10 Migliori dati di prova Generator Strumenti (2026)

Ti sei mai sentito bloccato quando strumenti di scarsa qualità rallentano il tuo processo di testing? Scegliere quelli sbagliati spesso porta a set di dati inaffidabili, lunghe correzioni manuali, frequenti errori nei flussi di lavoro e persino discrepanze nei dati che fanno deragliare interi progetti. Può anche causare rischi di conformità, copertura di test incoerente, spreco di risorse e rilavorazioni inutili. Questi problemi generano frustrazione e riducono la produttività. D'altro canto, gli strumenti giusti semplificano il processo, migliorano l'accuratezza e fanno risparmiare tempo prezioso.
ho speso nel giro di ore 180 ricercando e confrontando attentamente Oltre 40 strumenti per la generazione di dati di test Prima di creare questa guida, ho selezionato le 12 opzioni più efficaci. Questa recensione è supportata dalla mia esperienza diretta e pratica con questi strumenti. In questo articolo, ne condivido le caratteristiche principali, i pro e i contro e i prezzi per offrirti la massima chiarezza. Assicurati di leggere fino alla fine per scegliere la soluzione più adatta alle tue esigenze. Per saperne di più ...
Migliori Test Data Generator Strumenti: i migliori!
| Dati di test Generator Chiavetta | Funzionalità principali | Prova gratuita / Garanzia | vetro |
|---|---|---|---|
| EMS Data Generator | Supporto tipo JSON, migrazione DB, codifica dati | Prova gratuita di 30-day | Scopri di Più |
| Informatica TDM | Mascheramento automatico dei dati sensibili, Acceleratori predefiniti, Report di conformità | Demo gratuita disponibile | Scopri di Più |
| Doppio | Supervisione rigorosa, integrazione API del database, governance dei dati | Richiedi una Demo | Scopri di Più |
| Broadcom EDMS | Scansione PII unificata, mascheramento scalabile su set di dati di grandi dimensioni, supporto per database NoSQL | Richiedi una Demo | Scopri di Più |
| SAP Test Data Migration Server | Funzionalità Snapshot, Parallelizzazione della selezione dei dati, Creazione di Active Shell | Richiedi una Demo | Scopri di Più |
1) EMS Data Generator
EMS Data Generator è uno strumento intuitivo, studiato appositamente per generare dati sintetici su più tabelle di database contemporaneamente. Ho apprezzato la facilità con cui mi ha permesso di configurare set di dati randomizzati e di visualizzare in anteprima i risultati prima dell'uso. Le sue capacità di generazione basate su schema e l'ampio supporto per tipi di dati come ENUM, SET e JSON renderlo sufficientemente flessibile da gestire diverse esigenze di test.
In un caso, ho fatto leva EMS Data Generator per il seeding dei database di test durante un progetto di migrazione, semplificando il processo senza compromettere l'accuratezza dei dati. La capacità dello strumento di generare set di dati parametrizzati e salvarli come script SQL garantisce test fluidi, rendendolo una scelta affidabile per gli amministratori di database e gli ingegneri del controllo qualità che gestiscono carichi di lavoro sia di piccole dimensioni che di livello aziendale.
Caratteristiche:
- Codifica dei dati: Questa funzionalità consente di gestire diverse opzioni di codifica in modo fluido, il che è fondamentale quando si lavora in più ambienti. Supporta i file Unicode, quindi anche i dati di test multilingue vengono gestiti senza problemi. L'ho utilizzata per gestire gli script senza problemi e i risultati sono sempre stati coerenti.
- Installazione del programma: Inserisce in modo pratico i dati di test generati nei pacchetti di installazione, garantendo che tutto rimanga disponibile per un utilizzo immediato. Ho trovato questa funzionalità estremamente utile per configurare rapidamente gli ambienti su nuovi sistemi. Durante i test, ho notato quanto riducesse le attività di configurazione ripetitive.
- Migrazione del database: È possibile migrare facilmente tra sistemi di database senza preoccuparsi di perdere informazioni critiche. Mi ha aiutato a trasferire grandi set di dati da MySQL a PostgreSQL senza intoppi. Consiglierei di controllare attentamente i log di migrazione per verificare la compatibilità dello schema prima di procedere alla distribuzione in produzione.
- Supporto per il tipo di dati JSON: Supporta i tipi di dati JSON per database popolari come Oracle 21c, MySQL 8, Firebird 4 e PostgreSQL 16Questo lo rende a prova di futuro per le applicazioni moderne che si basano sull'archiviazione di documenti. In un caso, l'ho utilizzato per convalidare scenari di test API generando JSON direttamente nel database.
- Supporto per tipi di dati complessi: Oltre ai campi standard, lo strumento gestisce i tipi SET, ENUM e GEOMETRY, il che rappresenta un grande vantaggio per i modelli di database avanzati. Ho testato questa funzionalità durante la modellazione di dataset basati sulla posizione geografica e ha funzionato perfettamente senza richiedere modifiche manuali.
- Anteprima e modifica dei dati generati: Questa funzionalità consente di visualizzare in anteprima e modificare i dati generati prima di finalizzarli, risparmiando tempo durante il debug. Lo strumento consente di salvare le modifiche direttamente negli script SQL, semplificando l'integrazione nelle pipeline CI/CD. Suggerisco di utilizzare il controllo di versione per questi script per mantenere la riproducibilità tra le esecuzioni di test.
