśmy wyłącznie narzędzia, których bezproblemowe działanie zostało potwierdzone w różnych systemach operacyjnych, bazach danych i środowiskach chmurowych.
- Wartość pieniądza: Przeprowadziliśmy analizę kosztów i funkcji, aby polecić narzędzia, które zapewnią maksymalne korzyści bez zbędnych kosztów ogólnych dla organizacji o różnej wielkości.
Jak rozwiązywać typowe problemy z testem Generator Przybory?
Poniżej przedstawiam kilka typowych problemów, z jakimi spotykają się użytkownicy podczas korzystania z narzędzi do generowania testów. Poniżej zamieściłem najlepsze sposoby ich rozwiązania dla każdego z nich:
- Kwestia: Wiele narzędzi generuje niekompletne lub niespójne zbiory danych, co powoduje niepowodzenia testów w złożonych środowiskach.
Rozwiązanie: Zawsze starannie konfiguruj reguły, sprawdzaj poprawność wyników pod kątem wymagań schematu i dbaj o zachowanie spójności relacji we wszystkich generowanych zestawach danych. - Kwestia: Niektóre narzędzia nie radzą sobie ze skutecznym maskowaniem poufnych informacji, co prowadzi do ryzyka niezgodności z przepisami.
Rozwiązanie: Włącz wbudowane algorytmy maskowania, przeprowadzaj weryfikację za pomocą audytów i stosuj anonimizację na poziomie pola, aby chronić prywatność w środowiskach podlegających regulacjom. - Kwestia: Ograniczona integracja z procesami CI/CD utrudnia automatyzację i ciągłe testowanie.
Rozwiązanie: Wybierz narzędzia z interfejsami API REST lub wtyczkami, skonfiguruj bezproblemową integrację DevOps i zaplanuj automatyczne dostarczanie danych dla każdego cyklu kompilacji. - Kwestia: Wygenerowane dane często nie mają wystarczającej objętości, aby naśladować rzeczywiste testy wydajności.
Rozwiązanie: Skonfiguruj generowanie dużych zbiorów danych za pomocą metod próbkowania, użyj syntetycznej ekspansji danych i upewnij się, że testy obciążeniowe obejmują scenariusze szczytowego obciążenia. - Kwestia: Ograniczenia licencyjne uniemożliwiają efektywną współpracę wielu użytkowników nad projektami wykorzystującymi dane testowe.
Rozwiązanie: Wybierz licencje korporacyjne, wdróż współdzielone repozytoria i przypisz uprawnienia oparte na rolach, aby umożliwić wielu zespołom płynny dostęp i współpracę. - Kwestia: Nowi użytkownicy uważają interfejsy narzędzi za skomplikowane, co znacznie wydłuża proces nauki.
Rozwiązanie: Korzystaj z dokumentacji dostawców, włączaj samouczki w narzędziach i zapewnij szkolenia wewnętrzne, aby skrócić czas wdrażania i szybko zwiększyć produktywność. - Kwestia: Niewłaściwe przetwarzanie danych niestrukturalnych lub NoSQL skutkuje powstaniem niedokładnych środowisk testowych.
Rozwiązanie: Wybierz narzędzia obsługujące formaty JSON, XML i NoSQL, sprawdź poprawność mapowań struktur danych i przed wdrożeniem uruchom testy schematów, aby zapewnić dokładność. - Kwestia: Niektóre plany bezpłatne lub freemium nakładają ścisłe ograniczenia dotyczące liczby wierszy lub formatu generowanych zestawów danych.
Rozwiązanie: Upgrade do poziomów płatnych, gdy wymagana jest skalowalność, lub łączyć wiele bezpłatnych zestawów danych za pomocą skryptów, aby skutecznie ominąć ograniczenia.
Werdykt:
Wszystkie powyższe narzędzia do generowania danych testowych uznałem za niezawodne i warte rozważenia. Moja ocena obejmowała dokładną analizę ich funkcji, użyteczności i możliwości spełnienia zróżnicowanych wymagań testowych. Szczególnie zależało mi na tym, jak dobrze radzą sobie ze złożonymi potrzebami dotyczącymi danych, zapewniając spójność i możliwość personalizacji. Po dogłębnej analizie trzy narzędzia najbardziej zwróciły moją uwagę.
- EMS Data GeneratorTo narzędzie zrobiło na mnie wrażenie równowagą między przystępną ceną a łatwością obsługi. Moja ocena wykazała, że może ono wydajnie generować dane testowe zarówno dla małych, jak i dużych baz danych, a także spodobała mi się jego przyjazność dla użytkownika.
- Informatica Test Data Management:To jedno z najbardziej zaawansowanych rozwiązań, z jakimi miałem do czynienia w zakresie tworzenia syntetycznych danych i ich solidnej ochrony. Byłem pod wrażeniem, jak płynnie automatyzowało identyfikację i maskowanie danych w złożonych bazach danych.
- Doble: Wyróżnia się jako praktyczny wybór dla organizacji potrzebujących ustrukturyzowanego zarządzania danymi testowymi. Kiedy użyłem go do uporządkowania dużych zestawów losowych danych w różnych działach, zauważyłem, o ile płynniejsze stało się testowanie.