Otsustuspuu R: klassifikatsioonipuu koos näitega
Mis on otsustuspuud?
Otsustuspuud on mitmekülgne masinõppe algoritm, mis suudab täita nii klassifitseerimis- kui ka regressiooniülesandeid. Need on väga võimsad algoritmid, mis on võimelised sobitama keerulisi andmekogumeid. Lisaks on otsustuspuud juhuslike metsade põhikomponendid, mis on tänapäeval kõige tõhusamate masinõppe algoritmide seas.
R-i otsustuspuude treenimine ja visualiseerimine
Esimese otsustuspuu loomiseks näites R toimime selles otsustuspuu õpetuses järgmiselt.
- 1. toiming: importige andmed
- 2. toiming: puhastage andmestik
- 3. samm: looge rongi-/katsekomplekt
- 4. samm: looge mudel
- 5. samm: ennustage
- 6. samm: mõõtke jõudlust
- 7. samm: häälestage hüperparameetreid
Samm 1) Importige andmed
Kui teid huvitab titanicu saatus, saate seda videot vaadata Youtube. Selle andmestiku eesmärk on ennustada, millised inimesed jäävad pärast kokkupõrget jäämäega tõenäolisemalt ellu. Andmekogum sisaldab 13 muutujat ja 1309 vaatlust. Andmekogum on järjestatud muutuja X järgi.
set.seed(678) path <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/titanic_data.csv' titanic <-read.csv(path) head(titanic)
Väljund:
## X pclass survived name sex ## 1 1 1 1 Allen, Miss. Elisabeth Walton female ## 2 2 1 1 Allison, Master. Hudson Trevor male ## 3 3 1 0 Allison, Miss. Helen Loraine female ## 4 4 1 0 Allison, Mr. Hudson Joshua Creighton male ## 5 5 1 0 Allison, Mrs. Hudson J C (Bessie Waldo Daniels) female ## 6 6 1 1 Anderson, Mr. Harry male ## age sibsp parch ticket fare cabin embarked ## 1 29.0000 0 0 24160 211.3375 B5 S ## 2 0.9167 1 2 113781 151.5500 C22 C26 S ## 3 2.0000 1 2 113781 151.5500 C22 C26 S ## 4 30.0000 1 2 113781 151.5500 C22 C26 S ## 5 25.0000 1 2 113781 151.5500 C22 C26 S ## 6 48.0000 0 0 19952 26.5500 E12 S ## home.dest ## 1 St Louis, MO ## 2 Montreal, PQ / Chesterville, ON ## 3 Montreal, PQ / Chesterville, ON ## 4 Montreal, PQ / Chesterville, ON ## 5 Montreal, PQ / Chesterville, ON ## 6 New York, NY
tail(titanic)
Väljund:
## X pclass survived name sex age sibsp ## 1304 1304 3 0 Yousseff, Mr. Gerious male NA 0 ## 1305 1305 3 0 Zabour, Miss. Hileni female 14.5 1 ## 1306 1306 3 0 Zabour, Miss. Thamine female NA 1 ## 1307 1307 3 0 Zakarian, Mr. Mapriededer male 26.5 0 ## 1308 1308 3 0 Zakarian, Mr. Ortin male 27.0 0 ## 1309 1309 3 0 Zimmerman, Mr. Leo male 29.0 0 ## parch ticket fare cabin embarked home.dest ## 1304 0 2627 14.4583 C ## 1305 0 2665 14.4542 C ## 1306 0 2665 14.4542 C ## 1307 0 2656 7.2250 C ## 1308 0 2670 7.2250 C ## 1309 0 315082 7.8750 S
Pea ja saba väljundist näete, et andmeid ei segata. See on suur probleem! Kui jagate andmed rongikoosseisu ja katsekomplekti vahel, valite ainult klassi 1 ja 2 reisija (Ühtegi klassi 3 reisijat ei ole vaatluste ülemises 80 protsendis), mis tähendab, et algoritm ei näe kunagi klassi 3 reisija tunnuseid. See viga toob kaasa halva prognoosi.
Selle probleemi lahendamiseks võite kasutada funktsiooni sample ().
shuffle_index <- sample(1:nrow(titanic)) head(shuffle_index)
Otsustuspuu R-kood Selgitus
- sample(1:nrow(titanic)): genereerige juhuslik indeksite loend vahemikus 1 kuni 1309 (st maksimaalne ridade arv).
