Scikit-Learn Tutorial: Hogyan telepítsünk és Scikit-Learn példák
Mi az a Scikit-learn?
Scikit elsajátítható egy nyílt forrású Python könyvtár a gépi tanuláshoz. Támogatja a legmodernebb algoritmusokat, mint például a KNN, XGBoost, véletlenszerű erdő és SVM. A NumPy tetejére épül. A Scikit-learnt széles körben használják a Kaggle versenyben, valamint a kiemelkedő technológiai cégeknél. Segít az előfeldolgozásban, a méretcsökkentésben (paraméterválasztás), az osztályozásban, a regresszióban, a klaszterezésben és a modellválasztásban.
A Scikit-learn rendelkezik a legjobb dokumentációval az összes nyílt forráskódú könyvtár közül. Interaktív diagramot biztosít a címen https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html.
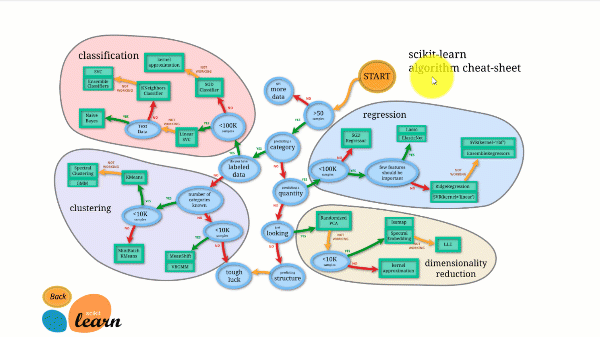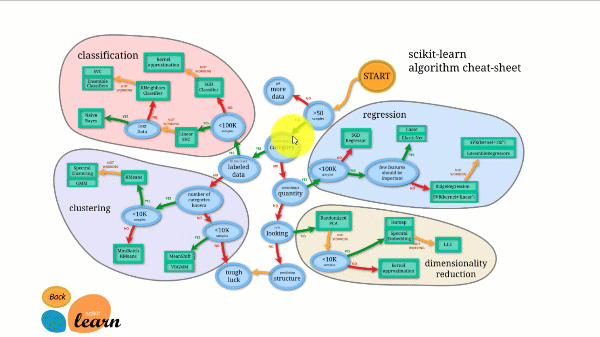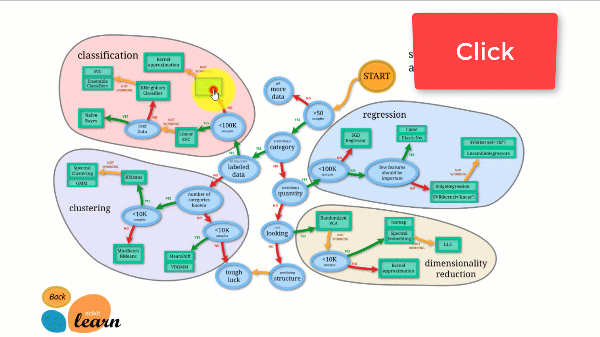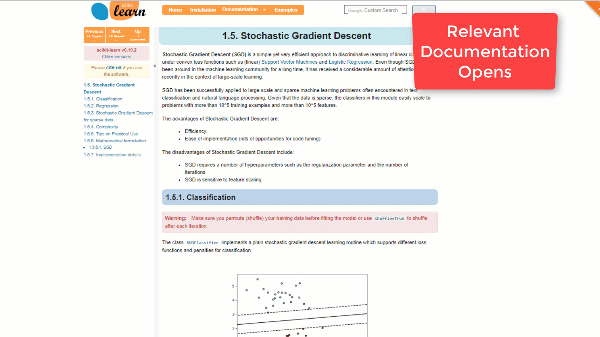
A Scikit-learn használata nem túl nehéz, és kiváló eredményeket biztosít. A scikit learning azonban nem támogatja a párhuzamos számításokat. Lehetőség van mély tanulási algoritmus futtatására is, de ez nem optimális megoldás, főleg ha ismeri a TensorFlow használatát.
A Scikit-learn letöltése és telepítése
Most ebben Python Scikit-learn oktatóanyag, megtanuljuk, hogyan kell letölteni és telepíteni a Scikit-learn-t:
Opció 1: AWS
A scikit-learn használható AWS-en keresztül. Kérem utal A scikit-learn előre telepített docker-képfájl.
