Scikit-Learn-Tutorial: Installation und Scikit-Learn-Beispiele
Was ist Scikit-Learn?
Scikit-lernen ist ein Open-Source Python Bibliothek für maschinelles Lernen. Sie unterstützt modernste Algorithmen wie KNN, XGBoost, Random Forest und SVM. Sie basiert auf NumPy. Scikit-learn wird häufig im Kaggle-Wettbewerb sowie von namhaften Technologieunternehmen verwendet. Sie hilft bei der Vorverarbeitung, Dimensionsreduzierung (Parameterauswahl), Klassifizierung, Regression, Clusterung und Modellauswahl.
Scikit-learn verfügt über die beste Dokumentation aller Open-Source-Bibliotheken. Es stellt Ihnen ein interaktives Diagramm zur Verfügung https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html.
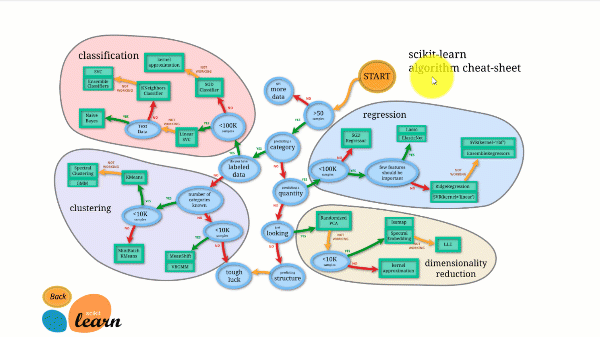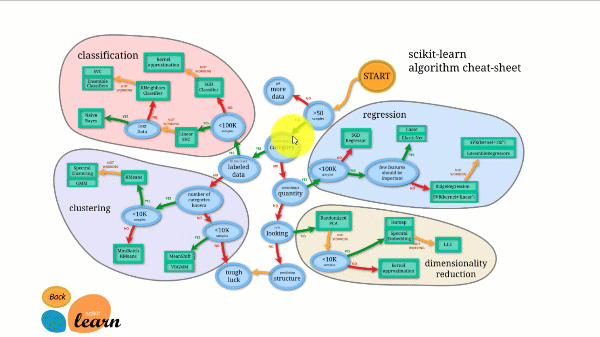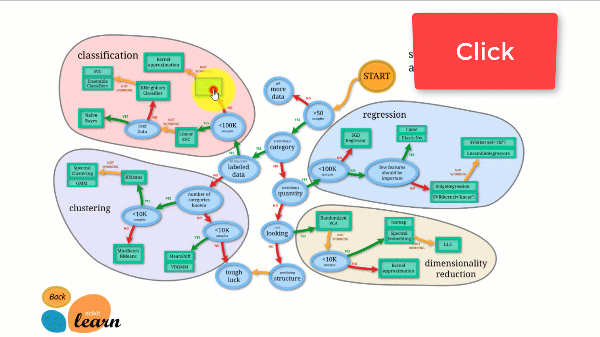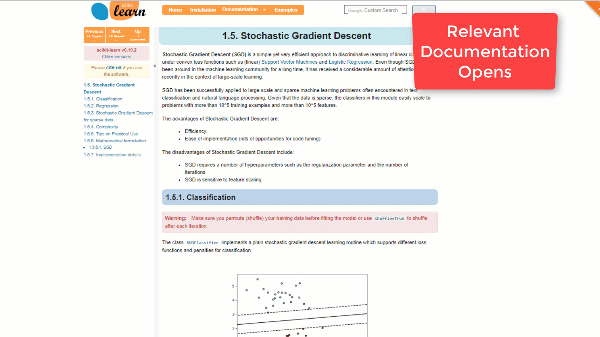
Scikit-learn ist nicht sehr schwierig zu verwenden und liefert hervorragende Ergebnisse. Scikit Learn unterstützt jedoch keine parallelen Berechnungen. Es ist möglich, damit einen Deep-Learning-Algorithmus auszuführen, aber es ist keine optimale Lösung, insbesondere wenn Sie wissen, wie man TensorFlow verwendet.