Väljund:
## [1] 288 874 1078 633 887 992
Kasutate seda indeksit Titanicu andmestiku segamiseks.
titanic <- titanic[shuffle_index, ] head(titanic)
Väljund:
## X pclass survived ## 288 288 1 0 ## 874 874 3 0 ## 1078 1078 3 1 ## 633 633 3 0 ## 887 887 3 1 ## 992 992 3 1 ## name sex age ## 288 Sutton, Mr. Frederick male 61 ## 874 Humblen, Mr. Adolf Mathias Nicolai Olsen male 42 ## 1078 O'Driscoll, Miss. Bridget female NA ## 633 Andersson, Mrs. Anders Johan (Alfrida Konstantia Brogren) female 39 ## 887 Jermyn, Miss. Annie female NA ## 992 Mamee, Mr. Hanna male NA ## sibsp parch ticket fare cabin embarked home.dest## 288 0 0 36963 32.3208 D50 S Haddenfield, NJ ## 874 0 0 348121 7.6500 F G63 S ## 1078 0 0 14311 7.7500 Q ## 633 1 5 347082 31.2750 S Sweden Winnipeg, MN ## 887 0 0 14313 7.7500 Q ## 992 0 0 2677 7.2292 C
2. samm) Puhastage andmestik
Andmete struktuur näitab, et mõnel muutujal on NA-d. Andmete puhastamine tuleb teha järgmiselt
- Loobuge muutujatest home.dest,cabin, name, X ja pilet
- Loo tegurimuutujad pclass ja ellujäänud jaoks
- Loobuge NA-st
library(dplyr)
# Drop variables
clean_titanic <- titanic % > %
select(-c(home.dest, cabin, name, X, ticket)) % > %
#Convert to factor level
mutate(pclass = factor(pclass, levels = c(1, 2, 3), labels = c('Upper', 'Middle', 'Lower')),
survived = factor(survived, levels = c(0, 1), labels = c('No', 'Yes'))) % > %
na.omit()
glimpse(clean_titanic)
Koodi selgitus
- select(-c(home.dest, cabin, name, X, pilet)): loobuge mittevajalikud muutujad
- pklass = tegur(pklass, levelid = c(1,2,3), sildid= c('Ülemine', 'Keskmine', 'Alumine')): lisage muutujale pclass silt. 1 muutub ülemiseks, 2 muutub keskmiseks ja 3 muutub madalamaks
- factor(survived, level = c(0,1), sildid = c('Ei', 'Jah')): lisage muutujale säilinud silt. 1 saab ei ja 2 saab Jah
- na.omit(): Eemaldage NA vaatlused
Väljund:
## Observations: 1,045 ## Variables: 8 ## $ pclass <fctr> Upper, Lower, Lower, Upper, Middle, Upper, Middle, U... ## $ survived <fctr> No, No, No, Yes, No, Yes, Yes, No, No, No, No, No, Y... ## $ sex <fctr> male, male, female, female, male, male, female, male... ## $ age <dbl> 61.0, 42.0, 39.0, 49.0, 29.0, 37.0, 20.0, 54.0, 2.0, ... ## $ sibsp <int> 0, 0, 1, 0, 0, 1, 0, 0, 4, 0, 0, 1, 1, 0, 0, 0, 1, 1,... ## $ parch <int> 0, 0, 5, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 2, 0, 4, 0,... ## $ fare <dbl> 32.3208, 7.6500, 31.2750, 25.9292, 10.5000, 52.5542, ... ## $ embarked <fctr> S, S, S, S, S, S, S, S, S, C, S, S, S, Q, C, S, S, C...
Samm 3) Looge rongi-/katsekomplekt
Enne oma mudeli treenimist peate tegema kaks sammu:
- Rongi ja katsekomplekti loomine: treenite mudelit rongikomplektis ja testite ennustust testkomplektis (st nähtamatuid andmeid)
- Installige konsoolist rpart.plot
Levinud tava on jagada andmed 80/20, 80 protsenti andmetest kasutatakse mudeli koolitamiseks ja 20 protsenti prognooside tegemiseks. Peate looma kaks eraldi andmeraami. Te ei soovi testikomplekti puudutada enne, kui olete oma mudeli ehitamise lõpetanud. Saate luua funktsiooni nime create_train_test(), millel on kolm argumenti.
create_train_test(df, size = 0.8, train = TRUE) arguments: -df: Dataset used to train the model. -size: Size of the split. By default, 0.8. Numerical value -train: If set to `TRUE`, the function creates the train set, otherwise the test set. Default value sets to `TRUE`. Boolean value.You need to add a Boolean parameter because R does not allow to return two data frames simultaneously.