A fejlesztői verzió használatához használja az in parancsot Jupyter
import sys
!{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Opció 2: Mac vagy Windows Anaconda segítségével
Az Anaconda telepítésével kapcsolatos további információkért lásd https://www.guru99.com/download-install-tensorflow.html
A közelmúltban a scikit fejlesztői kiadtak egy fejlesztői verziót, amely a jelenlegi verzióval kapcsolatos gyakori problémákat kezeli. Kényelmesebbnek találtuk a fejlesztői verzió használatát a jelenlegi verzió helyett.
A scikit-learn telepítése a Conda Environment segítségével
Ha a scikit-learn programot conda környezettel telepítette, kövesse a lépést a 0.20-as verzióra való frissítéshez
Step 1) Aktiválja a tensorflow környezetet
source activate hello-tf
Step 2) Távolítsa el a scikit lean-t a conda paranccsal
conda remove scikit-learn
Step 3) Fejlesztői verzió telepítése.
Telepítse a scikit learning fejlesztői verziót a szükséges könyvtárakkal együtt.
conda install -c anaconda git pip install Cython pip install h5py pip install git+git://github.com/scikit-learn/scikit-learn.git
JEGYZET: Windows a felhasználónak telepítenie kell Microsoft Vizuális C++ 14. Kaphatsz innen itt
Scikit-Learn példa gépi tanulással
Ez a Scikit oktatóanyag két részre oszlik:
- Gépi tanulás a scikit-learn segítségével
- Hogyan bízza meg modelljét a LIME-ban
Az első rész részletezi, hogyan építsünk fel egy folyamatot, hozzunk létre egy modellt és hangoljuk a hiperparamétereket, míg a második rész a legmodernebb modellválasztást nyújtja.
1. lépés) Importálja az adatokat
A Scikit tanulási oktatóanyaga során a felnőtt adatkészletet fogja használni.
Ha többet szeretne megtudni a leíró statisztikákról, használja a Merülés és Áttekintés eszközöket.
Utal ez a bemutató Tudjon meg többet a Merülésről és az Áttekintésről
Importálja az adatkészletet a Pandákkal. Vegye figyelembe, hogy a folytonos változók típusát lebegő formátumba kell konvertálnia.
Ez az adatkészlet nyolc kategorikus változót tartalmaz:
A kategorikus változók a CATE_FEATURES listában találhatók
- munkaosztály
- szabott oktatás
- házastársi
- foglalkozás
- kapcsolat
- verseny
- szex
- Szülőföld
továbbá hat folytonos változó:
A folytonos változók a CONTI_FEATURES listában találhatók
- kor
- fnlwgt
- oktatási_szám
- tőkenyereség
- tőke_veszteség
- óra_hét
Ne feledje, hogy a listát kézzel töltjük ki, hogy jobb elképzelése legyen arról, milyen oszlopokat használunk. A kategorikus vagy folyamatos lista összeállításának gyorsabb módja a következő:
## List Categorical
CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns
print(CATE_FEATURES)
## List continuous
CONTI_FEATURES = df_train._get_numeric_data()
print(CONTI_FEATURES)
Íme az adatok importálásához szükséges kód:
# Import dataset
import pandas as pd
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
### Define continuous list
CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week']
### Define categorical list
CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
## Prepare the data
features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False)
df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64')
df_train.describe()
| kor | fnlwgt | oktatási_szám | tőkenyereség | tőke_veszteség | óra_hét | |
|---|---|---|---|---|---|---|
| számít | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| jelent | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| perc | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Ellenőrizheti a native_country jellemzők egyedi értékeinek számát. Látható, hogy csak egy háztartás érkezik Hollandia-Hollandiából. Ez a háztartás semmilyen információt nem hoz nekünk, hanem egy hiba miatt a képzés során.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Ezt a nem informatív sort kizárhatja az adatkészletből
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Ezután egy listában tárolja a folyamatos jellemzők pozícióját. Szüksége lesz rá a következő lépésben a csővezeték megépítéséhez.
Az alábbi kód végighurkolja a CONTI_FEATURES összes oszlopnevét, és megkapja a helyét (azaz a számát), majd hozzáfűzi a conti_features nevű listához.
## Get the column index of the categorical features
conti_features = []
for i in CONTI_FEATURES:
position = df_train.columns.get_loc(i)
conti_features.append(position)
print(conti_features)
[0, 2, 10, 4, 11, 12]
Az alábbi kód ugyanazt a feladatot látja el, mint fent, csak a kategorikus változó esetében. Az alábbi kód megismétli azt, amit korábban tett, kivéve a kategorikus jellemzőket.