Pro
Contro
Prezzi:
Ecco alcuni dei piani di partenza offerti da EMS Data Generator
| EMS Data Generator per InterBase/Firebird (Business) + 1 anno di manutenzione | EMS Data Generator per Oracle (Business) + 1 anno di manutenzione | EMS Data Generator per SQL Server (Business) + 1 anno di manutenzione |
|---|---|---|
| $110 | $110 | $110 |
Prova gratuita: 30 giorni di prova
2) Informatica Test Data Management
Informatica Test Data Management è una delle soluzioni più avanzate con cui abbia mai lavorato per la creazione di dati sintetici e una protezione affidabile. Sono rimasto colpito dalla fluidità con cui ha automatizzato l'identificazione e il mascheramento dei dati su database complessi, risparmiandomi lunghi controlli manuali. La possibilità di mascherare i dati sensibili mantenendo l'integrità dello schema mi ha dato la sicurezza di soddisfare i requisiti di conformità senza rallentare i progetti.
L'ho trovato particolarmente utile nella preparazione di set di dati parametrici per casi di test automatizzati, poiché mi ha permesso di creare sottoinsiemi senza sovraccaricare l'infrastruttura. Questo approccio non solo ha migliorato le prestazioni, ma ha anche reso i cicli di test più rapidi ed economici. Informatica TDM eccelle davvero nella gestione di dati di produzione sensibili che necessitano di mascheramento e riutilizzo per ambienti di test sicuri.
Caratteristiche:
- Identificazione automatica dei dati: Questa funzionalità identifica rapidamente i dati sensibili su più database, semplificando notevolmente la gestione della conformità e della sicurezza. Applica costantemente il mascheramento, garantendo che nessun dato grezzo venga esposto durante i test. Ho trovato questa funzionalità particolarmente utile quando lavoravo con set di dati sanitari, dove la conformità HIPAA era imprescindibile.
- Sottoinsieme di dati: È possibile creare sottoinsiemi di dati più piccoli e di alto valore che velocizzano l'esecuzione dei test riducendo al contempo i costi infrastrutturali. Questa funzionalità è estremamente utile per i test di regressione, in cui esecuzioni ripetute richiedono un rapido accesso a set di dati coerenti. Utilizzando questa soluzione, ho notato che i cicli di test sono diventati più efficienti, con un minore carico di lavoro sul sistema.
- Acceleratori pre-costruiti: Include acceleratori di mascheramento integrati per elementi di dati comuni, aiutandoti a rimanere conforme senza dover reinventare la ruota. Questi acceleratori consentono di risparmiare tempo e migliorare l'affidabilità nella gestione di campi riservati come numeri di previdenza sociale o dati delle carte di credito. Suggerisco di esplorare opzioni di personalizzazione per formati di dati specifici del settore per massimizzare il valore.
- Monitoraggio e reporting: Questa funzione fornisce un monitoraggio dettagliato e reporting pronto per la revisione per il rischio e la conformità. Coinvolge direttamente i team di governance, aiutando ad allineare il controllo qualità con le policy aziendali sui dati. Consiglierei di pianificare report automatizzati nelle pipeline CI/CD in modo che i controlli di conformità diventino parte integrante dei test quotidiani, anziché una corsa all'ultimo minuto.
- Governance unificata dei dati: Garantisce l'applicazione di policy coerenti in tutta l'azienda, riducendo i rischi di conformità. Ho visto come questo aiuti le grandi organizzazioni a evitare compartimenti stagni, mantenendo al contempo dati accurati e affidabili.
- Intelligence automatizzata dei dati: Sfrutta l'automazione basata sull'intelligenza artificiale per fornire informazioni continue sull'utilizzo, la provenienza e la qualità dei dati. Questo non solo migliora la trasparenza, ma accelera anche il processo decisionale. Durante i test, ho notato che ha ridotto significativamente lo sforzo manuale di tracciamento delle origini e delle trasformazioni dei dati.
Pro
Contro
Prezzi:
- Prezzo: Puoi richiedere un preventivo alle vendite
- Prova gratuita: Ottieni una demo gratuita
3) Doppio
Doble si distingue come una scelta pratica per le organizzazioni che necessitano di una gestione strutturata dei dati di test. Quando l'ho utilizzato per organizzare grandi quantità di dati randomizzati tra i vari reparti, ho notato quanto i test siano diventati più fluidi. Lo strumento semplifica la pulizia, la conversione e la categorizzazione dei dati, garantendo l'accuratezza nella gestione di piani di test diversi. La sua capacità di integrarsi con API e strumenti di business intelligence aggiunge un valore reale ai flussi di lavoro di test quotidiani.
Ho apprezzato il modo in cui ha semplificato i test sul campo consolidando i risultati in cartelle logiche, riducendo la confusione causata da set di dati sparsi. Avendo sperimentato la sua affidabilità nella gestione di dati di produzione mascherati, direi che Doble è particolarmente utile per i team che danno priorità alla coerenza e alla governance dei dati, riducendo al contempo il sovraccarico dell'organizzazione manuale.
Caratteristiche:
- Gestione dei dati: Questa funzionalità consente di gestire diversi tipi di dati di test, come SFRA e DTA, con coerenza. Aiuta a mantenere la produttività tra i progetti e supporta la generazione basata su schemi, ove necessario. Personalmente, l'ho utilizzata per creare modelli organizzati e riutilizzabili che riducono lo sforzo manuale.
- Supervisione rigorosa: Fornisce una supervisione per applicare solidi standard di governance dei dati. Questo non solo riduce i processi ridondanti ma migliora anche i flussi di lavoro compatibili con la conformità. Durante i test, ho notato quanto bene si integri nelle pipeline DevOps di livello aziendale, facilitando l'individuazione delle inefficienze prima che si aggravino.
- Governance dei dati: Questa funzionalità garantisce archiviazione e backup logici, mantenendo i dati di test strutturati e accessibili. Garantisce l'affidabilità negli scenari di test di performance e regressione. Consiglio di sfruttarla quando si lavora con dati di produzione mascherati, poiché semplifica l'audit mantenendo intatta la sicurezza.
