TensorFlow のオートエンコーダーと例
ディープラーニングにおけるオートエンコーダーとは何ですか?
An オートエンコーダー は、教師なしの方法でデータ コーディングを効率的に学習するためのツールです。 これは、信号ノイズを無視するようにニューラル ネットワークをトレーニングすることで、次元削減のためのデータ セットの表現を学習するのに役立つ人工ニューラル ネットワークの一種です。 これは入力を再作成するための優れたツールです。
簡単に言うと、機械は、たとえば画像を取得し、密接に関連した画像を生成できます。 この種のニューラル ネットワークの入力にはラベルが付けられていません。これは、ネットワークが監視なしで学習できることを意味します。 より正確には、入力はネットワークによってエンコードされ、最も重要な機能のみに焦点が当てられます。 これが、次元削減のためにオートエンコーダが人気がある理由の XNUMX つです。 さらに、オートエンコーダーを使用して 生成学習モデル。 たとえば、ニューラル ネットワークは一連の顔でトレーニングされ、新しい顔を生成できます。
TensorFlow Autoencoder はどのように機能しますか?
オートエンコーダーの目的は、重要な特徴のみに焦点を当てて入力の近似値を生成することです。 入力をコピーして貼り付けて出力を生成する方法を単に学習すればよいのではないかと思うかもしれません。 実際、オートエンコーダは、単に出力をコピーするのとは異なる、データを表現するための新しい方法をネットワークに学習させる一連の制約です。
一般的なオートエンコーダは、入力、内部表現、および出力 (入力の近似) で定義されます。 学習は、内部表現に関連付けられた層で行われます。 実際、従来のニューラル ネットワークのように見える層には XNUMX つの主要なブロックがあります。 わずかな違いは、出力を含むレイヤーが入力と等しくなければならないことです。 下の図では、元の入力は、 エンコーダ。 この内部表現により、入力のサイズが圧縮 (縮小) されます。 XNUMX 番目のブロックでは、入力の再構築が行われます。 これがデコード段階です。

モデルは損失関数を最小化することによって重みを更新します。 再構成出力が入力と異なる場合、モデルにはペナルティが課されます。
具体的には、サイズが 50×50 (つまり 250 ピクセル) の画像と、250 個のニューロンで構成される 100 つの隠れ層だけを持つニューラル ネットワークを想像してください。 学習は、入力の XNUMX 倍小さい特徴マップ上で行われます。 これは、ネットワークが XNUMX に等しいニューロンのベクトルのみを使用して XNUMX ピクセルを再構成する方法を見つける必要があることを意味します。
スタック型オートエンコーダーの例
このオートエンコーダのチュートリアルでは、スタック オートエンコーダの使い方を学習します。アーキテクチャは従来のニューラル ネットワークに似ています。入力は、圧縮またはサイズ縮小のために隠し層に送られ、その後再構成層に到達します。目的は、元の画像にできるだけ近い出力画像を生成することです。モデルは、一連の制約の下で、つまりより低い次元でタスクを達成する方法を学習する必要があります。
現在、オートエンコーダーは、 深層学習 主に画像のノイズを除去するために使用されます。 傷のある画像を想像してください。 人間は依然として内容を認識できます。 ノイズ除去オートエンコーダーのアイデアは、画像にノイズを追加して、ネットワークにデータの背後にあるパターンを強制的に学習させることです。
オートエンコーダー深層学習のもう XNUMX つの便利なファミリーは、変分オートエンコーダーです。 このタイプのネットワークでは、新しいイメージを生成できます。 男性のイメージを使用してネットワークをトレーニングすると想像してください。 このようなネットワークは新しい顔を生み出す可能性があります。
TensorFlow を使用してオートエンコーダーを構築する方法
このチュートリアルでは、画像を再構築するためのスタック型オートエンコーダーを構築する方法を学びます。
を使用します CIFAR-10データセット 60000 個の 32×32 カラー画像が含まれています。 Autoencoder データセットは、トレーニング用の 50000 個の画像とテスト用の 10000 個の画像にすでに分割されています。 最大 XNUMX 個のクラスがあります。
- 飛行機
- 自動車
- 鳥
- ネコ
- 鹿
- 犬
- カエル
- うま
- 船
- トラック
この URL https://www.cs.toronto.edu/~kriz/cifar.html にある画像をダウンロードして解凍する必要があります。 for-10-batches-py フォルダーには、それぞれ 10000 個の画像を含む XNUMX つのデータ バッチがランダムな順序で含まれています。
モデルを構築してトレーニングする前に、いくつかのデータ処理を適用する必要があります。 次のように進めます。
- データをインポートする
- データを白黒形式に変換します
- すべてのバッチを追加する
- トレーニング データセットを構築する
- 画像ビジュアライザを構築する
画像の前処理
ステップ 1) データをインポートする
公式サイトによると、次のコードでデータをアップロードできる。オートエンコーダーコードは、辞書にデータをロードし、 データ と ラベル。 コードは関数であることに注意してください。
import numpy as np
import tensorflow as tf
import pickle
