예제가 포함된 TensorFlow의 오토인코더
딥러닝에서 오토인코더란 무엇인가요?
An 자동 인코더 감독되지 않은 방식으로 데이터 코딩을 효율적으로 학습하기 위한 도구입니다. 신호 잡음을 무시하도록 신경망을 훈련시켜 차원 축소를 위한 데이터 세트의 표현을 학습하는 데 도움이 되는 일종의 인공 신경망입니다. 입력을 다시 생성하는 데 유용한 도구입니다.
간단히 말해서, 기계는 이미지를 촬영하고 밀접하게 관련된 사진을 생성할 수 있습니다. 이런 종류의 신경망의 입력에는 라벨이 지정되지 않습니다. 즉, 네트워크는 감독 없이 학습할 수 있습니다. 보다 정확하게는 가장 중요한 기능에만 초점을 맞추기 위해 입력이 네트워크에 의해 인코딩됩니다. 이것이 차원 축소에 오토인코더가 널리 사용되는 이유 중 하나입니다. 게다가, 자동 인코더를 사용하여 다음을 생성할 수 있습니다. 생성 학습 모델. 예를 들어, 신경망은 일련의 얼굴로 훈련된 다음 새로운 얼굴을 생성할 수 있습니다.
TensorFlow Autoencoder는 어떻게 작동하나요?
오토인코더의 목적은 필수 기능에만 초점을 맞춰 입력의 근사치를 생성하는 것입니다. 단순히 입력을 복사하고 붙여넣어 출력을 생성하는 방법만 배우면 안 되는지 생각할 수도 있습니다. 실제로 오토인코더는 단순히 출력을 복사하는 것과는 달리 네트워크가 데이터를 표현하는 새로운 방법을 배우도록 하는 일련의 제약 조건입니다.
일반적인 오토인코더는 입력, 내부 표현 및 출력(입력의 근사치)으로 정의됩니다. 학습은 내부 표현에 연결된 레이어에서 발생합니다. 실제로 전통적인 신경망처럼 보이는 두 개의 주요 레이어 블록이 있습니다. 약간의 차이점은 출력을 포함하는 레이어가 입력과 동일해야 한다는 것입니다. 아래 그림에서 원래 입력은 첫 번째 블록인 인코더. 이 내부 표현은 입력 크기를 압축(줄입니다)합니다. 두 번째 블록에서는 입력이 재구성됩니다. 이것이 디코딩 단계입니다.

모델은 손실 함수를 최소화하여 가중치를 업데이트합니다. 재구성 출력이 입력과 다르면 모델에 불이익이 발생합니다.
구체적으로 50×50(즉, 250픽셀) 크기의 그림과 250개의 뉴런으로 구성된 하나의 숨겨진 레이어만 있는 신경망을 상상해 보세요. 학습은 입력보다 100배 작은 기능 맵에서 수행됩니다. 이는 네트워크가 XNUMX과 동일한 뉴런 벡터만으로 XNUMX개의 픽셀을 재구성하는 방법을 찾아야 함을 의미합니다.
스택형 오토인코더 예
이 Autoencoder 튜토리얼에서는 스택형 오토인코더를 사용하는 방법을 알아봅니다. 아키텍처는 기존 신경망과 유사합니다. 입력은 압축되거나 크기를 줄이기 위해 숨겨진 레이어로 이동한 다음 재구성 레이어에 도달합니다. 목표는 원본과 최대한 가까운 출력 이미지를 생성하는 것입니다. 모델은 일련의 제약 조건 하에서, 즉 더 낮은 차원으로 작업을 달성하는 방법을 학습해야 합니다.
요즘 오토인코더는 딥러닝 주로 이미지의 노이즈를 제거하는 데 사용됩니다. 긁힌 자국이 있는 이미지를 상상해 보세요. 인간은 여전히 콘텐츠를 인식할 수 있습니다. 노이즈 제거 오토인코더의 아이디어는 그림에 노이즈를 추가하여 네트워크가 데이터 뒤에 있는 패턴을 학습하도록 하는 것입니다.