## Get the column index of the categorical features
categorical_features = []
for i in CATE_FEATURES:
position = df_train.columns.get_loc(i)
categorical_features.append(position)
print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Megnézheti az adatkészletet. Vegye figyelembe, hogy minden kategorikus jellemző egy karakterlánc. Nem táplálhat be egy modellt karakterlánc-értékkel. Átalakítania kell az adatkészletet egy álváltozó segítségével.
df_train.head(5)
Valójában minden csoporthoz létre kell hoznia egy oszlopot a szolgáltatásban. Először is futtassa az alábbi kódot a szükséges oszlopok teljes mennyiségének kiszámításához.
print(df_train[CATE_FEATURES].nunique(),
'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9 education 16 marital 7 occupation 15 relationship 6 race 5 sex 2 native_country 41 dtype: int64 There are 101 groups in the whole dataset
A teljes adatkészlet 101 csoportot tartalmaz, amint az fent látható. Például a munkaosztály jellemzőinek kilenc csoportja van. A csoportok nevét a következő kódokkal jelenítheti meg
Az egyedi() a kategorikus jellemzők egyedi értékeit adja vissza.
for i in CATE_FEATURES:
print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Ezért a betanítási adatkészlet 101 + 7 oszlopot fog tartalmazni. Az utolsó hét oszlop a folyamatos jellemzők.
A Scikit-learn gondoskodhat az átalakításról. Ez két lépésben történik:
- Először is konvertálnia kell a karakterláncot azonosítóvá. Például a State-gov azonosítója 1, Self-emp-not-inc ID 2 és így tovább. A LabelEncoder funkció elvégzi ezt Ön helyett
- Transzponálja az egyes azonosítókat egy új oszlopba. Mint korábban említettük, az adatkészlet 101 csoportazonosítóval rendelkezik. Ezért lesz 101 oszlop, amely rögzíti az összes kategória jellemző csoportját. A Scikit-learn rendelkezik egy OneHotEncoder nevű funkcióval, amely végrehajtja ezt a műveletet
2. lépés) Hozza létre a vonat/tesztkészletet
Most, hogy az adatkészlet készen áll, feloszthatjuk 80/20 arányban.
80 százalék az edzéskészletre és 20 százalék a tesztkészletre.
Használhatja a train_test_split. Az első argumentum az adatkeret a jellemzők, a második argumentum a címke adatkeret. A teszthalmaz méretét a test_size paraméterrel adhatja meg.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_train[features],
df_train.label,
test_size = 0.2,
random_state=0)
X_train.head(5)
print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
3. lépés) Építse meg a csővezetéket
A folyamat megkönnyíti a modell konzisztens adatokkal való betáplálását.
A mögöttes ötlet az, hogy a nyers adatokat egy „folyamatba” helyezzük a műveletek végrehajtásához.
Például az aktuális adatkészlettel szabványosítania kell a folytonos változókat, és konvertálnia kell a kategorikus adatokat. Vegye figyelembe, hogy a csővezetéken belül bármilyen műveletet elvégezhet. Például, ha az adatkészletben vannak „NA-k”, lecserélheti őket az átlaggal vagy a mediánnal. Új változókat is létrehozhat.
Megvan a választás; keményen kódolja a két folyamatot, vagy hozzon létre egy folyamatot. Az első választás adatszivárgáshoz vezethet, és idővel következetlenségeket okozhat. Jobb megoldás a csővezeték használata.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
A csővezeték két műveletet hajt végre a logisztikai osztályozó betáplálása előtt:
- Szabványosítsa a változót: "StandardScaler()"
- Konvertálja a kategorikus jellemzőket: OneHotEncoder(sparse=False)
A két lépést a make_column_transformer segítségével hajthatja végre. Ez a funkció nem érhető el a scikit-learn jelenlegi verziójában (0.19). A jelenlegi verzióval nem lehet végrehajtani a címkekódolót és egy forró kódolót a folyamatban. Ez az egyik oka annak, hogy a fejlesztői verzió használata mellett döntöttünk.
make_column_transformer könnyen használható. Meg kell határoznia, hogy mely oszlopokban alkalmazza az átalakítást, és milyen transzformációt végezzen. Például a folyamatos funkció szabványosításához a következőket teheti:
- conti_features, StandardScaler() a make_column_transformerben.
