Dyplæringsopplæring for nybegynnere: Grunnleggende om nevrale nettverk
Hva er Deep Learning?
Dyp læring er en dataprogramvare som etterligner nettverket av nevroner i en hjerne. Det er en undergruppe av maskinlæring basert på kunstige nevrale nettverk med representasjonslæring. Det kalles dyp læring fordi det benytter seg av dype nevrale nettverk. Denne læringen kan være veiledet, semi-veiledet eller uten veiledning.
Dyplæringsalgoritmer er konstruert med tilkoblede lag.
- Det første laget kalles Input Layer
- Det siste laget kalles Output Layer
- Alle lag i mellom kalles skjulte lag. Ordet dyp betyr at nettverket forbinder nevroner i mer enn to lag.
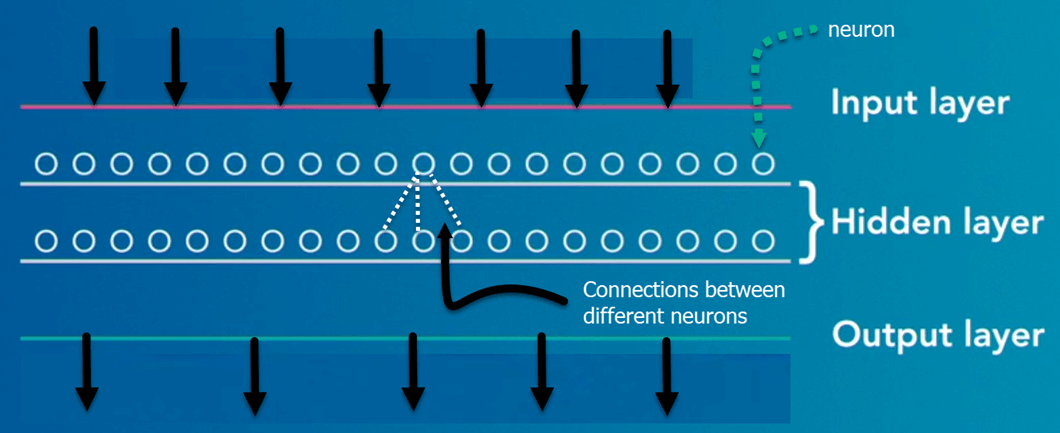
Hvert skjult lag er sammensatt av nevroner. Nevronene er koblet til hverandre. Nevronet vil behandle og deretter forplante inngangssignalet det mottar laget over det. Styrken på signalet gitt nevronet i neste lag avhenger av vekten, skjevheten og aktiveringsfunksjonen.
Nettverket bruker store mengder inndata og driver dem gjennom flere lag; nettverket kan lære stadig mer komplekse funksjoner ved dataene på hvert lag.
Dyp læringsprosess
Et dypt nevralt nettverk gir toppmoderne nøyaktighet i mange oppgaver, fra gjenstandsgjenkjenning til talegjenkjenning. De kan lære automatisk, uten forhåndsdefinert kunnskap eksplisitt kodet av programmererne.

For å forstå ideen om dyp læring, forestill deg en familie, med et spedbarn og foreldre. Småbarnet peker gjenstander med lillefingeren og sier alltid ordet "katt". Siden foreldrene hans er bekymret for utdannelsen hans, sier de stadig til ham "Ja, det er en katt" eller "Nei, det er ikke en katt." Spedbarnet fortsetter å peke på gjenstander, men blir mer nøyaktig med "katter". Den lille ungen vet innerst inne ikke hvorfor han kan si at det er en katt eller ikke. Han har nettopp lært hvordan man kan hierarkisere komplekse trekk som kommer opp med en katt ved å se på kjæledyret generelt og fortsette å fokusere på detaljer som halen eller nesen før for å bestemme seg.
Et nevralt nettverk fungerer ganske likt. Hvert lag representerer et dypere kunnskapsnivå, dvs. kunnskapshierarkiet. Et nevralt nettverk med fire lag vil lære mer komplekse funksjoner enn med to lag.
Læringen foregår i to faser:
Første fase: Den første fasen består av å bruke en ikke-lineær transformasjon av input og lage en statistisk modell som output.
Andre fase: Den andre fasen tar sikte på å forbedre modellen med en matematisk metode kjent som derivat.
Det nevrale nettverket gjentar disse to fasene hundrevis til tusenvis av ganger til det har nådd et akseptabelt nivå av nøyaktighet. Gjentakelsen av denne to-fasen kalles en iterasjon.
For å gi et eksempel på dyp læring, ta en titt på bevegelsen nedenfor, modellen prøver å lære å danse. Etter 10 minutters trening vet ikke modellen hvordan den skal danse, og det ser ut som en skribleri.

Etter 48 timers læring mestrer datamaskinen kunsten å danse.