create_train_test <- function(data, size = 0.8, train = TRUE) {
n_row = nrow(data)
total_row = size * n_row
train_sample < - 1: total_row
if (train == TRUE) {
return (data[train_sample, ])
} else {
return (data[-train_sample, ])
}
}
Koodi selgitus
- function(andmed, suurus = 0.8, train = TRUE): lisage funktsiooni argumendid
- n_row = nrow(data): loendab andmestiku ridade arvu
- kokku_rida = suurus*n_rida: tagastab rongikomplekti koostamiseks n-nda rea
- train_sample <- 1:total_row: valige esimene rida kuni n-nda reani
- if (train ==TRUE){ } else { }: Kui tingimuseks on seatud tõene, tagastab rongikomplekt, muidu testkomplekt.
Saate testida oma funktsiooni ja kontrollida mõõtmeid.
data_train <- create_train_test(clean_titanic, 0.8, train = TRUE) data_test <- create_train_test(clean_titanic, 0.8, train = FALSE) dim(data_train)
Väljund:
## [1] 836 8
dim(data_test)
Väljund:
## [1] 209 8
Rongi andmekogumis on 1046 rida, samas kui testandmekogumis on 262 rida.
Kasutate funktsiooni prop.table() koos funktsiooniga table(), et kontrollida, kas randomiseerimisprotsess on õige.
prop.table(table(data_train$survived))
Väljund:
## ## No Yes ## 0.5944976 0.4055024
prop.table(table(data_test$survived))
Väljund:
## ## No Yes ## 0.5789474 0.4210526
Mõlemas andmekogumis on ellujäänute arv sama, umbes 40 protsenti.
Installige rpart.plot
rpart.plot pole conda raamatukogudest saadaval. Saate selle installida konsoolist:
install.packages("rpart.plot")
4. samm) Ehitage mudel
Olete mudeli ehitamiseks valmis. Rparti otsustuspuu funktsiooni süntaks on:
rpart(formula, data=, method='') arguments: - formula: The function to predict - data: Specifies the data frame- method: - "class" for a classification tree - "anova" for a regression tree
Kasutate klassimeetodit, kuna ennustate klassi.
library(rpart) library(rpart.plot) fit <- rpart(survived~., data = data_train, method = 'class') rpart.plot(fit, extra = 106
Koodi selgitus
- rpart(): funktsioon mudeli sobitamiseks. Argumendid on järgmised:
- säilinud ~.: Otsustuspuude valem
- andmed = data_train: andmestik
- method = 'klass': sobitage binaarmudel
- rpart.plot(fit, extra= 106): joonistab puu. Lisafunktsioonid on seatud väärtusele 101, et kuvada 2. klassi tõenäosus (kasulik binaarvastuste korral). Võite viidata vinjet teiste valikute kohta lisateabe saamiseks.
Väljund:
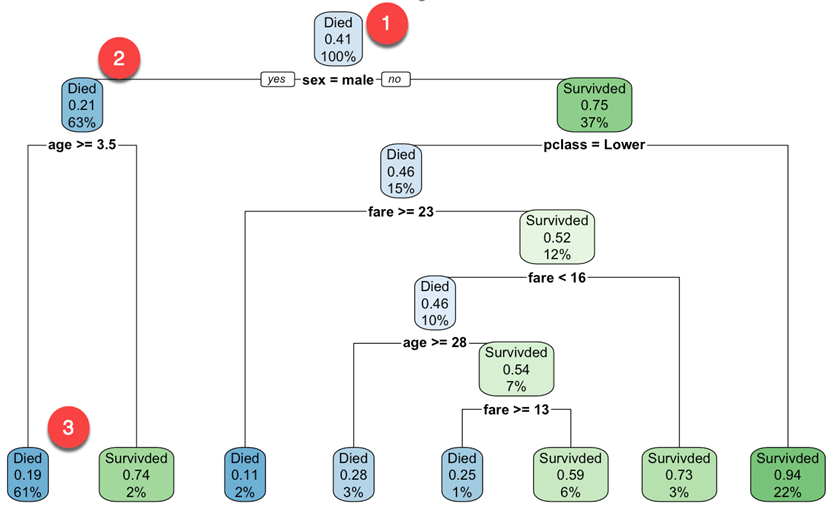
Alustate juursõlmest (sügavus 0 üle 3, graafiku ülaosa):
- Ülaosas on see üldine ellujäämise tõenäosus. See näitab õnnetuses ellu jäänud reisijate osakaalu. 41 protsenti reisijatest jäi ellu.