Autoencoder Deep Learning의 또 다른 유용한 제품군은 Variational Autoencoder입니다. 이러한 유형의 네트워크는 새로운 이미지를 생성할 수 있습니다. 남자의 이미지로 네트워크를 훈련한다고 상상해 보세요. 그러한 네트워크는 새로운 얼굴을 만들어낼 수 있습니다.
TensorFlow를 사용하여 자동 인코더를 구축하는 방법
이 튜토리얼에서는 스택형 오토인코더를 구축하여 이미지를 재구성하는 방법을 배웁니다.
당신은 사용할 것입니다 CIFAR-10 데이터 세트 60000개의 32×32 컬러 이미지가 포함되어 있습니다. Autoencoder 데이터세트는 이미 학습용 이미지 50000개와 테스트용 이미지 10000개로 분할되어 있습니다. 최대 XNUMX개의 클래스가 있습니다:
- 비행기
- 자동차
- 새
- 고양이
- 사슴
- 개
- 개구리
- 말
- 디지털,
- 트럭
이 URL https://www.cs.toronto.edu/~kriz/cifar.html에서 이미지를 다운로드하고 압축을 풀어야 합니다. for-10-batches-py 폴더에는 각각 10000개의 이미지가 무작위 순서로 포함된 XNUMX개의 데이터 배치가 포함되어 있습니다.
모델을 구축하고 훈련하기 전에 일부 데이터 처리를 적용해야 합니다. 다음과 같이 진행하게 됩니다:
- 데이터 가져 오기
- 데이터를 흑백 형식으로 변환
- 모든 배치 추가
- 학습 데이터 세트 구성
- 이미지 시각화 장치 구성
이미지 전처리
1단계) 데이터 가져오기
공식 웹사이트에 따르면 다음 코드로 데이터를 업로드할 수 있습니다. Autoencoder 코드는 데이터를 사전에 로드합니다. 데이터 그리고 상표. 코드는 함수라는 점에 유의하세요.
import numpy as np
import tensorflow as tf
import pickle
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='latin1')
return dict
2단계) 데이터를 흑백 형식으로 변환
단순화를 위해 데이터를 회색조로 변환하겠습니다. 즉, 색상 이미지의 경우 XNUMX차원에 대해 XNUMX차원만 사용합니다. 대부분의 신경망은 XNUMX차원 입력에만 작동합니다.
def grayscale(im):
return im.reshape(im.shape[0], 3, 32, 32).mean(1).reshape(im.shape[0], -1)
3단계) 모든 배치를 추가합니다.
이제 두 함수가 모두 생성되고 데이터세트가 로드되었으므로 루프를 작성하여 메모리에 데이터를 추가할 수 있습니다. 주의 깊게 확인하면 데이터가 포함된 압축 해제 파일의 이름은 1부터 5까지의 숫자가 포함된 data_batch_로 지정됩니다. 파일을 반복하여 데이터에 추가할 수 있습니다.
이 단계가 완료되면 색상 데이터를 회색조 형식으로 변환합니다. 보시다시피 데이터의 모양은 50000과 1024입니다. 32*32 픽셀은 이제 2014로 평면화되었습니다.
# Load the data into memory
data, labels = [], []
## Loop over the b
for i in range(1, 6):
filename = './cifar-10-batches-py/data_batch_' + str(i)
open_data = unpickle(filename)
if len(data) > 0:
data = np.vstack((data, open_data['data']))
labels = np.hstack((labels, open_data['labels']))
else:
data = open_data['data']
labels = open_data['labels']
data = grayscale(data)
x = np.matrix(data)
y = np.array(labels)
print(x.shape)
(50000, 1024)
참고: './cifar-10-batches-py/data_batch_'를 파일의 실제 위치로 변경하세요. 예를 들어 Windows 컴퓨터의 경우 경로는 filename = 'E:\cifar-10-batches-py\data_batch_' + str(i)일 수 있습니다.