Klassifisering av nevrale nettverk
Grunne nevrale nettverk: The Shallow nevrale nettverk har bare ett skjult lag mellom input og output.
Dyp nevralt nettverk: Dype nevrale nettverk har mer enn ett lag. For eksempel teller Google LeNet-modellen for bildegjenkjenning 22 lag.
I dag brukes dyp læring på mange måter som en førerløs bil, mobiltelefon, Google-søkemotor, svindeloppdaging, TV og så videre.
Typer dyplæringsnettverk
Nå i denne Deep Neural Network-veiledningen vil vi lære om typer Deep Learning Networks:

Feed-forward nevrale nettverk
Den enkleste typen kunstig nevrale nettverk. Med denne typen arkitektur flyter informasjon bare i én retning, fremover. Det betyr at informasjonsflytene starter ved inngangslaget, går til de "skjulte" lagene og slutter ved utdatalaget. Nettverket
har ikke en løkke. Informasjon stopper ved utgangslagene.
Tilbakevendende nevrale nettverk (RNN)
RNN er et flerlags nevralt nettverk som kan lagre informasjon i kontekstnoder, slik at det kan lære datasekvenser og sende ut et tall eller en annen sekvens. Med enkle ord er det et kunstig nevrale nettverk hvis forbindelser mellom nevroner inkluderer løkker. RNN-er er godt egnet for behandling av sekvenser av innganger.

For eksempel, hvis oppgaven er å forutsi det neste ordet i setningen “Vil du ha en …………?
- RNN-nevronene vil motta et signal som peker mot begynnelsen av setningen.
- Nettverket mottar ordet "Do" som en inngang og produserer en vektor av tallet. Denne vektoren føres tilbake til nevronet for å gi et minne til nettverket. Dette stadiet hjelper nettverket til å huske at det mottok "Do" og det mottok det i første posisjon.
- Nettverket vil på samme måte fortsette til de neste ordene. Det tar ordet «du» og «vil ha». Nevronenes tilstand oppdateres ved mottak av hvert ord.
- Det siste stadiet skjer etter å ha mottatt ordet "a." Det nevrale nettverket vil gi en sannsynlighet for hvert engelsk ord som kan brukes til å fullføre setningen. En godt trent RNN tildeler sannsynligvis stor sannsynlighet til "kafé", "drikke", "burger" osv.
Vanlige bruk av RNN
- Hjelp verdipapirhandlere med å generere analytiske rapporter
- Oppdag avvik i regnskapskontrakten
- Oppdag falske kredittkorttransaksjoner
- Gi en bildetekst for bilder
- Power chatbots
- Standardbruken av RNN forekommer når utøverne jobber med tidsseriedata eller sekvenser (f.eks. lydopptak eller tekst).
Konvolusjonelle nevrale nettverk (CNN)
CNN er et flerlags nevralt nettverk med en unik arkitektur designet for å trekke ut stadig mer komplekse trekk ved dataene i hvert lag for å bestemme utdataene. CNN er godt egnet for perseptuelle oppgaver.