- See sõlm küsib, kas reisija sugu on meessoost. Kui jah, siis lähete alla juure vasakpoolsesse alamsõlme (sügavus 2). 63 protsenti on mehed, kelle ellujäämise tõenäosus on 21 protsenti.
- Teises sõlmes küsite, kas meessoost reisija on üle 3.5 aasta vana. Kui jah, siis on ellujäämise võimalus 19 protsenti.
- Jätkate samamoodi, et mõista, millised omadused mõjutavad ellujäämise tõenäosust.
Pange tähele, et üks paljudest otsustuspuude omadustest on see, et need nõuavad väga vähe andmete ettevalmistamist. Eelkõige ei vaja need funktsioonide skaleerimist ega tsentreerimist.
Vaikimisi kasutab funktsioon rpart() Gini lisandi mõõt, et sedeli poolitada. Mida kõrgem on Gini koefitsient, seda rohkem on sõlmes erinevaid eksemplare.
5. samm) Tehke ennustus
Saate oma testiandmestiku ennustada. Ennustuse tegemiseks saate kasutada ennustamisfunktsiooni (). R-otsuste puu ennustamise põhisüntaks on:
predict(fitted_model, df, type = 'class')
arguments:
- fitted_model: This is the object stored after model estimation.
- df: Data frame used to make the prediction
- type: Type of prediction
- 'class': for classification
- 'prob': to compute the probability of each class
- 'vector': Predict the mean response at the node level
Tahad katsekomplekti põhjal ennustada, millised reisijad jäävad pärast kokkupõrget suurema tõenäosusega ellu. See tähendab, et saate nende 209 reisija hulgast teada, kes jääb ellu või mitte.
predict_unseen <-predict(fit, data_test, type = 'class')
Koodi selgitus
- ennusta(fit, data_test, type = 'klass'): ennustab testikomplekti klassi (0/1)
Katsetades reisijaid, kes ei pääsenud ja kes ei jõudnud.
table_mat <- table(data_test$survived, predict_unseen) table_mat
Koodi selgitus
- table(data_test$survived, ennusta_unseen): looge tabel, et loendada, kui palju reisijaid liigitatakse ellujäänuteks ja suri, võrreldes õige otsustuspuu klassifikatsiooniga R-s
Väljund:
## predict_unseen ## No Yes ## No 106 15 ## Yes 30 58
Mudel ennustas õigesti 106 hukkunut, kuid liigitas 15 ellujäänut surnuks. Analoogia põhjal klassifitseeris mudel 30 reisijat valesti ellujäänute hulka, samal ajal kui nad osutusid surnuks.
6. samm) Mõõtke jõudlust
Klassifitseerimisülesande täpsuse mõõtmise saate arvutada rakendusega segaduse maatriks:
. segaduse maatriks on parem valik klassifitseerimise toimivuse hindamiseks. Üldine mõte on lugeda kordade arv, mil tõesed eksemplarid on klassifitseeritud Väärteks.
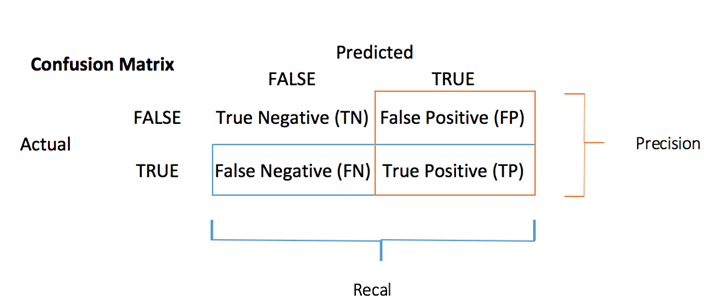
Segadusmaatriksi iga rida tähistab tegelikku sihtmärki, samas kui iga veerg tähistab prognoositavat sihtmärki. Selle maatriksi esimene rida käsitleb surnud reisijaid (klass False): 106 klassifitseeriti õigesti surnuks (Tõeline negatiivne), samas kui ülejäänud klassifitseeriti ekslikult ellujäänuks (Valepositiivne). Teine rida arvestab ellujääjaid, positiivne klass oli 58 (Tõeliselt positiivne), samal ajal kui Tõeline negatiivne oli 30.