- conti_features: lista a folytonos változóval
- StandardScaler: szabványosítsa a változót
A make_column_transformerben található OneHotEncoder objektum automatikusan kódolja a címkét.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Kipróbálhatja, hogy a folyamat működik-e a fit_transform paraméterrel. Az adatkészletnek a következő alakúnak kell lennie: 26048, 107
preprocess.fit_transform(X_train).shape
(26048, 107)
Az adattranszformátor használatra kész. A folyamatot a make_pipeline paranccsal hozhatja létre. Az adatok átalakítása után beadhatja a logisztikus regressziót.
model = make_pipeline(
preprocess,
LogisticRegression())
Scikit-learn segítségével modellt képezni triviális. Használnia kell az objektum illesztést, amelyet a folyamat, azaz a modell előz meg. A pontosságot kinyomtathatja a scikit-learn könyvtár pontszámobjektumával
model.fit(X_train, y_train)
print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Végül megjósolhatja az osztályokat a ennusta_proba segítségével. Minden osztály valószínűségét adja vissza. Vegye figyelembe, hogy összege egy.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
4. lépés) Csővezetékünk használata rácskeresésben
A hiperparaméterek hangolása (a hálózati struktúrát meghatározó változók, például a rejtett egységek) fárasztó és fárasztó lehet.
A modell értékelésének egyik módja lehet az edzéskészlet méretének megváltoztatása és a teljesítmények értékelése.
Ezt a módszert tízszer megismételheti a pontszámmérők megtekintéséhez. Ez azonban túl sok munka.
Ehelyett a scikit-learn olyan funkciót biztosít, amely paraméterhangolást és keresztellenőrzést végez.
Keresztellenőrzés
A keresztellenőrzés azt jelenti, hogy a képzés során a tréningkészletet n-szer csúsztatják be hajtogatva, majd n időre értékelik a modellt. Például, ha a cv 10-re van állítva, a képzési készlet betanításra kerül, és tízszer értékeli. Az osztályozó minden körben véletlenszerűen választ ki kilenc hajtást a modell betanításához, a 10. hajtás pedig értékelésre szolgál.
Rács keresés
Minden osztályozónak vannak beállítandó hiperparaméterei. Kipróbálhat különböző értékeket, vagy beállíthat egy paraméterrácsot. Ha felkeresi a scikit-learn hivatalos webhelyét, láthatja, hogy a logisztikai osztályozó különböző paraméterekkel rendelkezik, amelyeket be kell hangolni. Az edzés gyorsabbá tételéhez válassza a C paraméter hangolását. A szabályzási paramétert vezérli. Pozitívnak kell lennie. Egy kis érték nagyobb súlyt ad a szabályosítónak.
Használhatja a GridSearchCV objektumot. A hangoláshoz létre kell hoznia egy szótárt, amely tartalmazza a hiperparamétereket.
Felsorolja a hiperparamétereket, majd a kipróbálni kívánt értékeket. Például a C paraméter hangolásához használja:
- 'logisticregression__C': [0.1, 1.0, 1.0]: A paramétert az osztályozó neve (kisbetűvel) és két aláhúzásjel előzi meg.
A modell négy különböző értékkel próbálkozik: 0.001, 0.01, 0.1 és 1.
A modellt 10 hajtás segítségével tanítod: cv=10
from sklearn.model_selection import GridSearchCV
# Construct the parameter grid
param_grid = {
'logisticregression__C': [0.001, 0.01,0.1, 1.0],
}
A modellt a GridSearchCV segítségével betaníthatja a gri és cv paraméterekkel.
# Train the model
grid_clf = GridSearchCV(model,
param_grid,
cv=10,
iid=False)
grid_clf.fit(X_train, y_train)
KIMENET
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))]),
fit_params=None, iid=False, n_jobs=1,
param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
A legjobb paraméterek eléréséhez használja a best_params_
grid_clf.best_params_
KIMENET
{'logisticregression__C': 1.0}
A modell négy különböző regularizációs értékkel betanítása után az optimális paraméter az
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
legjobb logisztikai regresszió a rácskeresésből: 0.850891
Az előrejelzett valószínűségek eléréséhez:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
XGBoost modell scikit-learn funkcióval
Próbáljuk ki a Scikit-learn példákat, hogy megtanítsuk a piac egyik legjobb osztályozóját. Az XGBoost előrelépés a véletlenszerű erdőhöz képest. Az osztályozó elméleti háttere ennek körén kívül esik Python Scikit tutorial. Ne feledje, hogy az XGBoost rengeteg kaggle versenyt nyert. Átlagos adatkészletmérettel olyan jól teljesíthet, mint egy mélytanulási algoritmus, vagy még jobban is.