- API del database: L'API Database offre un livello di servizio flessibile per il recupero di dati di test e risultati analitici come i punteggi FRANK™. Supporta l'integrazione con strumenti di BI, consentendo pipeline di reporting pronte per l'automazione. Suggerisco di utilizzarla per il supporto CI/CD, dove le informazioni sui dati devono essere costantemente disponibili.
- Processi standardizzati: Questa funzionalità si concentra sull'eliminazione di processi manuali e ridondanti standardizzando le modalità di raccolta e archiviazione dei dati. Garantisce la compatibilità multipiattaforma e riduce i rischi di flussi di lavoro frammentati. Ho visto risparmiare ore durante attività di convalida software su larga scala, in cui la copertura dei casi limite era fondamentale.
- Risorse di conoscenza e formazione: Doble fornisce accesso a guide strutturate e corsi di formazione che aiutano i team ad adottare le migliori pratiche. Ciò garantisce coerenza nel modo in cui vengono gestiti i dati di prova tra i vari dipartimenti. Inoltre, ho notato che il materiale didattico personalizzato velocizza l'adozione, anche in ambienti Agile-friendly.
Pro
Contro
Prezzi:
- Prezzo: Puoi richiedere un preventivo alle vendite
- Prova gratuita: Richiedi una Demo
4) Broadcom EDMS
Broadcom EDMS è una potente piattaforma per la generazione di dati di test che ho trovato particolarmente efficace nella creazione di dataset basati su schemi e regole. Ho apprezzato il modo in cui mi ha permesso di estrarre e riutilizzare i dati aziendali applicando regole di mascheramento che proteggevano le informazioni sensibili. Le sue funzioni di sottoinsieme, come eliminazione, inserimento e troncamento, offrivano un controllo preciso sulla creazione di dataset, rendendo i test più adattabili.
In uno scenario, l'ho utilizzato per generare set di dati randomizzati per i test delle API, garantendo la copertura dei casi limite senza esporre i dati di produzione. Il rilevamento su larga scala di fonti riservate, combinato con le opzioni di pianificazione, ha semplificato il mantenimento della conformità, velocizzando al contempo i casi di test automatizzati. Broadcom EDMS eccelle nel bilanciare la sicurezza di alto livello con la flessibilità nella preparazione dei dati.
Caratteristiche:
- Assistente dati Plus: Questa funzionalità crea dati sintetici realistici basati su schemi, utilizzando algoritmi basati su regole che imitano la logica di produzione senza esporre informazioni sensibili. Ho visto che accelera la preparazione dei casi di test, consentendo ai tester di simulare condizioni di errore rare senza dover attendere i dati di produzione.
- Flusso di lavoro unificato per la scansione, la mascheratura e l'audit dei dati personali identificativi: Individua, classifica e gestisce in modo sicuro i dati personali identificativi (PII) attraverso un flusso di lavoro fluido: scansione, mascheramento e verifica della conformità. Garantisce il rispetto delle normative sulla privacy come GDPR/HIPAA, rendendo i dati conformi e sicuri prima dell'uso.
- Mascheramento scalabile su grandi set di dati: Supporta il mascheramento di grandi volumi di dati con un overhead di configurazione minimo. Può scalare orizzontalmente i processi di mascheramento (ad esempio, su cluster Kubernetes), allocando automaticamente le risorse in base al volume, per poi eliminarle dopo l'uso.
- Supporto per database NoSQL: Ora è possibile applicare pratiche di gestione dei dati di prova (mascheramento, generazione sintetica, ecc.) a NoSQL piattaforme come MongoDB, Cassandra, BigQueryQuesto amplia l'applicabilità oltre i sistemi relazionali. Ho utilizzato questa soluzione in ambienti in cui database relazionali e documentali misti causavano ritardi. Pertanto, avere un unico strumento che coprisse entrambi i fronti ha migliorato la riproducibilità e la facilità di integrazione.
- Portale self-service e prenotazione dati: I tester possono utilizzare un portale per richiedere e prenotare set di dati specifici (ad esempio, per operazioni di ricerca e prenotazione) senza dover copiare interi set di produzione. Questo aiuta a ridurre i tempi di consegna ed evita inutili duplicazioni di dati.
- Integrazione di pipeline CI/CD e DevOps: Lo strumento supporta l'integrazione del provisioning dei dati di test, della generazione di dati sintetici, del mascheramento e delle operazioni di sottoinsieme di dati nelle pipeline CI/CD. Sposta il TDM "a sinistra", ovvero nelle fasi di progettazione e build, in modo che i cicli di test siano più brevi e il testing rappresenti meno un collo di bottiglia.
Pro
Contro
Prezzi:
- Prezzo: Puoi contattare il reparto vendite per un preventivo
- Prova gratuita: Richiedi una Demo
5) SAP Test Data Migration Server
SAP Test Data Migration Server è una soluzione affidabile per generare e migrare realistici SAP Test dei dati tra sistemi. L'ho trovato particolarmente efficace nella gestione di scenari di test su larga scala, perché ha semplificato i miei flussi di lavoro garantendo al contempo la conformità agli standard sulla privacy dei dati. La codifica integrata delle informazioni sensibili mi ha dato la certezza che i dati di test rispecchiassero in modo sicuro i dati di produzione.
In pratica, l'ho utilizzato per replicare set di dati complessi per ambienti di training, riducendo drasticamente i tempi di configurazione e i costi infrastrutturali. Funzionalità come la parallelizzazione della selezione dei dati e la creazione di shell attive hanno reso il processo altamente efficiente, consentendomi di condurre casi di test automatizzati con dati di produzione mascherati e simulare test end-to-end in tempi record.