Saate arvutada täpsuse test segadusmaatriksist:
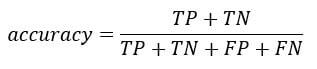
See on tõelise positiivse ja tõelise negatiivse osakaal maatriksi summast. R-ga saate kodeerida järgmiselt:
accuracy_Test <- sum(diag(table_mat)) / sum(table_mat)
Koodi selgitus
- summa(diag(tabel_matt)): diagonaali summa
- summa(tabeli_matt): maatriksi summa.
Saate printida testikomplekti täpsuse:
print(paste('Accuracy for test', accuracy_Test))
Väljund:
## [1] "Accuracy for test 0.784688995215311"
Teil on testikomplekti skoor 78 protsenti. Saate treeninguandmestikuga sama harjutust korrata.
Samm 7) Häälestage hüperparameetrid
R-i otsustuspuul on erinevad parameetrid, mis reguleerivad sobivuse aspekte. Otsustuspuu teegis rpart saate parameetreid juhtida funktsiooni rpart.control() abil. Järgmises koodis tutvustate häälestatavaid parameetreid. Võite viidata vinjet muude parameetrite jaoks.
rpart.control(minsplit = 20, minbucket = round(minsplit/3), maxdepth = 30) Arguments: -minsplit: Set the minimum number of observations in the node before the algorithm perform a split -minbucket: Set the minimum number of observations in the final note i.e. the leaf -maxdepth: Set the maximum depth of any node of the final tree. The root node is treated a depth 0
Toimime järgmiselt:
- Ehitage funktsioon täpsuse tagastamiseks
- Häälestage maksimaalne sügavus
- Häälestage minimaalne näidiste arv, mis sõlmel peab olema, enne kui see saab jagada
- Häälestage minimaalne proovide arv, mis lehesõlmel peab olema
Täpsuse kuvamiseks saate kirjutada funktsiooni. Mähkige lihtsalt kood, mida varem kasutasite:
- ennustama: ennusta_unseen <- ennusta(fit, data_test, type = 'klass')
- Tootmistabel: tabel_matt <- tabel(andmed_test$survived, ennusta_nägemata)
- Arvutamise täpsus: accuracy_Test <- sum(diag(table_mat))/sum(table_mat)
accuracy_tune <- function(fit) {
predict_unseen <- predict(fit, data_test, type = 'class')
table_mat <- table(data_test$survived, predict_unseen)
accuracy_Test <- sum(diag(table_mat)) / sum(table_mat)
accuracy_Test
}
Võite proovida parameetreid häälestada ja vaadata, kas saate mudelit vaikeväärtusest paremaks muuta. Tuletame meelde, et täpsus on suurem kui 0.78
control <- rpart.control(minsplit = 4,
minbucket = round(5 / 3),
maxdepth = 3,
cp = 0)
tune_fit <- rpart(survived~., data = data_train, method = 'class', control = control)
accuracy_tune(tune_fit)
Väljund:
## [1] 0.7990431
Järgmise parameetriga:
minsplit = 4 minbucket= round(5/3) maxdepth = 3cp=0
Saate parema jõudluse kui eelmisel mudelil. Õnnitlused!
kokkuvõte
Saame kokku võtta funktsioonid, milles otsustuspuu algoritmi treenida R
| Raamatukogu | Eesmärk | funktsioon | klass | parameetrid | Detailid |
|---|---|---|---|---|---|
| rpart | Rongi klassifikatsioonipuu R-is | rpart() | klass | valem, df, meetod | |
| rpart | Treeni regressioonipuu | rpart() | anova | valem, df, meetod | |
| rpart | Planeerige puud | rpart.plot() | varustatud mudel | ||
| baas | ennustada | ennustama () | klass | paigaldatud mudel, tüüp | |
| baas | ennustada | ennustama () | prob | paigaldatud mudel, tüüp | |
| baas | ennustada | ennustama () | vektor | paigaldatud mudel, tüüp | |
| rpart | Juhtimisparameetrid | rpart.control() | minsplit | Määrake minimaalne vaatluste arv sõlmes enne, kui algoritm poolitab | |
| minbucket | Määrake viimases märkuses, st lehel, minimaalne vaatluste arv | ||||
| maksimaalne sügavus | Määrake lõpliku puu mis tahes sõlme maksimaalne sügavus. Juuresõlme töödeldakse sügavusega 0 | ||||
| rpart | Juhtparameetriga rongimudel | rpart() | valem, df, meetod, kontroll |
Märkus. Treenige mudelit treeningandmete põhjal ja testige jõudlust nähtamatu andmekogumiga, st katsekomplektiga.