So laden Sie Scikit-learn herunter und installieren es
Jetzt hier Python Im Scikit-learn-Tutorial erfahren Sie, wie Sie Scikit-learn herunterladen und installieren:
Option 1: AWS
scikit-learn kann über AWS verwendet werden. Bitte siehe Das Docker-Image, auf dem scikit-learn vorinstalliert ist.
Um die Entwicklerversion zu verwenden, verwenden Sie den Befehl in Jupyter
import sys
!{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Option 2: Mac oder Windows mit Anaconda
Weitere Informationen zur Anaconda-Installation finden Sie unter https://www.guru99.com/download-install-tensorflow.html
Kürzlich haben die Entwickler von scikit eine Entwicklungsversion veröffentlicht, die häufige Probleme der aktuellen Version behebt. Wir fanden es bequemer, die Entwicklerversion anstelle der aktuellen Version zu verwenden.
So installieren Sie scikit-learn mit Conda Environment
Wenn Sie scikit-learn mit der Conda-Umgebung installiert haben, befolgen Sie bitte den Schritt zum Aktualisieren auf Version 0.20
Schritt 1) Aktivieren Sie die Tensorflow-Umgebung
source activate hello-tf
Schritt 2) Entfernen Sie Scikit Lean mit dem Befehl conda
conda remove scikit-learn
Schritt 3) Entwicklerversion installieren.
Installieren Sie die Scikit Learn-Entwicklerversion zusammen mit den erforderlichen Bibliotheken.
conda install -c anaconda git pip install Cython pip install h5py pip install git+git://github.com/scikit-learn/scikit-learn.git
Anmerkungen: Windows Der Benutzer muss eine Installation durchführen Microsoft visuell C++ 14. Sie erhalten es von werden auf dieser Seite erläutert
Scikit-Learn-Beispiel mit maschinellem Lernen
Dieses Scikit-Tutorial ist in zwei Teile unterteilt:
- Maschinelles Lernen mit scikit-learn
- So vertrauen Sie Ihrem Modell LIME an
Im ersten Teil wird detailliert beschrieben, wie man eine Pipeline aufbaut, ein Modell erstellt und die Hyperparameter optimiert, während der zweite Teil den neuesten Stand der Technik in Bezug auf die Modellauswahl bietet.
Schritt 1) Importieren Sie die Daten
Während dieses Scikit-Lern-Tutorials verwenden Sie den Datensatz für Erwachsene.
Weitere Informationen zu diesem Datensatz finden Sie unter. Wenn Sie mehr über die deskriptive Statistik erfahren möchten, verwenden Sie bitte die Tools „Dive“ und „Übersicht“.
Verweisen Dieses Tutorial Erfahren Sie mehr über Tauchgang und Überblick
Sie importieren den Datensatz mit Pandas. Beachten Sie, dass Sie den Typ der kontinuierlichen Variablen in das Float-Format konvertieren müssen.