Az osztályozót nehéz betanítani, mert nagyszámú hangolható paraméterrel rendelkezik. Természetesen a GridSearchCV segítségével kiválaszthatja a megfelelő paramétert.
Ehelyett nézzük meg, hogyan lehet jobb módszert használni az optimális paraméterek megtalálására. A GridSearchCV unalmas lehet, és nagyon hosszú lehet a betanítása, ha sok értéket ad át. A keresési tér a paraméterek számával együtt növekszik. Előnyös megoldás a RandomizedSearchCV használata. Ez a módszer abból áll, hogy minden iteráció után véletlenszerűen választjuk ki az egyes hiperparaméterek értékét. Például, ha az osztályozó 1000 iteráción keresztül van betanítva, akkor 1000 kombináció kerül kiértékelésre. Többé-kevésbé úgy működik. GridSearchCV
Az xgboost importálnia kell. Ha a könyvtár nincs telepítve, használja a pip3 install xgboost vagy
use import sys
!{sys.executable} -m pip install xgboost
In Jupyter környezet
Ezután
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
A következő lépés ebben a Scikitben Python Az oktatóprogram tartalmazza a hangolandó paraméterek megadását. A hivatalos dokumentációban megtekintheti az összes hangolandó paramétert. A kedvéért a Python Sklearn oktatóanyag, csak két hiperparamétert válasszon két-két értékkel. Az XGBoost betanítása sok időt vesz igénybe, minél több hiperparaméter van a rácsban, annál hosszabb ideig kell várnia.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Új folyamatot hoz létre az XGBoost osztályozóval. 600 becslést határozhat meg. Vegye figyelembe, hogy az n_estimators egy olyan paraméter, amelyet beállíthat. A magas érték túlillesztéshez vezethet. Kipróbálhat egyedül különböző értékeket, de ne feledje, hogy ez órákig is eltarthat. A többi paraméterhez az alapértelmezett értéket használja
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Javíthatja a keresztellenőrzést a Stratified K-Folds keresztellenőrzővel. Itt csak három hajtást hoz létre, hogy gyorsabbá tegye a számítást, de csökkentse a minőséget. Növelje ezt az értéket 5-re vagy 10-re otthon az eredmények javítása érdekében.
Úgy dönt, hogy a modellt négy iteráción keresztül tanítja.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
A véletlenszerű keresés használatra kész, betaníthatja a modellt
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False) random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min [Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Mint látható, az XGBoost jobb pontszámmal rendelkezik, mint az előző logisztikus regresszió.
print("Best parameter", random_search.best_params_)
print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Hozzon létre DNN-t az MLPClassifier segítségével a scikit-learnben
Végül a scikit-learn segítségével betaníthat egy mély tanulási algoritmust. A módszer ugyanaz, mint a másik osztályozóé. Az osztályozó elérhető az MLPClassifier oldalon.
from sklearn.neural_network import MLPClassifier
A következő mély tanulási algoritmust határozza meg:
- Ádám megoldó
- Relu aktiválási funkció
- Alfa = 0.0001
- A tétel mérete 150
- Két rejtett réteg 100, illetve 50 neuronnal
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
A modell javítása érdekében módosíthatja a rétegek számát
model_dnn.fit(X_train, y_train)
print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN regressziós pontszám: 0.821253
LIME: Bízzon modelljében
Most, hogy van egy jó modellje, szüksége van egy eszközre, amellyel megbízhat benne. Gépi tanulás Az algoritmus, különösen a véletlenszerű erdő és a neurális hálózat, ismerten fekete doboz algoritmus. Mondjuk másképp, működik, de senki sem tudja, miért.
Három kutató egy nagyszerű eszközzel állt elő, amellyel megtudhatja, hogyan jósol a számítógép. A lap a Why Should I Trust You?
nevű algoritmust fejlesztettek ki Helyi értelmezhető modell-agnosztikus magyarázatok (LIME).