CNN brukes mest når det er et ustrukturert datasett (f.eks. bilder) og utøverne trenger å trekke ut informasjon fra det.
For eksempel, hvis oppgaven er å forutsi en bildetekst:
- CNN mottar et bilde av la oss si en katt, dette bildet, i datamaskinterm, er en samling av pikselen. Vanligvis ett lag for gråtonebildet og tre lag for et fargebilde.
- Under funksjonslæringen (dvs. skjulte lag), vil nettverket identifisere unike funksjoner, for eksempel halen til katten, øret osv.
- Når nettverket grundig lærte å gjenkjenne et bilde, kan det gi en sannsynlighet for hvert bilde det kjenner. Etiketten med høyest sannsynlighet vil bli prediksjonen til nettverket.
Forsterkningslæring
Forsterkningslæring er et underfelt av maskinlæring der systemer trenes opp ved å motta virtuelle "belønninger" eller "straff", i hovedsak læring ved prøving og feiling. Googles DeepMind har brukt forsterkningslæring for å slå en menneskelig mester i Go-spillene. Forsterkende læring brukes også i videospill for å forbedre spillopplevelsen ved å tilby smartere roboter.
En av de mest kjente algoritmene er:
- Q-læring
- Deep Q-nettverk
- State-Action-Reward-State-Action (SARSA)
- Deep Deterministic Policy Gradient (DDPG)
Eksempler på dyplæringsapplikasjoner
Nå i denne Deep Learning for nybegynneropplæringen, la oss lære om Deep Learning-applikasjoner:
AI i finans
Den finansielle teknologisektoren har allerede begynt å bruke AI for å spare tid, redusere kostnader og tilføre verdi. Dyplæring endrer utlånsbransjen ved å bruke mer robust kredittscoring. Kredittbeslutningstakere kan bruke AI for robuste kredittlånsøknader for å oppnå raskere og mer nøyaktig risikovurdering, ved å bruke maskinell intelligens for å ta hensyn til søkernes karakter og kapasitet.
Underwrite er et Fintech-selskap som tilbyr en AI-løsning for kredittprodusenter. underwrite.ai bruker AI for å oppdage hvilken søker som er mer sannsynlig å betale tilbake et lån. Deres tilnærming overgår radikalt tradisjonelle metoder.
AI i HR
Under Armour, et sportsklærfirma revolusjonerer ansettelse og moderniserer kandidatopplevelsen ved hjelp av kunstig intelligens. Faktisk reduserer Under Armour ansettelsestiden for sine butikker med 35 %. Under Armour møtte en økende popularitetsinteresse tilbake i 2012. De hadde i gjennomsnitt 30000 XNUMX CVer i måneden. Å lese alle disse søknadene og begynne å starte screening- og intervjuprosessen tok for lang tid. Den langvarige prosessen for å få folk ansatt og ombord påvirket Under Armours evne til å ha sine butikker fullt bemannet, rampet og klare til drift.
På den tiden hadde Under Armour all "må ha" HR-teknologi på plass, for eksempel transaksjonsløsninger for innkjøp, søknad, sporing og onboarding, men disse verktøyene var ikke nyttige nok. Velg under rustning HireVue, en AI-leverandør for HR-løsning, for både on-demand og live intervjuer. Resultatene ble bløffing; de klarte å redusere med 35 % tiden til å fylle. Til gjengjeld hyret de ansatte av høyere kvalitet.
AI i markedsføring
AI er et verdifullt verktøy for kundeserviceadministrasjon og personaliseringsutfordringer. Forbedret talegjenkjenning i kundesenteradministrasjon og samtaleruting som et resultat av bruk av AI-teknikker gir en mer sømløs opplevelse for kundene.
For eksempel, dyp læringsanalyse av lyd lar systemer vurdere en kundes emosjonelle tone. Hvis kunden reagerer dårlig på AI chatbot, kan systemet omdirigeres samtalen til ekte, menneskelige operatører som tar over problemet.
Bortsett fra de tre Deep learning-eksemplene ovenfor, er AI mye brukt i andre sektorer/bransjer.
Hvorfor er dyp læring viktig?
Dyplæring er et kraftig verktøy for å gjøre prediksjon til et handlingsverdig resultat. Dyplæring utmerker seg i mønsteroppdagelse (uovervåket læring) og kunnskapsbasert prediksjon. Big data er drivstoffet for dyp læring. Når begge er kombinert, kan en organisasjon høste enestående resultater når det gjelder produktivitet, salg, ledelse og innovasjon.
Dyplæring kan utkonkurrere tradisjonell metode. For eksempel er dyplæringsalgoritmer 41 % mer nøyaktige enn maskinlæringsalgoritmer i bildeklassifisering, 27 % mer nøyaktige i ansiktsgjenkjenning og 25 % i stemmegjenkjenning.
Begrensninger ved dyp læring
Nå i denne veiledningen for nevrale nettverk vil vi lære om begrensninger ved dyp læring:
Datamerking
De fleste nåværende AI-modeller er trent gjennom "overvåket læring." Det betyr at mennesker må merke og kategorisere de underliggende dataene, noe som kan være en betydelig og feilutsatt oppgave. For eksempel ansetter selskaper som utvikler selvkjørende bilteknologier hundrevis av mennesker til manuelt å kommentere timer med videofeeder fra prototypekjøretøyer for å hjelpe til med å trene disse systemene.
Skaff deg enorme opplæringsdatasett
Det har vist seg at enkle dyplæringsteknikker som CNN i noen tilfeller kan imitere kunnskapen til eksperter innen medisin og andre felt. Den nåværende bølgen av maskinlæringkrever imidlertid opplæringsdatasett som ikke bare er merket, men også tilstrekkelig brede og universelle.
Dyplæringsmetoder krevde tusenvis av observasjoner for at modeller skulle bli relativt gode på klassifiseringsoppgaver og, i noen tilfeller, millioner for at de skulle utføre på menneskelig nivå. Uten overraskelse er dyp læring kjent i gigantiske teknologiselskaper; de bruker big data for å samle petabyte med data. Det lar dem lage en imponerende og svært nøyaktig dyplæringsmodell.
Forklar et problem
Store og komplekse modeller kan være vanskelig å forklare, i menneskelige termer. For eksempel hvorfor en bestemt beslutning ble tatt. Det er en grunn til at aksepten av noen AI-verktøy er treg i applikasjonsområder der tolkbarhet er nyttig eller faktisk nødvendig.
Videre, ettersom bruken av AI utvides, kan regulatoriske krav også drive behovet for mer forklarbare AI-modeller.
Sammendrag
Oversikt over dyp læring: Dyplæring er det nye toppmoderne for kunstig intelligens. Dyplæringsarkitektur er sammensatt av et inputlag, skjulte lag og et utdatalag. Ordet dyp betyr at det er mer enn to fullstendig sammenkoblede lag.
Det er en enorm mengde nevrale nettverk, der hver arkitektur er designet for å utføre en gitt oppgave. For eksempel fungerer CNN veldig bra med bilder, RNN gir imponerende resultater med tidsserier og tekstanalyse.
Deep learning er nå aktiv på forskjellige felt, fra finans til markedsføring, forsyningskjede og markedsføring. Store firmaer er de første som bruker dyp læring fordi de allerede har en stor pool med data. Dyplæring krever et omfattende opplæringsdatasett.