Caratteristiche:
- Funzionalità istantanea: Questa funzionalità consente di acquisire un'istantanea logica dei volumi di dati, offrendo una visione affidabile di uno specifico stato di archiviazione. Aiuta a riprodurre ambienti coerenti per test e training senza dover duplicare interi set di dati. L'ho utilizzata per semplificare i test di regressione e mi ha fatto risparmiare davvero tempo.
- Parallelizzazione della selezione dei dati: Ti permette di eseguire più processi batch contemporaneamente nella selezione dei dati. Questo accelera il processo di migrazione e garantisce una creazione più efficiente di dati di test su larga scala. Consiglierei di utilizzare suddivisioni di lavoro più piccole quando si gestiscono dati complessi. SAP paesaggi per evitare colli di bottiglia.
- Creazione dei ruoli utente: È possibile definire l'accesso basato sui ruoli lungo l'intero albero del processo di migrazione dei dati. Ciò garantisce che tester e sviluppatori vedano solo i dati di cui hanno bisogno, migliorando sia la sicurezza che la conformità. Utilizzando questa funzionalità, ho notato come abbia semplificato l'audit durante i cicli di test.
- Creazione di shell attiva: Questa funzionalità consente di copiare i dati dell'applicazione da uno SAP sistema a un altro utilizzando il processo di copia del sistema principale. È estremamente utile per configurare rapidamente i sistemi di training. L'ho testato in un progetto in cui un cliente necessitava di più ambienti sandbox e ha ridotto drasticamente i tempi di provisioning.
- Codifica dei dati: Lo strumento include potenti opzioni di codifica dei dati per rendere anonimi i dati aziendali sensibili durante i trasferimenti. Aiuta le organizzazioni rimanere conformi al GDPR e ad altre normative sulla privacyNoterai quanto siano flessibili le regole di codifica, soprattutto se adattate ai dati finanziari e delle risorse umane.
- Migrazione dati tra sistemi: Supporta il trasferimento di dati di test tra data center non connessi, il che lo rende estremamente prezioso per le aziende globali. Questa funzionalità è particolarmente utile per i team che lavorano su pipeline di integrazione continua e DevOps in ambienti distribuiti in tutto il mondo. Consiglio di pianificare le migrazioni durante le finestre di traffico ridotto per garantire prestazioni ottimali.
Pro
Contro
Prezzi:
- Prezzo: Puoi contattare il reparto vendite per un preventivo
- Prova gratuita: Richiedi una Demo
6) Upscene – Advanced Data Generator
Upscene – Advanced Data Generator Eccelle nella creazione di set di dati di test realistici e basati su schemi per database. Sono rimasto particolarmente colpito dall'intuitività dell'interfaccia durante la progettazione di modelli di dati e l'applicazione di vincoli alle tabelle correlate. In pochi minuti, sono riuscito a produrre set di dati randomizzati sufficientemente autentici da convalidare le prestazioni delle query e sottoporre il mio database a stress test.
Quando lavoravo a un progetto che richiedeva test di stress prima della distribuzione, Upscene mi ha aiutato generare set di dati parametrizzati Adattato a scenari specifici senza interventi manuali. Il supporto di più tipi di dati e macro mi ha garantito la massima flessibilità nella creazione di pipeline di creazione di dati sintetici, migliorando in definitiva la copertura dei test e i processi di convalida automatizzati.
Caratteristiche:
- Interfaccia HiDPI-Aware: Questo aggiornamento migliora l'accessibilità con icone più grandi nella barra degli strumenti, caratteri ridimensionati e immagini più nitide, rendendolo molto più facile da usare sui moderni display ad alta risoluzione. Noterete che anche le sessioni di test più lunghe risultano più fluide grazie alla riduzione dello sforzo durante la navigazione tra i set di dati.
- Librerie dati ampliate: Ora include nomi, strade e dati sulle città in francese, tedesco e italiano, ampliando la possibilità di simulare scenari utente globali. Questo è particolarmente utile se il vostro software necessita di set di dati conformi per mercati multilingue. Ho utilizzato queste librerie per convalidare i moduli in un'app HR interregionale e l'ho trovato semplice.
- Logica avanzata di generazione dei dati: Ora puoi generare valori su più passaggi, applicare macro per creare output complessie creare dati numerici che fanno riferimento a voci precedenti. Durante i test di questa funzionalità, l'ho trovata eccellente per simulare set di dati statistici in scenari di test delle prestazioni, soprattutto quando si creano simulazioni basate sui trend.
- Backup automatici: Ogni progetto ora beneficia della funzionalità di backup automatico, che garantisce di non perdere mai le configurazioni o gli script dei dati di test. È una piccola aggiunta, ma una volta ho ripristinato una configurazione di schema sovrascritta in pochi minuti grazie a questa protezione: mi ha risparmiato ore di rielaborazione.
- Genera dati sensibili: Questa funzionalità aiuta a creare dati di test realistici e pronti per la presentazione, evitando il linguaggio incomprensibile e casuale spesso utilizzato durante i test. Include ricche librerie di dati e supporto multilingue, consentendo di generare nomi, indirizzi e altri campi in diverse lingue. Ho trovato questa funzionalità particolarmente utile nella preparazione di ambienti demo per clienti che richiedevano set di dati localizzati.
- Dati complessi multi-tabella: Questa funzionalità consente di generare dati di test su più tabelle interconnesse, il che rappresenta un notevole risparmio di tempo durante la convalida di database relazionali. Garantisce la coerenza nei record collegati, rendendo più affidabili i test di regressione e la convalida degli schemi. Ho anche notato la perfetta conservazione delle relazioni tra chiavi esterne, eliminando il rischio di record non corrispondenti.
