Hadoop MapReduce Join & Counter z przykładem
Co to jest Dołącz w Mapreduce?
Dołącz do Mapreduce operacja jest używana do łączenia dwóch dużych zestawów danych. Jednak proces ten wymaga napisania dużej ilości kodu, aby wykonać faktyczną operację łączenia. Łączenie dwóch zestawów danych rozpoczyna się od porównania rozmiaru każdego zestawu danych. Jeśli jeden zestaw danych jest mniejszy w porównaniu do drugiego zestawu danych, wówczas mniejszy zestaw danych jest dystrybuowany do każdego węzła danych w klastrze.
Po rozesłaniu sprzężenia w MapReduce program Mapper lub Reduktor używa mniejszego zbioru danych do wyszukiwania pasujących rekordów z dużego zbioru danych, a następnie łączy te rekordy w celu utworzenia rekordów wyjściowych.
Rodzaje przyłączeń
W zależności od miejsca, w którym następuje faktyczne złączenie, złączenia w Hadoop dzieli się na:
1. Łączenie po stronie mapy – Kiedy łączenie jest wykonywane przez osobę odwzorowującą, nazywa się to łączeniem po stronie mapy. W tym typie łączenie jest wykonywane zanim dane zostaną faktycznie wykorzystane przez funkcję mapy. Obowiązkowe jest, aby dane wejściowe każdej mapy miały formę partycji i były posortowane. Ponadto musi być równa liczba partycji i musi być posortowana według klucza łączenia.
2. Łączenie po stronie redukcyjnej – Kiedy łączenie jest wykonywane przez reduktor, nazywa się to łączeniem po stronie redukcyjnej. W tym łączeniu nie ma konieczności posiadania zbioru danych w formie strukturalnej (lub podzielonej na partycje).
W tym przypadku przetwarzanie po stronie mapy emituje klucz łączenia i odpowiadające mu krotki obu tabel. W wyniku tego przetwarzania wszystkie krotki z tym samym kluczem złączenia wpadają do tego samego reduktora, który następnie łączy rekordy z tym samym kluczem złączenia.
Ogólny przebieg procesu złączeń w Hadoop przedstawiono na poniższym diagramie.
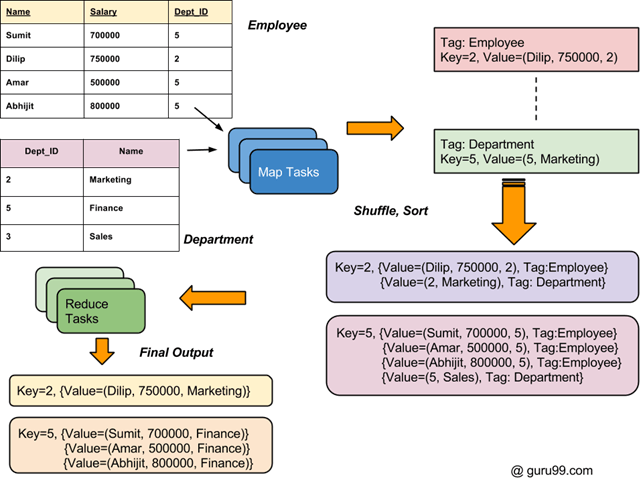
Jak połączyć dwa zestawy danych: przykład MapReduce
Istnieją dwa zestawy danych w dwóch różnych plikach (pokazane poniżej). Klucz Dept_ID jest wspólny w obu plikach. Celem jest użycie MapReduce Join do połączenia tych plików


Wejście: Zbiór danych wejściowych to plik txt, DeptName.txt i DepStrength.txt
Upewnij się, że masz zainstalowany Hadoop. Zanim zaczniesz od rzeczywistego procesu MapReduce Join, zmień użytkownika na „hduser” (identyfikator używany podczas konfiguracji Hadoop, możesz przełączyć się na identyfikator użytkownika używany podczas konfiguracji Hadoop).
su - hduser_

Krok 1) Skopiuj plik zip do wybranej lokalizacji

Krok 2) Rozpakuj plik zip
sudo tar -xvf MapReduceJoin.tar.gz

Krok 3) Przejdź do katalogu MapReduceJoin/
cd MapReduceJoin/
![]()
Krok 4) Uruchom Hadoopa
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh

Krok 5) DeptStrength.txt i DeptName.txt to pliki wejściowe używane w tym przykładowym programie MapReduce Join.
Plik ten należy skopiować do HDFS za pomocą poniższego polecenia:
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal DeptStrength.txt DeptName.txt /

Krok 6) Uruchom program za pomocą poniższego polecenia-
$HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar MapReduceJoin/JoinDriver/DeptStrength.txt /DeptName.txt /output_mapreducejoin
![]()