Vegyünk egy példát:
néha nem tudja, hogy megbízhat-e egy gépi tanulási előrejelzésben:
Egy orvos például nem bízhat a diagnózisban csak azért, mert a számítógép ezt mondta. Azt is tudnia kell, hogy megbízhat-e a modellben, mielőtt gyártásba kezdi.
Képzeljük el, hogy megérthetjük, hogy bármely osztályozó miért ad jóslatot még olyan hihetetlenül bonyolult modelleknél is, mint a neurális hálózatok, véletlenszerű erdők vagy SVMS bármilyen kernellel
könnyebben fog tudni megbízni egy előrejelzésben, ha megértjük a mögöttes okokat. Az orvossal készült példa alapján, ha a modell elmondaná neki, hogy mely tünetek lényegesek, akkor megbízhat benne, akkor azt is könnyebben kiderítheti, hogy nem szabad-e megbíznia a modellben.
A Lime meg tudja mondani, hogy milyen jellemzők befolyásolják az osztályozó döntéseit
Adatok előkészítése
Néhány dolgot meg kell változtatnia a LIME futtatásához piton. Először is telepítenie kell a lime-ot a terminálba. Használhatja a pip install lime-ot
A Lime a LimeTabularExplainer objektumot használja a modell helyi közelítésére. Ehhez az objektumhoz:
- egy adatkészlet numpy formátumban
- A jellemzők neve: feature_names
- Az osztályok neve: class_names
- A kategorikus jellemzők oszlopának indexe: categorical_features
- A csoport neve az egyes kategóriás jellemzőkhöz: kategoriális_nevek
Hozzon létre zsibbadt vonatkészletet
Másolhatja és konvertálhatja a df_train fájlt pandákból számtalan nagyon könnyen
df_train.head(5) # Create numpy data df_lime = df_train df_lime.head(3)
Szerezd meg az osztály nevét A címke az egyedi() objektummal érhető el. Látnod kéne:
- „<=50 ezer”
- ">50K"
# Get the class name class_names = df_lime.label.unique() class_names
array(['<=50K', '>50K'], dtype=object)
a kategorikus jellemzők oszlopának indexe
A csoport nevének megszerzéséhez használhatja az előző módszert. A címkét a LabelEncoder segítségével kódolhatja. Megismétli a műveletet az összes kategorikus jellemzőn.
##
import sklearn.preprocessing as preprocessing
categorical_names = {}
for feature in CATE_FEATURES:
le = preprocessing.LabelEncoder()
le.fit(df_lime[feature])
df_lime[feature] = le.transform(df_lime[feature])
categorical_names[feature] = le.classes_
print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Most, hogy az adatkészlet készen áll, létrehozhatja a különböző adatkészleteket az alábbi Scikit learning példák szerint. Valójában a folyamaton kívül alakítja át az adatokat, hogy elkerülje a LIME hibákat. A LimeTabularExplainer képzési halmazának egy karakterlánc nélküli numpy tömbnek kell lennie. A fenti módszerrel egy képzési adatkészlet már konvertálva van.
from sklearn.model_selection import train_test_split
X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features],
df_lime.label,
test_size = 0.2,
random_state=0)
X_train_lime.head(5)
Az XGBoostból az optimális paraméterekkel elkészítheti a folyamatot
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))])
Figyelmeztetést kapsz. A figyelmeztetés elmagyarázza, hogy nem kell címkekódolót létrehozni a folyamat előtt. Ha nem szeretné használni a LIME-ot, használhatja a Gépi tanulás a Scikit-learn oktatóanyag első részében található módszert. Ellenkező esetben megtarthatja ezt a módszert, először hozzon létre egy kódolt adatkészletet, és állítsa be a hot one kódolót a folyamatban.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Mielőtt a LIME-ot működés közben használnánk, hozzunk létre egy tömböt a rossz osztályozás jellemzőivel. Ezt a listát később felhasználhatja, hogy képet kapjon arról, mi vezeti félre az osztályozót.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1)