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='latin1')
return dict
ステップ 2) データを白黒形式に変換します
簡単にするために、データをグレースケールに変換します。 つまり、カラー画像の場合は XNUMX 次元に対して XNUMX 次元のみです。 ほとんどのニューラル ネットワークは XNUMX 次元の入力でのみ機能します。
def grayscale(im):
return im.reshape(im.shape[0], 3, 32, 32).mean(1).reshape(im.shape[0], -1)
ステップ 3) すべてのバッチを追加する
両方の関数が作成され、データセットがロードされたので、メモリにデータを追加するループを作成できます。 よく確認すると、データを含む解凍ファイルの名前は data_batch_ で、1 から 5 までの番号が付いています。ファイルをループしてデータに追加できます。
この手順が完了すると、カラー データがグレー スケール形式に変換されます。 ご覧のとおり、データの形状は 50000 と 1024 です。32*32 ピクセルは 2014 に平坦化されました。
# Load the data into memory
data, labels = [], []
## Loop over the b
for i in range(1, 6):
filename = './cifar-10-batches-py/data_batch_' + str(i)
open_data = unpickle(filename)
if len(data) > 0:
data = np.vstack((data, open_data['data']))
labels = np.hstack((labels, open_data['labels']))
else:
data = open_data['data']
labels = open_data['labels']
data = grayscale(data)
x = np.matrix(data)
y = np.array(labels)
print(x.shape)
(50000, 1024)
注: 「./cifar-10-batches-py/data_batch_」をファイルの実際の場所に変更します。たとえば、 Windows マシンの場合、パスは filename = 'E:\cifar-10-batches-py\data_batch_' + str(i) になります。
ステップ 4) トレーニング データセットを構築する
トレーニングをより迅速かつ簡単に行うために、馬の画像のみでモデルをトレーニングします。 ラベルデータでは10級クラスの馬です。 CIFAR-5000 データセットのドキュメントで説明されているように、各クラスには 5.000 個の画像が含まれています。 以下に示すように、データの形状を印刷して、1024 列の XNUMX 個の画像があることを確認できます。 TensorFlow オートエンコーダのサンプルステップ。
horse_i = np.where(y == 7)[0] horse_x = x[horse_i] print(np.shape(horse_x)) (5000, 1024)
ステップ 5) 画像ビジュアライザを構築する
最後に、画像をプロットする関数を構築します。 オートエンコーダーから再構成されたイメージを印刷するには、この関数が必要になります。
画像を印刷する簡単な方法は、matplotlib ライブラリのオブジェクト imshow を使用することです。 データの形状を 1024 から 32*32 (つまり画像の形式) に変換する必要があることに注意してください。
# To plot pretty figures
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
def plot_image(image, shape=[32, 32], cmap = "Greys_r"):
plt.imshow(image.reshape(shape), cmap=cmap,interpolation="nearest")
plt.axis("off")
この関数は 3 つの引数を取ります。
- 画像: 入力
- 形状: リスト、画像の寸法
- cmap:カラーマップを選択します。 デフォルトではグレー
データセット内の最初の画像をプロットしてみることができます。 馬に乗った男性が見えるはずです。
plot_image(horse_x[1], shape=[32, 32], cmap = "Greys_r")

データセット推定器の設定
データセットを使用する準備ができたので、Tensorflow の使用を開始できます。 モデルを構築する前に、Tensorflow のデータセット推定器を使用してネットワークにフィードしましょう。
TensorFlow エスティメーターを使用してデータセットを構築します。 心をリフレッシュするには、以下を使用する必要があります。
- from_tensor_slices
- 繰り返す
- バッチ
データセットを構築するための完全なコードは次のとおりです。
dataset = tf.data.Dataset.from_tensor_slices(x).repeat().batch(batch_size)
x は次の形状のプレースホルダーであることに注意してください。
- [None,n_inputs]: ネットワークへの画像フィードの数がバッチ サイズと等しいため、None に設定されます。