Krok 7) Po wykonaniu plik wyjściowy (o nazwie „part-00000”) zostanie zapisany w katalogu /output_mapreducejoin w systemie HDFS
Wyniki można zobaczyć za pomocą interfejsu wiersza poleceń
$HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000

Wyniki można również zobaczyć za pośrednictwem interfejsu internetowego, ponieważ:

Teraz wybierz „Przeglądaj system plików” i przejdź do /output_mapreducejoin

Otwarte część-r-00000

Wyniki są pokazane

UWAGA: Pamiętaj, że przed ponownym uruchomieniem tego programu będziesz musiał usunąć katalog wyjściowy /output_mapreducejoin
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
Alternatywą jest użycie innej nazwy katalogu wyjściowego.
Co to jest licznik w MapReduce?
A Licznik w MapReduce jest mechanizmem używanym do zbierania i mierzenia informacji statystycznych o zadaniach i zdarzeniach MapReduce. Liczniki śledzą różne statystyki zadań w MapReduce, takie jak liczba wykonanych operacji i postęp operacji. Liczniki są używane do diagnozowania problemów w MapReduce.
Liczniki Hadoop działają podobnie do umieszczania komunikatu dziennika w kodzie mapy lub redukcji. Informacje te mogą być przydatne do diagnozowania problemu w przetwarzaniu zadań MapReduce.
Zwykle te liczniki w Hadoop są zdefiniowane w programie (mapują lub zmniejszają) i są zwiększane podczas wykonywania, gdy wystąpi określone zdarzenie lub warunek (specyficzny dla tego licznika). Bardzo dobrym zastosowaniem liczników Hadoop jest śledzenie prawidłowych i nieprawidłowych rekordów z wejściowego zbioru danych.
Rodzaje liczników MapReduce
Zasadniczo istnieją 2 rodzaje MapaReduce Lady
- Wbudowane liczniki Hadoop:Istnieje kilka wbudowanych liczników Hadoop, które istnieją dla każdego zadania. Poniżej znajdują się wbudowane grupy liczników-
- Liczniki zadań MapReduce – Zbiera informacje specyficzne dla zadania (np. liczbę rekordów wejściowych) w czasie jego wykonywania.
- Liczniki systemu plików – Zbiera informacje, takie jak liczba bajtów odczytanych lub zapisanych przez zadanie
- Liczniki FileInputFormat – Zbiera informacje o liczbie bajtów odczytanych przez FileInputFormat
- Liczniki FileOutputFormat – Zbiera informacje o liczbie bajtów zapisanych za pomocą FileOutputFormat
- Liczniki zadań – Liczniki te są używane przez JobTracker. Gromadzone przez nich statystyki obejmują np. liczbę uruchomionych zadań dla danego zlecenia.
- Liczniki zdefiniowane przez użytkownika
Oprócz wbudowanych liczników użytkownik może definiować własne liczniki korzystając z podobnych funkcjonalności udostępnianych przez języki programowania. Na przykład w Java „enum” służy do definiowania liczników zdefiniowanych przez użytkownika.
Przykład liczników
Przykład MapClass z licznikami do zliczania liczby brakujących i nieprawidłowych wartości. Plik danych wejściowych używany w tym samouczku. Nasz zestaw danych wejściowych to plik CSV, SprzedażJan2009.csv
public static class MapClass
extends MapReduceBase
implements Mapper<LongWritable, Text, Text, Text>
{
static enum SalesCounters { MISSING, INVALID };
public void map ( LongWritable key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException
{
//Input string is split using ',' and stored in 'fields' array
String fields[] = value.toString().split(",", -20);
//Value at 4th index is country. It is stored in 'country' variable
String country = fields[4];
//Value at 8th index is sales data. It is stored in 'sales' variable
String sales = fields[8];
if (country.length() == 0) {
reporter.incrCounter(SalesCounters.MISSING, 1);
} else if (sales.startsWith("\"")) {
reporter.incrCounter(SalesCounters.INVALID, 1);
} else {
output.collect(new Text(country), new Text(sales + ",1"));
}
}
}
Powyższy fragment kodu przedstawia przykładową implementację liczników w Hadoop Map Redukuj.
Tutaj, Liczniki sprzedaży jest licznikiem zdefiniowanym za pomocą „wyliczenie”. Służy do liczenia BRAKUJE oraz NIEWAŻNY zapisy wejściowe.
We fragmencie kodu if 'kraj' pole ma zerową długość, to brakuje jego wartości i stąd odpowiedniego licznika Liczniki sprzedaży.BRAK jest zwiększany.
Dalej, jeśli 'obroty' pole zaczyna się od a " wówczas zapis zostanie uznany za NIEWAŻNY. Jest to sygnalizowane wzrostem licznika Liczniki sprzedaży.NIEPRAWIDŁOWY.