4단계) 학습 데이터 세트 구성
훈련을 더 빠르고 쉽게 만들기 위해 말 이미지로만 모델을 훈련하겠습니다. 말은 레이블 데이터에서 10번째 클래스입니다. CIFAR-5000 데이터 세트 문서에 언급된 대로 각 클래스에는 5.000개의 이미지가 포함되어 있습니다. 데이터의 모양을 인쇄하면 아래 그림과 같이 1024열의 XNUMX개의 이미지가 있는지 확인할 수 있습니다. TensorFlow 오토인코더 예시 단계.
horse_i = np.where(y == 7)[0] horse_x = x[horse_i] print(np.shape(horse_x)) (5000, 1024)
5단계) 이미지 시각화 장치 구성
마지막으로 이미지를 플롯하는 함수를 구성합니다. 오토인코더에서 재구성된 이미지를 인쇄하려면 이 함수가 필요합니다.
이미지를 인쇄하는 쉬운 방법은 matplotlib 라이브러리의 imshow 개체를 사용하는 것입니다. 데이터의 모양을 1024에서 32*32(예: 이미지 형식)로 변환해야 합니다.
# To plot pretty figures
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
def plot_image(image, shape=[32, 32], cmap = "Greys_r"):
plt.imshow(image.reshape(shape), cmap=cmap,interpolation="nearest")
plt.axis("off")
이 함수는 3개의 인수를 사용합니다.
- 영상: 입력
- 셰이프: 목록, 이미지의 크기
- cmap: 컬러 맵을 선택하십시오. 기본적으로 회색
데이터 세트의 첫 번째 이미지를 플롯해 볼 수 있습니다. 말을 탄 사람을 봐야 합니다.
plot_image(horse_x[1], shape=[32, 32], cmap = "Greys_r")

데이터세트 추정기 설정
좋습니다. 이제 데이터 세트를 사용할 준비가 되었으므로 Tensorflow를 사용할 수 있습니다. 모델을 구축하기 전에 Tensorflow의 데이터 세트 추정기를 사용하여 네트워크에 공급해 보겠습니다.
TensorFlow 추정기를 사용하여 데이터 세트를 구축합니다. 마음을 새롭게 하려면 다음을 사용해야 합니다.
- from_tensor_slices
- 반복
- 일괄
데이터세트를 구축하는 전체 코드는 다음과 같습니다.
dataset = tf.data.Dataset.from_tensor_slices(x).repeat().batch(batch_size)
x는 다음 모양의 플레이스홀더입니다.
- [None,n_inputs]: 네트워크에 공급되는 이미지 수가 배치 크기와 동일하므로 None으로 설정합니다.
자세한 내용은 튜토리얼을 참조하세요. 선형 회귀.
그런 다음 반복자를 만들어야 합니다. 이 코드 줄이 없으면 어떤 데이터도 파이프라인을 통과하지 않습니다.
iter = dataset.make_initializable_iterator() # create the iteratorfeatures = iter.get_next()
이제 파이프라인이 준비되었으므로 첫 번째 이미지가 이전과 동일한지(즉, 말을 탄 사람) 확인할 수 있습니다.
데이터 세트에 하나의 이미지만 공급하려고 하기 때문에 배치 크기를 1로 설정합니다. print(sess.run(features).shape)로 데이터의 차원을 확인할 수 있습니다. (1, 1024)와 같습니다. 1은 각각 1024개의 이미지 하나만 공급한다는 것을 의미합니다. 배치 크기를 XNUMX로 설정하면 두 개의 이미지가 파이프라인을 거칩니다. (배치 크기를 변경하지 마세요. 그렇지 않으면 오류가 발생합니다. 한 번에 하나의 이미지만 plot_image() 함수로 갈 수 있습니다.
## Parameters
n_inputs = 32 * 32
BATCH_SIZE = 1
batch_size = tf.placeholder(tf.int64)
# using a placeholder
x = tf.placeholder(tf.float32, shape=[None,n_inputs])
## Dataset
dataset = tf.data.Dataset.from_tensor_slices(x).repeat().batch(batch_size)
iter = dataset.make_initializable_iterator() # create the iterator
features = iter.get_next()
## Print the image
with tf.Session() as sess:
# feed the placeholder with data
sess.run(iter.initializer, feed_dict={x: horse_x,
batch_size: BATCH_SIZE})
print(sess.run(features).shape)
plot_image(sess.run(features), shape=[32, 32], cmap = "Greys_r")
(1, 1024)

네트워크 구축
이제 네트워크를 구축할 차례입니다. 여러 개의 숨겨진 레이어가 있는 네트워크인 누적 오토인코더를 훈련시킵니다.