temp['predicted'] = model_xgb.predict(X_test_lime)
temp['wrong']= temp['label'] != temp['predicted']
temp = temp.query('wrong==True').drop('wrong', axis=1)
temp= temp.sort_values(by=['label'])
temp.shape
(826, 16)
Létrehoz egy lambda-függvényt, amely lekéri az előrejelzést a modellből az új adatokkal. Hamarosan szüksége lesz rá.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float) X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
A pandas adatkeretet numpy tömbbé alakítja
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
import lime
import lime.lime_tabular
### Train should be label encoded not one hot encoded
explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime ,
feature_names = features,
class_names=class_names,
categorical_features=categorical_features,
categorical_names=categorical_names,
kernel_width=3)
Válasszunk ki egy véletlenszerű háztartást a tesztkészletből, és nézzük meg a modell előrejelzését és azt, hogy a számítógép hogyan döntött.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Használhatja a magyarázatot a magyarázat_instance elemmel a modell mögötti magyarázat ellenőrzéséhez
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)
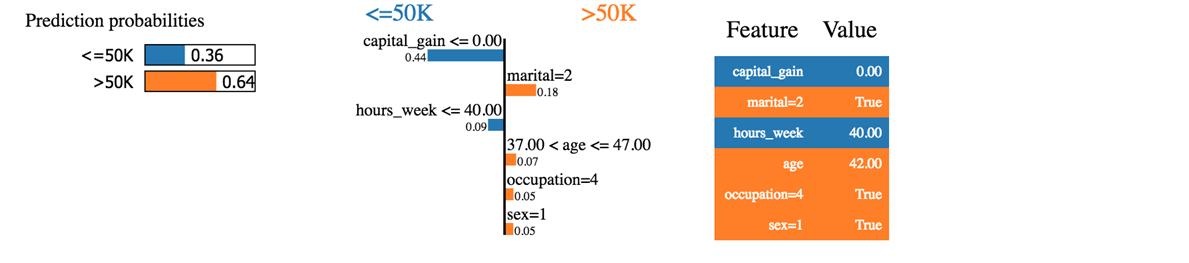
Láthatjuk, hogy az osztályozó helyesen jósolta meg a háztartást. A bevétel valóban meghaladja az 50 ezer forintot.
Először is azt mondhatjuk, hogy az osztályozó nem olyan biztos a megjósolt valószínűségekben. A gép 50%-os valószínűséggel 64 ezer feletti jövedelmet jósol a háztartásnak. Ez a 64% tőkenyereségből és házasságból tevődik össze. A kék szín negatívan járul hozzá a pozitív osztályhoz, a narancssárga vonal pedig pozitívan.
Az osztályozó zavaros, mert ennek a háztartásnak a tőkenyeresége nulla, míg a tőkenyereség általában jó előrejelzője a vagyonnak. Emellett a háztartás kevesebb mint 40 órát dolgozik hetente. Az életkor, a foglalkozás és a nem pozitívan járul hozzá az osztályozóhoz.
Ha a családi állapot hajadon lett volna, az osztályozó 50 ezer alatti jövedelmet jósolt volna (0.64-0.18 = 0.46)
Megpróbálhatjuk egy másik, rosszul besorolt háztartással
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1
print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K predicted >50K Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)

Az osztályozó 50 ezer alatti bevételt jósolt, miközben ez nem igaz. Furcsának tűnik ez a háztartás. Nincs tőkenyeresége, sem tőkevesztesége. Elvált, 60 éves, és tanult népről van szó, azaz iskolai végzettség > 12. Az általános minta szerint ennek a háztartásnak 50 ezer alatt kell lennie, mint ahogy az osztályozó magyarázza.
Megpróbál játszani a LIME-mal. Durva hibákat fog észrevenni az osztályozóból.
Ellenőrizheti a könyvtár tulajdonosának GitHubját. Extra dokumentációt biztosítanak a kép- és szövegosztályozáshoz.
Összegzésként
Az alábbiakban felsorolunk néhány hasznos parancsot, amelyek scikit learning verziója >=0.20
| vonat/teszt adatkészlet létrehozása | a gyakornokok szétválnak |
| Építs csővezetéket | |
| válassza ki az oszlopot, és alkalmazza az átalakítást | makecolumntransformer |
| az átalakulás típusa | |
| szabványosítása | StandardScaler |
| minimum maximum | MinMaxScaler |
| Normalizálás | Normalizáló |
| Hiányzó érték beszámítása | imputálni |
| Átalakítás kategorikus | OneHotEncoder |
| Illessze és alakítsa át az adatokat | fit_transform |
| Készítse el a csővezetéket | make_pipeline |
| Alapmodell | |
| logisztikus regresszió | Logisztikus regresszió |
| XGBoost | XGBClassifier |
| Neurális háló | MLPC-osztályozó |
| Rács keresés | GridSearchCV |
| Véletlenszerű keresés | Véletlenszerű keresés CV |