詳細については、チュートリアルを参照してください。 線形回帰。
その後、イテレータを作成する必要があります。 このコード行がないと、データはパイプラインを通過しません。
iter = dataset.make_initializable_iterator() # create the iteratorfeatures = iter.get_next()
パイプラインの準備ができたので、最初の画像が以前と同じかどうか (つまり、馬に乗った男性) を確認できます。
データセットに 1 つの画像のみをフィードするため、バッチ サイズを 1 に設定します。データの次元は print(sess.run(features).shape) で確認できます。これは (1024, 1) に等しくなります。1024 は、XNUMX の画像が XNUMX つだけフィードされることを意味します。バッチ サイズを XNUMX に設定すると、XNUMX つの画像がパイプラインを通過します (バッチ サイズを変更しないでください。変更すると、エラーが発生します。関数 plot_image() に一度に渡せる画像は XNUMX つだけです)。
## Parameters
n_inputs = 32 * 32
BATCH_SIZE = 1
batch_size = tf.placeholder(tf.int64)
# using a placeholder
x = tf.placeholder(tf.float32, shape=[None,n_inputs])
## Dataset
dataset = tf.data.Dataset.from_tensor_slices(x).repeat().batch(batch_size)
iter = dataset.make_initializable_iterator() # create the iterator
features = iter.get_next()
## Print the image
with tf.Session() as sess:
# feed the placeholder with data
sess.run(iter.initializer, feed_dict={x: horse_x,
batch_size: BATCH_SIZE})
print(sess.run(features).shape)
plot_image(sess.run(features), shape=[32, 32], cmap = "Greys_r")
(1, 1024)

ネットワークを構築する
ネットワークを構築する時が来ました。 スタック型オートエンコーダー、つまり複数の隠れ層を持つネットワークをトレーニングします。
ネットワークには、1024 個のポイント (つまり 32 × 32) の画像形状を持つ入力レイヤーが XNUMX つあります。
エンコーダ ブロックには、300 ニューロンを含む最上位の隠れ層が 150 つと、XNUMX ニューロンを含む中央層があります。 デコーダ ブロックはエンコーダに対して対称です。 以下の図でネットワークを視覚化できます。 非表示レイヤーと中央レイヤーの値は変更できることに注意してください。
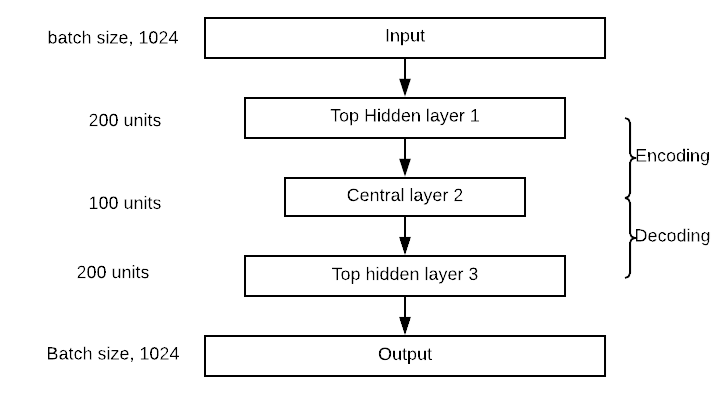
オートエンコーダーの構築は、他の深層学習モデルと非常に似ています。
次の手順に従ってモデルを構築します。
- パラメータを定義する
- レイヤーを定義する
- アーキテクチャを定義する
- 最適化を定義する
- モデルを実行する
- モデルを評価する
前のセクションでは、モデルにフィードするパイプラインを作成する方法を学習したため、データセットを再度作成する必要はありません。 2 つのレイヤーでオートエンコーダーを構築します。 Xavier 初期化を使用します。 これは、入力と出力の両方の分散に等しい初期重みを設定する手法です。 最後に、elu アクティベーション関数を使用します。 LXNUMX 正則化機能を使用して損失関数を正規化します。
ステップ1) パラメータを定義する
最初のステップでは、各層のニューロンの数、学習率、および正則化子のハイパーパラメーターを定義することを意味します。
その前に、関数を部分的にインポートします。密な層のパラメータを定義する方がよい方法です。以下のコードは、オートエンコーダ アーキテクチャの値を定義します。前述のように、オートエンコーダには 300 つの層があり、最初の層には 150 個のニューロンがあり、1 番目の層には 2 個のニューロンがあります。それらの値は n_hidden_XNUMX と n_hidden_XNUMX に格納されます。
学習率と L2 ハイパーパラメータを定義する必要があります。 値は learning_rate と l2_reg に格納されます。
from functools import partial ## Encoder n_hidden_1 = 300 n_hidden_2 = 150 # codings ## Decoder n_hidden_3 = n_hidden_1 n_outputs = n_inputs learning_rate = 0.01 l2_reg = 0.0001
Xavier 初期化手法は、推定器 contrib のオブジェクト xavier_initializer を使用して呼び出されます。 同じ推定器で、l2_regulatoryizer を使用して正則化子を追加できます。