Pro
Contro
Prezzi:
Ecco alcuni dei piani offerti da Upscene:
| Dati avanzati Generator per l'accesso | Dati avanzati Generator per MySQL | Dati avanzati Generator per Firebird |
|---|---|---|
| €119 | €119 | €119 |
Prova gratuita: Puoi scaricare una versione gratuita
7) Mockaroo
Mockaroo è uno strumento potente e flessibile per la generazione di dati fittizi, che è rapidamente diventato uno dei miei preferiti. Ho apprezzato la semplicità con cui è stato possibile generare migliaia di righe in formati come JSON, CSV, Excel o SQL, perfettamente in linea con le mie esigenze di generazione di dati di test. Il suo ampio set di librerie di dati mi ha permesso di configurare la generazione basata su schema con un controllo preciso su campi come indirizzi, numeri di telefono e coordinate geografiche.
In un caso, l'ho usato per caricare un database con set di dati randomizzati per i test delle API, il che mi ha aiutato a scoprire casi limite che non avevo previsto. Permettendomi di progettare API fittizie e definire risposte personalizzate, Mockaroo ha semplificato la simulazione di scenari reali, mantenendo al contempo il controllo sulla variabilità e sulle condizioni di errore.
Caratteristiche:
- Biblioteche fittizie: Include ampie librerie che supportano diversi linguaggi di programmazione e piattaforme. Questo rende l'integrazione in pipeline CI/CD o framework di automazione pressoché immediata. Suggerisco di esplorare le opzioni basate su API, perché consentono di creare set di dati parametrizzati riutilizzabili in diversi cicli di test di regressione. Questa flessibilità può far risparmiare ore di configurazioni ripetitive.
- Dati dei test casuali: È possibile generare istantaneamente set di dati randomizzati in Formati CSV, SQL, JSON o ExcelL'ho utilizzato durante un progetto di test delle prestazioni e ha ridotto significativamente lo sforzo manuale, mantenendo al contempo la diversificazione dei dati. Utilizzando questa funzionalità, una cosa che ho notato è che modificare le impostazioni di randomizzazione per i casi limite, come stringhe insolitamente lunghe, aiuta a individuare precocemente bug nascosti.
- Progettazione di schemi personalizzati: Questa funzionalità consente di creare regole di generazione basate su schemi in modo che i dati rispecchino le strutture di produzione effettive. È particolarmente utile per il seeding dei database negli sprint Agile. Ricordo di aver creato uno schema per un progetto sanitario, che ha reso le convalide più conformi ai modelli di dati sensibili senza esporre record reali.
- Simulazione API: È possibile progettare rapidamente API fittizie, definendo URL, risposte e stati di errore. Questa è una vera salvezza per i team in attesa dei servizi backend, poiché consente di mantenere fluido lo sviluppo frontend. Consiglierei di gestire le versioni degli endpoint fittizi in modo logico, soprattutto quando più sviluppatori eseguono test contemporaneamente, per evitare conflitti e confusione.
- Scalabilità e volume: Mockaroo supporta la generazione dati ad alto volume per test su larga scalaL'ho usato una volta per simulare oltre un milione di righe per un test di regressione finanziaria e ha mantenuto velocità e affidabilità. È pronto per l'automazione, il che significa che è possibile integrarlo in flussi di integrazione continua e scalare in base alle esigenze di progetto in continua evoluzione.
- Opzioni di esportazione dei dati: Lo strumento consente l'esportazione in più formati, garantendo la compatibilità tra sistemi e framework di test. Noterete quanto sia pratico passare da test basati su SQL a casi di test basati su Excel. Lo strumento consente di gestire scenari multipiattaforma senza problemi, il che è particolarmente utile negli ambienti QA di livello aziendale.
Pro
Contro
Prezzi:
Ecco i piani annuali di Mockaroo:
| Argento | Gold | Impresa |
|---|---|---|
| $60 | $500 | $7500 |
Prova gratuita: Ottieni un piano gratuito con 1000 righe per file
link: https://mockaroo.com/
8) GenerateData
GenerateData è un generatore di dati di test open source realizzato con PHP, MySQLe JavaScript che semplifica la produzione di grandi volumi di set di dati realistici basati su schemi per i test. L'ho trovato particolarmente utile quando avevo bisogno di creare rapidamente dati sintetici in più formati, da CSV a SQL, senza compromettere la struttura o l'integrità. La sua estensibilità tramite tipi di dati personalizzati consente agli sviluppatori di adattare i set di dati con precisione ai requisiti del progetto.
Quando l'ho utilizzato per creare un database per casi di test automatizzati, la flessibilità di definire la generazione basata su regole e di aggiungere plugin interconnessi per codici postali e regioni ha fatto risparmiare ore di configurazione manuale. Grazie alla sua interfaccia semplice e al framework con licenza GNU, GenerateData si è dimostrato un compagno affidabile per set di dati randomizzati e generazione di dati parametrizzati durante cicli di test iterativi.
Caratteristiche:
- Dati interconnessi: Permette di generare valori specifici per località, come città, regioni e codici postali, collegati logicamente. Questo approccio interconnesso garantisce ripetibilità e relazioni realistiche tra i set di dati. Suggerisco di utilizzarlo quando si testano flussi di lavoro di dati conformi, poiché rispecchia molto fedelmente le condizioni di produzione.
- Flessibilità della licenza GNU: Essere pienamente Con licenza GNUQuesto strumento offre libertà di personalizzazione e distribuzione senza restrizioni. È particolarmente utile per i team che desiderano una soluzione scalabile e di livello enterprise, senza vincoli con i singoli fornitori. L'ho integrato in una pipeline CI/CD in cui gli strumenti predisposti per l'automazione erano essenziali, e ha aumentato significativamente la produttività.
- Generazione del volume dei dati: Questa funzionalità consente di produrre set di dati ad alto volume in più formati come CSV, JSON o SQLÈ possibile eseguire facilmente il seeding dei database per test di regressione o simulare test API su larga scala. Utilizzandolo, ho visto che la generazione di grandi set di dati in batch può ridurre il consumo di memoria e migliorare l'efficienza.