네트워크에는 1024개의 포인트, 즉 이미지 모양인 32×32를 가진 하나의 입력 레이어가 있습니다.
인코더 블록에는 300개의 뉴런이 있는 하나의 상단 숨겨진 레이어와 150개의 뉴런이 있는 중앙 레이어가 있습니다. 디코더 블록은 인코더와 대칭입니다. 아래 그림에서 네트워크를 시각화할 수 있습니다. 숨겨진 레이어와 중앙 레이어의 값을 변경할 수 있습니다.
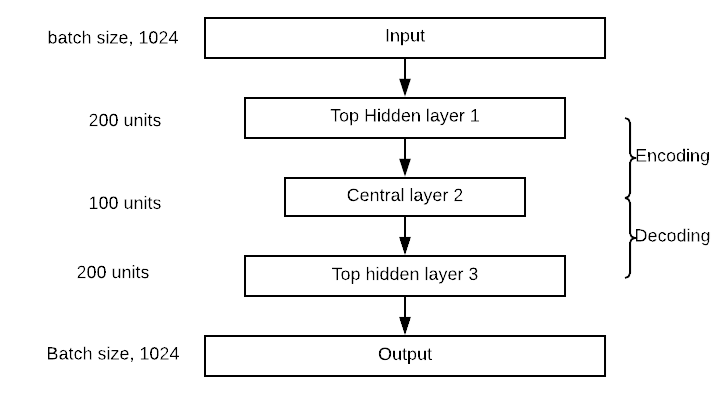
오토인코더 구축은 다른 딥러닝 모델과 매우 유사합니다.
다음 단계에 따라 모델을 구성합니다.
- 매개변수 정의
- 레이어 정의
- 아키텍처 정의
- 최적화 정의
- 모델 실행
- 모델 평가
이전 섹션에서는 모델에 공급할 파이프라인을 만드는 방법을 배웠으므로 데이터 세트를 한 번 더 만들 필요가 없습니다. 2개의 레이어로 구성된 오토인코더를 구성합니다. Xavier 초기화를 사용합니다. 이는 초기 가중치를 입력과 출력의 분산과 동일하게 설정하는 기술입니다. 마지막으로 elu 활성화 기능을 사용합니다. LXNUMX 정규화 도구를 사용하여 손실 함수를 정규화합니다.
단계 1) 매개변수 정의
첫 번째 단계는 각 계층의 뉴런 수, 학습률 및 정규화기의 하이퍼파라미터를 정의하는 것을 의미합니다.
그 전에 함수를 부분적으로 가져옵니다. dense 레이어의 매개변수를 정의하는 것이 더 나은 방법입니다. 아래 코드는 autoencoder 아키텍처의 값을 정의합니다. 앞서 나열한 대로 autoencoder에는 두 개의 레이어가 있으며, 첫 번째 레이어에는 300개의 뉴런이 있고 두 번째 레이어에는 150개의 뉴런이 있습니다. 해당 값은 n_hidden_1과 n_hidden_2에 저장됩니다.
학습률과 L2 하이퍼파라미터를 정의해야 합니다. 값은 learning_rate 및 l2_reg에 저장됩니다.
from functools import partial ## Encoder n_hidden_1 = 300 n_hidden_2 = 150 # codings ## Decoder n_hidden_3 = n_hidden_1 n_outputs = n_inputs learning_rate = 0.01 l2_reg = 0.0001
Xavier 초기화 기술은 추정기 contrib의 xavier_initializer 개체와 함께 호출됩니다. 동일한 추정기에서 l2_regularizer를 사용하여 정규화 도구를 추가할 수 있습니다.
## Define the Xavier initialization xav_init = tf.contrib.layers.xavier_initializer() ## Define the L2 regularizer l2_regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
단계 2) 레이어 정의
조밀한 레이어의 모든 매개변수가 설정되었습니다. 객체 부분을 사용하여density_layer 변수에 모든 것을 담을 수 있습니다. ELU 활성화, Xavier 초기화 및 L2 정규화를 사용하는density_layer.