## Define the Xavier initialization xav_init = tf.contrib.layers.xavier_initializer() ## Define the L2 regularizer l2_regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
ステップ2) レイヤーを定義する
高密度レイヤーのすべてのパラメーターが設定されました。 オブジェクト パーシャルを使用すると、変数 Density_layer にすべてを詰め込むことができます。 これは、ELU のアクティブ化、Xavier の初期化、および L2 正則化を使用します。
## Create the dense layer
dense_layer = partial(tf.layers.dense,
activation=tf.nn.elu,
kernel_initializer=xav_init,
kernel_regularizer=l2_regularizer)
ステップ3) アーキテクチャを定義する
アーキテクチャの図を見ると、ネットワークが出力層を含む 300 つの層を積み重ねていることがわかります。以下のコードでは、適切な層を接続します。たとえば、最初の層は、入力マトリックス機能と 2 個の重みを含むマトリックス間のドット積を計算します。ドット積が計算された後、出力は Elu 活性化関数に送られます。出力は次の層の入力になります。そのため、hidden_XNUMX の計算に使用します。同じ活性化関数を使用するため、各層のマトリックス乗算は同じです。最後の層である出力は活性化関数を適用しないことに注意してください。これは、再構成された入力であるため、理にかなっています。
## Make the mat mul hidden_1 = dense_layer(features, n_hidden_1) hidden_2 = dense_layer(hidden_1, n_hidden_2) hidden_3 = dense_layer(hidden_2, n_hidden_3) outputs = dense_layer(hidden_3, n_outputs, activation=None)
ステップ4) 最適化を定義する
最後のステップは、オプティマイザーを構築することです。 損失関数として平均二乗誤差を使用します。 線形回帰に関するチュートリアルを思い出した場合、MSE は予測された出力と実際のラベルの差を使用して計算されることがわかります。 ここで、モデルは入力を再構築しようとするため、ラベルが特徴です。 したがって、予測された出力と入力の間の二乗の差の合計の平均が必要になります。 TensorFlow を使用すると、次のように損失関数をコーディングできます。
loss = tf.reduce_mean(tf.square(outputs - features))
次に、損失関数を最適化する必要があります。 勾配を計算するには、Adam オプティマイザーを使用します。 目的関数は損失を最小限に抑えることです。
## Optimize loss = tf.reduce_mean(tf.square(outputs - features)) optimizer = tf.train.AdamOptimizer(learning_rate) train = optimizer.minimize(loss)
モデルをトレーニングする前にもう 150 つの設定を行います。 バッチ サイズ 150 を使用します。つまり、反復ごとに XNUMX 枚の画像をパイプラインにフィードします。 反復回数を手動で計算する必要があります。 これを行うのは簡単です:
毎回 150 枚の画像を渡し、データセットに 5000 枚の画像があることがわかっている場合、反復回数は になります。Python では、次のコードを実行して、出力が 33 であることを確認できます。
BATCH_SIZE = 150 ### Number of batches : length dataset / batch size n_batches = horse_x.shape[0] // BATCH_SIZE print(n_batches) 33
ステップ5) モデルを実行する
最後になりましたが、モデルをトレーニングします。 100 エポックでモデルをトレーニングしています。 つまり、モデルは最適化された重みに対して 100 倍の画像を見ることになります。
Tensorflow でモデルをトレーニングするコードについてはすでに理解しています。 わずかな違いは、トレーニングを実行する前にデータをパイプすることです。 このようにして、モデルのトレーニングが高速化されます。
モデルが何かを学習している (つまり、損失が減少している) かどうかを確認するために、2 エポック後の損失を出力することに興味があります。 マシンのハードウェアに応じて、トレーニングには 5 ~ XNUMX 分かかります。
## Set params
n_epochs = 100
## Call Saver to save the model and re-use it later during evaluation
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# initialise iterator with train data
sess.run(iter.initializer, feed_dict={x: horse_x,
batch_size: BATCH_SIZE})
print('Training...')