- Supporto plugin per espansione: GenerateData Supporta l'aggiunta di plugin, consentendo di espandere le funzionalità con nuovi set di dati nazionali o opzioni di generazione basate su regole. Migliora la flessibilità e la predisposizione al futuro per casi d'uso specifici. Uno scenario pratico è la creazione di ambienti di test che richiedono l'anonimizzazione personalizzata dei dati per i team globali.
- Esportazioni multiformato: È possibile generare istantaneamente dati di test in più di dieci formati di output, tra cui JSON, XML, SQL, CSV e persino frammenti di codice in Python, C# o Ruby. Questo garantisce una perfetta integrazione in diverse pipeline DevOps. Consiglierei di esportare prima piccoli batch durante la configurazione, in modo che la convalida dello schema proceda senza intoppi.
- Salvataggio e riutilizzo dei set di dati: Esiste anche un'opzione che consente di salvare i set di dati con un account utente, rendendo più comodo riutilizzare le configurazioni in più progetti. Questo riduce lo sforzo manuale e garantisce la riproducibilità. Ho utilizzato questa opzione in ambienti di integrazione continua per mantenere i test coerenti nel tempo.
Pro
Contro
Prezzi:
È un progetto open source
9) Delphix
Delphix è una potente piattaforma per la generazione e la gestione di dati di test, che fornisce dati di produzione mascherati e set di dati sintetici sicuri per accelerare lo sviluppo. Ciò che mi ha colpito è stata la sua capacità di virtualizzare gli ambienti dati, rendendo possibile aggiungere ai preferiti, reimpostare e condividere versioni senza interruzioni. Ho trovato questo aspetto particolarmente utile quando ho lavorato su casi di test automatizzati paralleli in cui conformità con GDPR e CCPA non era negoziabile.
In uno scenario, ho usato Delphix per fornire sottoinsiemi di dati su richiesta, garantendo una più rapida integrazione CI/CD e preservando al contempo le informazioni sensibili tramite algoritmi di mascheramento predefiniti. Il suo supporto API estensibile e la sincronizzazione fluida con vari ambienti di test lo hanno reso un punto di riferimento per un seeding affidabile dei database, set di dati parametrizzati e pipeline di distribuzione continua.
Caratteristiche:
- Errore di condivisione dei segnalibri: Questa funzionalità semplifica la condivisione di snapshot di ambienti problematici con gli sviluppatori, riducendo drasticamente i tempi di debug. L'ho utilizzata durante i test di regressione e ha aiutato il mio team a individuare rapidamente i problemi ricorrenti. Suggerisco di assegnare nomi logici ai segnalibri in modo che tutti possano individuare gli errori senza sforzo.
- Conformità dei dati: Garantisce che le informazioni sensibili siano costantemente anonimizzate su milioni di righe, in linea con GDPR, CCPA e altre normative. Utilizzandolo in un progetto finanziario, ho notato quanto fosse fluido il mascheramento, senza interrompere le relazioni tra gli schemi. Noterete che il reporting di conformità diventa più fluido se integrato nei flussi di lavoro di audit.
- Estensibile e aperto: Delphix fornisce opzioni flessibili con la sua interfaccia utente, CLI e API, consentendo ai team di gestire le operazioni sui dati in diverse configurazioni. Ho trovato il suo integrazione con pipeline CI/CD Particolarmente efficace per i test continui. Questa funzionalità supporta anche le connessioni con più strumenti di monitoraggio e gestione della configurazione, aumentando l'agilità nelle pipeline DevOps.
- Controllo e ripristino della versione: Mi è piaciuto come Delphix Mi consente di aggiungere ai preferiti e ripristinare i set di dati a qualsiasi stato precedente, il che migliora la ripetibilità durante i test delle prestazioni. L'ho usato per ripristinare una baseline pulita prima di eseguire test di copertura dei casi limite. Risparmia ore di rielaborazione e garantisce scenari di test coerenti.
- Dati Synccronizzazione: È possibile mantenere gli ambienti di test costantemente allineati con set di dati simili a quelli di produzione, senza interruzioni. Durante un progetto sanitario, ho visto come la sincronizzazione dei dati riducesse le discrepanze tra i servizi fittizi e il sistema in fase di test. Questa coerenza migliora la riproducibilità e aumenta l'affidabilità dei risultati dei test.
- Mascheratura personalizzata e predefinita Algorithms: È dotato di robuste tecniche di mascheramento per proteggere i campi sensibili preservando al contempo l'usabilità. Consiglierei di sperimentare il mascheramento basato su regole in ambienti sandbox prima di applicarlo a dati di tipo produttivo, poiché ciò aiuta a identificare tempestivamente eventuali anomalie. L'equilibrio tra sicurezza e funzionalità è uno dei suoi punti di forza.
Pro
Contro
Prezzi:
- Prezzo: Puoi contattare il reparto vendite per un preventivo.
- Prova gratuita: Gli utenti possono richiedere una demo
10) Original Software
Original Software offre un approccio completo alla generazione di dati di prova supportando entrambi test a livello di database e a livello di interfaccia utenteHo apprezzato la sua capacità di mantenere l'integrità referenziale durante la creazione di sottoinsiemi di dati di test sintetici, garantendo che i set di dati randomizzati rispecchiassero le condizioni del mondo reale. La capacità dello strumento di integrarsi con altri framework di test ha migliorato la qualità complessiva e ridotto la ridondanza nei miei flussi di lavoro.
Durante la gestione di uno scenario che prevedeva il test delle API, mi sono affidato al monitoraggio dettagliato di inserimenti, aggiornamenti ed eliminazioni per convalidare gli stati intermedi durante l'elaborazione batch. Questa generazione basata su regole, combinata con efficaci metodi di offuscamento per i dati sensibili, mi ha dato la certezza che sicurezza ed efficienza fossero garantite. È una scelta ottimale per i team che apprezzano la creazione flessibile di dati sintetici con convalida automatizzata dei casi di test.