## Create the dense layer
dense_layer = partial(tf.layers.dense,
activation=tf.nn.elu,
kernel_initializer=xav_init,
kernel_regularizer=l2_regularizer)
단계 3) 아키텍처 정의
아키텍처의 그림을 보면 네트워크가 출력 레이어가 있는 300개의 레이어를 쌓았다는 것을 알 수 있습니다. 아래 코드에서 적절한 레이어를 연결합니다. 예를 들어, 첫 번째 레이어는 입력 행렬 피처와 2개의 가중치를 포함하는 행렬 간의 점곱을 계산합니다. 점곱이 계산된 후 출력은 Elu 활성화 함수로 이동합니다. 출력은 다음 레이어의 입력이 되므로 hidden_XNUMX 등을 계산하는 데 사용합니다. 동일한 활성화 함수를 사용하기 때문에 각 레이어의 행렬 곱셈은 동일합니다. 마지막 레이어인 출력은 활성화 함수를 적용하지 않는다는 점에 유의하세요. 이는 재구성된 입력이기 때문에 의미가 있습니다.
## Make the mat mul hidden_1 = dense_layer(features, n_hidden_1) hidden_2 = dense_layer(hidden_1, n_hidden_2) hidden_3 = dense_layer(hidden_2, n_hidden_3) outputs = dense_layer(hidden_3, n_outputs, activation=None)
단계 4) 최적화 정의
마지막 단계는 옵티마이저를 구성하는 것입니다. 평균 제곱 오류를 손실 함수로 사용합니다. 선형 회귀에 대한 튜토리얼을 떠올려 보면 MSE가 예측 출력과 실제 레이블 간의 차이로 계산된다는 것을 알 수 있습니다. 여기서 모델은 입력을 재구성하려고 시도하므로 레이블이 특징입니다. 따라서 예측된 출력과 입력 사이의 제곱의 차이 합계의 평균이 필요합니다. TensorFlow를 사용하면 다음과 같이 손실 함수를 코딩할 수 있습니다.
loss = tf.reduce_mean(tf.square(outputs - features))
그런 다음 손실 함수를 최적화해야 합니다. Adam 최적화 프로그램을 사용하여 기울기를 계산합니다. 목적 함수는 손실을 최소화하는 것입니다.
## Optimize loss = tf.reduce_mean(tf.square(outputs - features)) optimizer = tf.train.AdamOptimizer(learning_rate) train = optimizer.minimize(loss)
모델을 훈련하기 전에 설정이 하나 더 있습니다. 150의 배치 크기를 사용하려고 합니다. 즉, 반복할 때마다 150개의 이미지를 파이프라인에 공급하려고 합니다. 반복 횟수를 수동으로 계산해야 합니다. 이는 간단한 작업입니다.
매번 150개의 이미지를 전달하고 데이터 세트에 5000개의 이미지가 있다는 것을 알고 있다면 반복 횟수는 . 파이썬에서 다음 코드를 실행하고 출력이 33인지 확인할 수 있습니다.
BATCH_SIZE = 150 ### Number of batches : length dataset / batch size n_batches = horse_x.shape[0] // BATCH_SIZE print(n_batches) 33
단계 5) 모델 실행
마지막으로 모델을 훈련시키세요. 100개의 에포크로 모델을 훈련하고 있습니다. 즉, 모델은 최적화된 가중치로 이미지의 100배를 보게 됩니다.
당신은 Tensorflow에서 모델을 훈련시키는 코드에 이미 익숙합니다. 약간의 차이점은 훈련을 실행하기 전에 데이터를 파이프하는 것입니다. 이런 방식으로 모델이 더 빠르게 학습됩니다.
모델이 무엇인가 학습하고 있는지(즉, 손실이 감소하고 있는지) 확인하기 위해 2개의 에포크 후에 손실을 인쇄하는 데 관심이 있습니다. 훈련은 기계 하드웨어에 따라 5~XNUMX분 정도 소요됩니다.
## Set params
n_epochs = 100
## Call Saver to save the model and re-use it later during evaluation
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# initialise iterator with train data
sess.run(iter.initializer, feed_dict={x: horse_x,
batch_size: BATCH_SIZE})
print('Training...')
print(sess.run(features).shape)
for epoch in range(n_epochs):
for iteration in range(n_batches):
sess.run(train)
if epoch % 10 == 0:
loss_train = loss.eval() # not shown
print("\r{}".format(epoch), "Train MSE:", loss_train)
#saver.save(sess, "./my_model_all_layers.ckpt")
save_path = saver.save(sess, "./model.ckpt")
print("Model saved in path: %s" % save_path)
Training...