print(sess.run(features).shape)
for epoch in range(n_epochs):
for iteration in range(n_batches):
sess.run(train)
if epoch % 10 == 0:
loss_train = loss.eval() # not shown
print("\r{}".format(epoch), "Train MSE:", loss_train)
#saver.save(sess, "./my_model_all_layers.ckpt")
save_path = saver.save(sess, "./model.ckpt")
print("Model saved in path: %s" % save_path)
Training...
(150, 1024)
0 Train MSE: 2934.455
10 Train MSE: 1672.676
20 Train MSE: 1514.709
30 Train MSE: 1404.3118
40 Train MSE: 1425.058
50 Train MSE: 1479.0631
60 Train MSE: 1609.5259
70 Train MSE: 1482.3223
80 Train MSE: 1445.7035
90 Train MSE: 1453.8597
Model saved in path: ./model.ckpt
ステップ6) モデルを評価する
モデルをトレーニングしたので、今度はそれを評価します。 ファイル /cifar-10-batches-py/ からテスト sert をインポートする必要があります。
test_data = unpickle('./cifar-10-batches-py/test_batch')
test_x = grayscale(test_data['data'])
#test_labels = np.array(test_data['labels'])
注意: のために Windows マシンの場合、コードは test_data = unpickle(r”E:\cifar-10-batches-py\test_batch”) になります。
馬の画像13を印刷してみてください。
plot_image(test_x[13], shape=[32, 32], cmap = "Greys_r")

モデルを評価するには、この画像のピクセル値を使用し、エンコーダーが 1024 ピクセルを縮小した後に同じ画像を再構築できるかどうかを確認します。 さまざまな画像でモデルを評価する関数を定義することに注意してください。 このモデルは馬に対してのみ適切に機能するはずです。
この関数は XNUMX つの引数を取ります。
- df: テストデータをインポートします
- 画像番号: インポートする画像を指定します
この機能は XNUMX つの部分に分かれています。
- 画像を正しい寸法(1、1024)に再形成します。
- モデルに目に見えない画像をフィードし、画像をエンコード/デコードします
- 実際の画像と再構成された画像を印刷します
def reconstruct_image(df, image_number = 1):
## Part 1: Reshape the image to the correct dimension i.e 1, 1024
x_test = df[image_number]
x_test_1 = x_test.reshape((1, 32*32))
## Part 2: Feed the model with the unseen image, encode/decode the image
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(iter.initializer, feed_dict={x: x_test_1,
batch_size: 1})
## Part 3: Print the real and reconstructed image
# Restore variables from disk.
saver.restore(sess, "./model.ckpt")
print("Model restored.")
# Reconstruct image
outputs_val = outputs.eval()
print(outputs_val.shape)
fig = plt.figure()
# Plot real
ax1 = fig.add_subplot(121)
plot_image(x_test_1, shape=[32, 32], cmap = "Greys_r")
# Plot estimated
ax2 = fig.add_subplot(122)
plot_image(outputs_val, shape=[32, 32], cmap = "Greys_r")
plt.tight_layout()
fig = plt.gcf()
評価関数が定義されたので、再構成された画像番号 XNUMX を確認できます。
reconstruct_image(df =test_x, image_number = 13)
INFO:tensorflow:Restoring parameters from ./model.ckpt Model restored. (1, 1024)

製品概要
- オートエンコーダーの主な目的は、入力データを圧縮し、それを元のデータによく似た出力に解凍することです。
- 中央層と呼ばれるピボット層と対称的なオートエンコーダのアーキテクチャ。
- 以下を使用してオートエンコーダーを作成できます。
一部: 一般的な設定で密なレイヤーを作成するには:
tf.layers.dense, activation=tf.nn.elu, kernel_initializer=xav_init, kernel_regularizer=l2_regularizer
密な層(): 行列の乗算を行う
loss = tf.reduce_mean(tf.square(outputs - features)) optimizer = tf.train.AdamOptimizer(learning_rate) train = optimizer.minimize(loss)