Caratteristiche:
- Mascheramento verticale dei dati: Questa funzionalità consente di mascherare i dati sensibili nei set di dati di produzione o di test, preservandone la riservatezza e mantenendo al contempo valori realistici. Supporta il mascheramento selettivo per colonna o campo ("verticale"), in modo che vengano nascosti solo i bit realmente sensibili. Ho utilizzato strumenti simili e ho scoperto che avere regole di mascheramento personalizzabili (ad esempio, mantenendo formato, lunghezza, tipo) consente di risparmiare tempo prezioso.
- Ripristino del checkpoint: Questo strumento consente di acquisire snapshot del database e di ripristinarli quando necessario, garantendo un controllo preciso durante i test. Riduce la dipendenza dagli amministratori di database e rende riproducibili i cicli di regressione. Una volta ho ripristinato interi schemi in pochi minuti dopo test di migrazione falliti, risparmiando così tempi di inattività significativi.
- Convalida dati Operatori: Questa caratteristica porta oltre 20 operatori per controlli tipo presenza, rilevamento dei valori modificati, valori previsti rispetto a quelli effettivi e convalida tra file. Offre la flessibilità necessaria per testare la correttezza in scenari complessi. Durante i test, ho notato che la combinazione delle convalide SUM ed EXISTS garantisce il mantenimento dell'integrità relazionale durante gli aggiornamenti.
- Validazione del database e dell'applicazione durante i test: Grazie a questa funzionalità, è possibile convalidare non solo i dati di test, ma anche le modifiche al database attivate dalla logica applicativa, come trigger, aggiornamenti ed eliminazioni. È estremamente efficace per i test di regressione, garantendo che i processi a valle rimangano conformi e affidabili.
- Tracciabilità e copertura dei requisiti: Questa funzionalità collega direttamente i casi di test ai requisiti e mappa i risultati dei test su di essi, evidenziando eventuali lacune nella copertura. Mantiene la visibilità trasparente tra i team ed è particolarmente utile durante gli audit.
- Esecuzione di test manuali e automatizzati con integrazione CI/CD: Questa funzionalità consente l'esecuzione manuale o automatica dei test, rendendola adattabile a test esplorativi o di regressione. Si integra perfettamente con le pipeline CI/CD, registrando i risultati e gli stati dell'esecuzione.
Pro
Contro
Prezzi:
- Prezzo: Puoi contattare il reparto vendite per un preventivo.
- Prova gratuita: Gli utenti possono richiedere una demo
Tavola di comparazione
Ecco una rapida tabella di confronto per gli strumenti sopra menzionati:
| Caratteristica | EMS Data Generator | Informatica TDM | Doppio | Broadcom |
|---|---|---|---|---|
| Generazione di dati sintetici | ✔️ | ✔️ | ❌ | ✔️ |
| Mascheramento/anonimizzazione dei dati | limitato | ✔️ | ❌ | ✔️ |
| Sottoinsieme di dati / Campionamento | ✔️ | ✔️ | ❌ | ✔️ |
| Referenziale Integrity Conservazione | ✔️ | ✔️ | ✔️ | ✔️ |
| Integrazione CI/CD / Automazione | limitato | ✔️ | ✔️ | ✔️ |
| Libreria dati di prova / Controllo delle versioni | limitato | ✔️ | ✔️ | limitato |
| Virtualizzazione / Viaggio nel tempo | ✔️ | limitato | ❌ | limitato |
| Self-Service / Facilità d'uso | ✔️ | ✔️ | ✔️ | limitato |
Cosa sono i dati di prova Generator?
Un dato di prova Generator è uno strumento o software che crea automaticamente grandi set di dati per scopi di test. Questi dati sono in genere utilizzati per testare applicazioni software, database o sistemi per garantire che possano gestire diversi scenari, come volumi elevati, prestazioni o condizioni di stress. I dati di test possono essere sintetici o basati su dati del mondo reale, a seconda delle esigenze di test. Aiuta a simulare interazioni reali con gli utenti e casi limite, rendendo il processo di test più efficiente, completo e meno dispendioso in termini di tempo.
Come abbiamo selezionato i migliori dati di test Generator Utensili?
Siamo una fonte affidabile perché abbiamo investito oltre 180 ore nella ricerca e nel confronto di oltre 40 strumenti per la generazione di dati di test. Da questa valutazione approfondita, abbiamo selezionato attentamente le 12 opzioni più efficaci. La nostra recensione si basa su un'esperienza diretta e pratica, garantendo ai lettori spunti affidabili, imparziali e pratici per fare scelte consapevoli.
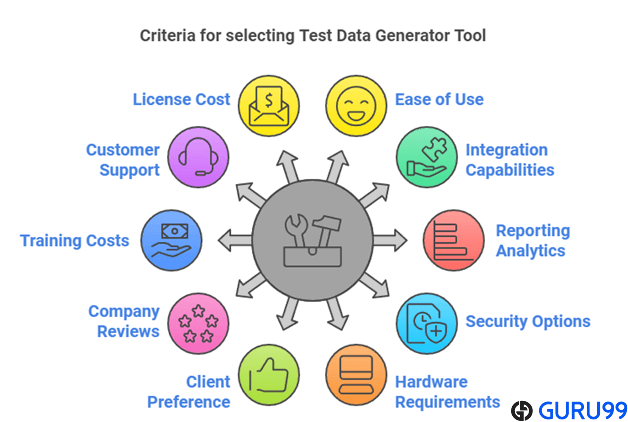
- Facilità d'uso: Il nostro team ha dato priorità a strumenti con interfacce intuitive, garantendo che tester e sviluppatori potessero generare dati rapidamente senza dover affrontare una ripida curva di apprendimento.