(150, 1024)
0 Train MSE: 2934.455
10 Train MSE: 1672.676
20 Train MSE: 1514.709
30 Train MSE: 1404.3118
40 Train MSE: 1425.058
50 Train MSE: 1479.0631
60 Train MSE: 1609.5259
70 Train MSE: 1482.3223
80 Train MSE: 1445.7035
90 Train MSE: 1453.8597
Model saved in path: ./model.ckpt
단계 6) 모델 평가
이제 모델을 훈련시켰으므로 모델을 평가할 차례입니다. /cifar-10-batches-py/ 파일에서 테스트 세트를 가져와야 합니다.
test_data = unpickle('./cifar-10-batches-py/test_batch')
test_x = grayscale(test_data['data'])
#test_labels = np.array(test_data['labels'])
주의사항: Windows 컴퓨터에서 코드는 test_data = unpickle(r”E:\cifar-10-batches-py\test_batch”)가 됩니다.
말인 이미지 13을 인쇄해 볼 수 있습니다.
plot_image(test_x[13], shape=[32, 32], cmap = "Greys_r")

모델을 평가하기 위해 이 이미지의 픽셀 값을 사용하고 인코더가 1024픽셀을 축소한 후 동일한 이미지를 재구성할 수 있는지 확인합니다. 다양한 그림에서 모델을 평가하는 함수를 정의합니다. 모델은 말에서만 더 잘 작동합니다.
이 함수는 두 가지 인수를 사용합니다.
- df: 테스트 데이터 가져오기
- 이미지 번호: 가져올 이미지를 나타냅니다.
이 기능은 세 부분으로 나누어집니다:
- 이미지를 올바른 크기(예: 1, 1024)로 변경합니다.
- 보이지 않는 이미지를 모델에 공급하고 이미지를 인코딩/디코딩합니다.
- 실제 이미지와 재구성된 이미지를 인쇄하세요.
def reconstruct_image(df, image_number = 1):
## Part 1: Reshape the image to the correct dimension i.e 1, 1024
x_test = df[image_number]
x_test_1 = x_test.reshape((1, 32*32))
## Part 2: Feed the model with the unseen image, encode/decode the image
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(iter.initializer, feed_dict={x: x_test_1,
batch_size: 1})
## Part 3: Print the real and reconstructed image
# Restore variables from disk.
saver.restore(sess, "./model.ckpt")
print("Model restored.")
# Reconstruct image
outputs_val = outputs.eval()
print(outputs_val.shape)
fig = plt.figure()
# Plot real
ax1 = fig.add_subplot(121)
plot_image(x_test_1, shape=[32, 32], cmap = "Greys_r")
# Plot estimated
ax2 = fig.add_subplot(122)
plot_image(outputs_val, shape=[32, 32], cmap = "Greys_r")
plt.tight_layout()
fig = plt.gcf()
이제 평가 함수가 정의되었으므로 재구성된 이미지 번호 XNUMX을 볼 수 있습니다.
reconstruct_image(df =test_x, image_number = 13)
INFO:tensorflow:Restoring parameters from ./model.ckpt Model restored. (1, 1024)

제품 개요
- 오토인코더의 주요 목적은 입력 데이터를 압축한 다음 압축을 풀어 원본 데이터와 매우 유사한 출력으로 만드는 것입니다.
- 중앙 층이라 명명된 피벗 층을 기준으로 대칭적인 자동 인코더의 아키텍처입니다.
- 다음을 사용하여 자동 인코더를 만들 수 있습니다.
일부의: 일반적인 설정으로 조밀한 레이어를 생성하려면:
tf.layers.dense, activation=tf.nn.elu, kernel_initializer=xav_init, kernel_regularizer=l2_regularizer
밀도층(): 행렬 곱셈을 하기 위해
loss = tf.reduce_mean(tf.square(outputs - features)) optimizer = tf.train.AdamOptimizer(learning_rate) train = optimizer.minimize(loss)