Hadoop MapReduce 조인 및 카운터 예시
Mapreduce의 조인이란 무엇입니까?
맵리듀스 조인 연산은 두 개의 큰 데이터 세트를 결합하는 데 사용됩니다. 그러나 이 프로세스에는 실제 조인 연산을 수행하기 위해 많은 코드를 작성하는 것이 포함됩니다. 두 데이터 세트를 결합하는 것은 각 데이터 세트의 크기를 비교하는 것으로 시작합니다. 한 데이터 세트가 다른 데이터 세트보다 작으면 더 작은 데이터 세트가 클러스터의 모든 데이터 노드에 분산됩니다.
MapReduce의 조인이 배포되면 Mapper 또는 Reducer는 더 작은 데이터 세트를 사용하여 큰 데이터 세트에서 일치하는 레코드를 조회한 다음 해당 레코드를 결합하여 출력 레코드를 형성합니다.
조인 유형
실제 조인이 수행되는 위치에 따라 Hadoop의 조인은 다음과 같이 분류됩니다.
1. 맵 측 조인 - 매퍼가 조인을 수행하는 경우 이를 맵 측 조인이라고 합니다. 이 유형에서는 맵 기능에 의해 데이터가 실제로 소비되기 전에 조인이 수행됩니다. 각 맵에 대한 입력은 파티션 형식이어야 하며 정렬된 순서로 되어 있어야 합니다. 또한 동일한 수의 파티션이 있어야 하며 조인 키를 기준으로 정렬되어야 합니다.
2. 감소 측 조인 - 리듀서가 조인을 수행하는 경우 이를 리듀스 측 조인이라고 합니다. 이 조인에서는 데이터세트를 구조화된 형태(또는 분할된 형태)로 가질 필요가 없습니다.
여기서 맵 측 처리는 조인 키와 두 테이블의 해당 튜플을 내보냅니다. 이 처리의 결과로 동일한 조인 키를 가진 모든 튜플은 동일한 리듀서에 속해 동일한 조인 키로 레코드를 조인합니다.
Hadoop의 전체 조인 프로세스 흐름은 아래 다이어그램에 설명되어 있습니다.
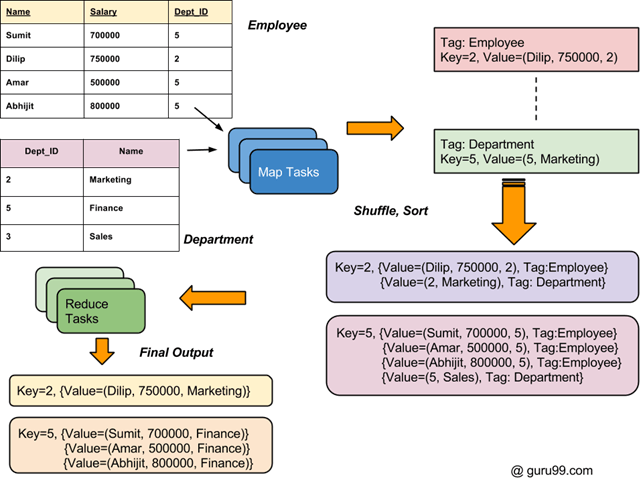
두 개의 데이터 세트를 결합하는 방법: MapReduce 예
두 개의 서로 다른 파일에 두 개의 데이터 세트가 있습니다(아래 참조). Key Dept_ID는 두 파일 모두에서 공통입니다. 목표는 MapReduce Join을 사용하여 이러한 파일을 결합하는 것입니다.


입력: 입력 데이터 세트는 txt 파일이며, DeptName.txt 및 DepStrength.txt
Hadoop이 설치되어 있는지 확인하십시오. MapReduce Join 예제 실제 프로세스를 시작하기 전에 사용자를 'hduser'로 변경합니다(Hadoop 구성 중에 사용된 ID, Hadoop 구성 중에 사용된 사용자 ID로 전환할 수 있음).
su - hduser_

단계 1) zip 파일을 원하는 위치에 복사하세요.

단계 2) Zip 파일 압축 풀기
sudo tar -xvf MapReduceJoin.tar.gz

단계 3) MapReduceJoin/ 디렉터리로 이동합니다.
cd MapReduceJoin/
![]()
단계 4) 하둡 시작
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh

단계 5) DeptStrength.txt 및 DeptName.txt는 이 MapReduce Join 예제 프로그램에 사용되는 입력 파일입니다.
이 파일은 아래 명령을 사용하여 HDFS에 복사해야 합니다.
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal DeptStrength.txt DeptName.txt /

단계 6) 아래 명령을 사용하여 프로그램을 실행하십시오.
$HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar MapReduceJoin/JoinDriver/DeptStrength.txt /DeptName.txt /output_mapreducejoin
![]()

단계 7) 실행 후 출력 파일('part-00000'이라는 이름)은 HDFS의 /output_mapreducejoin 디렉터리에 저장됩니다.
명령줄 인터페이스를 사용하여 결과를 볼 수 있습니다.
$HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000

결과는 웹 인터페이스를 통해 다음과 같이 볼 수도 있습니다.