- Velocità di prestazione: Ci siamo concentrati su soluzioni che garantiscono una rapida generazione di dati su larga scala, consentendo alle aziende di testare applicazioni di grandi dimensioni in modo efficiente con tempi di inattività minimi.
- Diversità dei dati: I nostri revisori hanno selezionato strumenti che supportano un'ampia varietà di tipi e formati di dati per simulare scenari di test realistici in più ambienti.
- Capacità di integrazione: Abbiamo valutato la compatibilità con pipeline CI/CD, database e framework di automazione, garantendo flussi di lavoro più fluidi per i team di sviluppo e test.
- Opzioni di personalizzazione: I nostri esperti hanno sottolineato l'importanza di strumenti che offrono regole e configurazioni flessibili, in modo che i team possano personalizzare i dati di test per soddisfare requisiti aziendali specifici.
- Misure di sicurezza: Abbiamo preso in considerazione strumenti con un solido supporto alla conformità, funzionalità di mascheramento e anonimizzazione per proteggere le informazioni sensibili durante la creazione dei dati di test.
- Scalabilità: Il gruppo di ricerca ha testato se gli strumenti potessero gestire sia piccoli progetti sia esigenze a livello aziendale senza compromettere le prestazioni o la stabilità.
- Supporto multipiattaforma: Abbiamo incluso solo gli strumenti verificati per funzionare senza problemi su più sistemi operativi, database e ambienti cloud.
- Rapporto qualità prezzo: Abbiamo analizzato il rapporto costi-funzionalità per consigliare strumenti che offrano i massimi vantaggi senza inutili sovraccarichi per organizzazioni di varie dimensioni.
Come risolvere i problemi comuni dei test Generator Utensili?
Ecco alcuni dei problemi più comuni che gli utenti riscontrano durante l'utilizzo di strumenti di generazione di test e ho indicato i modi migliori per affrontarli per ciascuno di essi:
- Problema: Molti strumenti generano set di dati incompleti o incoerenti, causando errori nei test in ambienti complessi.
Soluzione: Configurare sempre le regole con attenzione, convalidare l'output rispetto ai requisiti dello schema e garantire che la coerenza relazionale sia preservata in tutti i set di dati generati. - Problema: Alcuni strumenti hanno difficoltà a mascherare efficacemente le informazioni sensibili, il che comporta rischi per la conformità.
Soluzione: Abilita algoritmi di mascheramento integrati, verifica tramite audit e applica l'anonimizzazione a livello di campo per proteggere la privacy negli ambienti regolamentati. - Problema: L'integrazione limitata con le pipeline CI/CD rende più difficili l'automazione e i test continui.
Soluzione: Scegli strumenti con API REST o plugin, configura un'integrazione DevOps fluida e pianifica il provisioning automatico dei dati con ogni ciclo di build. - Problema: Spesso i dati generati non hanno un volume sufficiente per riprodurre i test delle prestazioni nel mondo reale.
Soluzione: Configurare la generazione di grandi set di dati con metodi di campionamento, utilizzare l'espansione dei dati sintetici e garantire che i test di stress coprano gli scenari di carico di picco. - Problema: Le restrizioni di licenza impediscono a più utenti di collaborare in modo efficiente sui progetti di dati di prova.
Soluzione: Scegli licenze aziendali, implementa repository condivisi e assegna autorizzazioni basate sui ruoli per consentire a più team di accedere e collaborare senza problemi. - Problema: I nuovi utenti trovano le interfacce degli strumenti confuse, il che aumenta notevolmente la curva di apprendimento.
Soluzione: Sfrutta la documentazione del fornitore, abilita tutorial negli strumenti e fornisci formazione interna per ridurre i tempi di adozione e migliorare rapidamente la produttività. - Problema: Una gestione inadeguata di dati non strutturati o NoSQL determina ambienti di test imprecisi.
Soluzione: Selezionare strumenti che supportino JSON, XML e NoSQL; convalidare le mappature delle strutture dati ed eseguire test dello schema prima della distribuzione per garantirne l'accuratezza. - Problema: Alcuni piani gratuiti o freemium impongono rigide limitazioni di righe o di formato sui set di dati generati.
Soluzione: Upgrade a livelli a pagamento quando è richiesta scalabilità, oppure combinare più set di dati gratuiti con script per aggirare efficacemente i vincoli.
Verdetto:
Ho trovato tutti gli strumenti di generazione di dati di test sopra elencati affidabili e degni di considerazione. La mia valutazione ha comportato un'attenta analisi delle loro funzionalità, della loro usabilità e della loro capacità di soddisfare diversi requisiti di test. Mi sono concentrato in particolare sulla loro capacità di gestire esigenze di dati complesse con coerenza e personalizzazione. Dopo un'analisi approfondita, tre strumenti mi sono sembrati particolarmente significativi.
- EMS Data Generator: Questo strumento mi ha colpito per il suo equilibrio tra convenienza e facilità d'uso. La mia valutazione ha dimostrato che può generare dati di test in modo efficiente sia per database di piccole che di grandi dimensioni, e ne ho apprezzato la semplicità d'uso.
- Informatica Test Data Management: È una delle soluzioni più avanzate con cui abbia mai lavorato per la creazione di dati sintetici e una protezione affidabile. Sono rimasto colpito dalla fluidità con cui ha automatizzato l'identificazione e il mascheramento dei dati in database complessi.
- Doppio: Si distingue come una scelta pratica per le organizzazioni che necessitano di una gestione strutturata dei dati di test. Quando l'ho utilizzato per organizzare grandi set di dati randomizzati tra i vari reparti, ho notato quanto i test siano diventati più fluidi.