지금 선택하십시오. '파일 시스템 찾아보기' 그리고 최대로 탐색 /output_mapreducejoin

엽니다 부품-r-00000

결과가 표시됩니다

알림: 다음에 이 프로그램을 실행하기 전에 출력 디렉터리 /output_mapreducejoin을 삭제해야 합니다.
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
대안은 출력 디렉터리에 다른 이름을 사용하는 것입니다.
MapReduce의 카운터란 무엇입니까?
A MapReduce의 카운터 MapReduce 작업 및 이벤트에 대한 통계 정보를 수집하고 측정하는 데 사용되는 메커니즘입니다. 카운터는 MapReduce에서 발생한 작업 수와 작업 진행률과 같은 다양한 작업 통계를 추적합니다. 카운터는 MapReduce에서 문제 진단에 사용됩니다.
Hadoop 카운터는 맵이나 축소를 위한 코드에 로그 메시지를 넣는 것과 유사합니다. 이 정보는 MapReduce 작업 처리 시 문제를 진단하는 데 유용할 수 있습니다.
일반적으로 Hadoop의 이러한 카운터는 프로그램(맵 또는 감소)에 정의되며 특정 이벤트 또는 조건(해당 카운터에 특정한)이 발생할 때 실행 중에 증가됩니다. Hadoop 카운터를 매우 효과적으로 적용하는 방법은 입력 데이터세트에서 유효한 레코드와 잘못된 레코드를 추적하는 것입니다.
MapReduce 카운터 유형
기본적으로 2가지 종류가 있습니다 MapReduce 카운터
- Hadoop 내장 카운터:작업별로 존재하는 내장형 Hadoop 카운터가 있습니다. 다음은 내장된 카운터 그룹입니다.
- MapReduce 작업 카운터 – 실행 시간 동안 작업별 정보(예: 입력 레코드 수)를 수집합니다.
- 파일 시스템 카운터 – 작업에서 읽거나 쓴 바이트 수와 같은 정보를 수집합니다.
- FileInputFormat 카운터 – FileInputFormat을 통해 읽은 바이트 수 정보 수집
- FileOutputFormat 카운터 – FileOutputFormat을 통해 작성된 바이트 수의 정보를 수집합니다.
- 작업 카운터 – 이 카운터는 JobTracker에서 사용됩니다. 수집된 통계에는 작업에 대해 시작된 작업 수가 포함됩니다.
- 사용자 정의 카운터
내장된 카운터 외에도 사용자는 다음에서 제공하는 유사한 기능을 사용하여 자신의 카운터를 정의할 수 있습니다. 프로그래밍 언어. 예를 들어 Java 'enum'은 사용자 정의 카운터를 정의하는 데 사용됩니다.
카운터 예
누락된 값과 유효하지 않은 값의 수를 계산하기 위한 카운터가 있는 MapClass의 예입니다. 이 튜토리얼에서 사용된 입력 데이터 파일 입력 데이터 세트는 CSV 파일입니다. SalesJan2009.csv
public static class MapClass
extends MapReduceBase
implements Mapper<LongWritable, Text, Text, Text>
{
static enum SalesCounters { MISSING, INVALID };
public void map ( LongWritable key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException
{
//Input string is split using ',' and stored in 'fields' array
String fields[] = value.toString().split(",", -20);
//Value at 4th index is country. It is stored in 'country' variable
String country = fields[4];
//Value at 8th index is sales data. It is stored in 'sales' variable
String sales = fields[8];
if (country.length() == 0) {
reporter.incrCounter(SalesCounters.MISSING, 1);
} else if (sales.startsWith("\"")) {
reporter.incrCounter(SalesCounters.INVALID, 1);
} else {
output.collect(new Text(country), new Text(sales + ",1"));
}
}
}
위의 코드 조각은 Hadoop Map Reduce의 카운터 구현 예를 보여줍니다.
여기 판매 카운터 다음을 사용하여 정의된 카운터입니다. '열거형'. 계산하는데 사용됩니다 잃어버린 및 INVALID 입력 기록.
코드 조각에서 다음과 같은 경우 '국가' 필드의 길이가 XNUMX이면 해당 값이 누락되어 해당 카운터가 표시됩니다. SalesCounters.MISSING 가 증가합니다.
다음으로 만약에 '매상' 필드는 다음으로 시작합니다. " 그러면 해당 기록은 잘못된 것으로 간주됩니다. 이는 카운터 증가로 표시됩니다. SalesCounters.INVALID입니다.