Dieser Datensatz enthält acht kategoriale Variablen:
Die kategorialen Variablen sind in CATE_FEATURES aufgeführt
- Arbeiterklasse
- Ausbildung
- ehelich
- Beruf
- Beziehung
- Rennen
- Sex
- Heimatland
außerdem sechs kontinuierliche Variablen:
Die kontinuierlichen Variablen sind in CONTI_FEATURES aufgeführt
- Alter
- fnlwgt
- education_num
- Wertzuwachs
- Kapitalverlust
- Stunden_Woche
Beachten Sie, dass wir die Liste manuell ausfüllen, damit Sie eine bessere Vorstellung davon haben, welche Spalten wir verwenden. Eine schnellere Möglichkeit, eine Liste mit kategorialen oder kontinuierlichen Elementen zu erstellen, besteht darin, Folgendes zu verwenden:
## List Categorical
CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns
print(CATE_FEATURES)
## List continuous
CONTI_FEATURES = df_train._get_numeric_data()
print(CONTI_FEATURES)
Hier ist der Code zum Importieren der Daten:
# Import dataset
import pandas as pd
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
### Define continuous list
CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week']
### Define categorical list
CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
## Prepare the data
features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False)
df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64')
df_train.describe()
| Alter | fnlwgt | education_num | Wertzuwachs | Kapitalverlust | Stunden_Woche | |
|---|---|---|---|---|---|---|
| zählen | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| bedeuten | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| min | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Sie können die Anzahl der eindeutigen Werte der native_country-Features überprüfen. Sie können sehen, dass nur ein Haushalt aus Holland-Niederlande stammt. Dieser Haushalt wird uns keine Informationen liefern, jedoch durch einen Fehler während des Trainings.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Sie können diese nicht informative Zeile aus dem Datensatz ausschließen
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Als Nächstes speichern Sie die Position der kontinuierlichen Features in einer Liste. Sie benötigen es im nächsten Schritt zum Aufbau der Pipeline.
Der folgende Code durchläuft alle Spaltennamen in CONTI_FEATURES, ermittelt deren Position (dh die Nummer) und hängt sie dann an eine Liste namens conti_features an
## Get the column index of the categorical features
conti_features = []
for i in CONTI_FEATURES:
position = df_train.columns.get_loc(i)
conti_features.append(position)
print(conti_features)
[0, 2, 10, 4, 11, 12]
Der folgende Code erledigt die gleiche Aufgabe wie oben, jedoch für die kategoriale Variable. Der folgende Code wiederholt, was Sie zuvor getan haben, außer mit den kategorialen Funktionen.
## Get the column index of the categorical features
categorical_features = []
for i in CATE_FEATURES:
position = df_train.columns.get_loc(i)
categorical_features.append(position)
print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Sie können sich den Datensatz ansehen. Beachten Sie, dass jedes kategoriale Merkmal eine Zeichenfolge ist. Sie können ein Modell nicht mit einem Zeichenfolgenwert füttern. Sie müssen den Datensatz mithilfe einer Dummy-Variablen transformieren.
df_train.head(5)
Tatsächlich müssen Sie für jede Gruppe in der Funktion eine Spalte erstellen. Zunächst können Sie den folgenden Code ausführen, um die Gesamtzahl der benötigten Spalten zu berechnen.
print(df_train[CATE_FEATURES].nunique(),
'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9 education 16 marital 7 occupation 15 relationship 6 race 5 sex 2 native_country 41 dtype: int64 There are 101 groups in the whole dataset
Der gesamte Datensatz enthält 101 Gruppen, wie oben gezeigt. Beispielsweise haben die Merkmale der Arbeitsklasse neun Gruppen. Sie können den Namen der Gruppen mit den folgenden Codes visualisieren
unique() gibt die eindeutigen Werte der kategorialen Merkmale zurück.
for i in CATE_FEATURES:
print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Daher enthält der Trainingsdatensatz 101 + 7 Spalten. Die letzten sieben Spalten sind die fortlaufenden Merkmale.
Scikit-learn kann sich um die Konvertierung kümmern. Dies geschieht in zwei Schritten:
- Zuerst müssen Sie die Zeichenfolge in eine ID konvertieren. Beispielsweise hat State-gov die ID 1, Self-emp-not-inc ID 2 und so weiter. Die Funktion LabelEncoder erledigt dies für Sie
- Transponieren Sie jede ID in eine neue Spalte. Wie bereits erwähnt, hat der Datensatz 101 Gruppen-IDs. Daher gibt es 101 Spalten, die alle Gruppen der kategorialen Merkmale erfassen. Scikit-learn hat eine Funktion namens OneHotEncoder, die diesen Vorgang ausführt.
Schritt 2) Erstellen Sie den Zug-/Testsatz
Da der Datensatz nun fertig ist, können wir ihn im Verhältnis 80/20 aufteilen.
80 Prozent für den Trainingssatz und 20 Prozent für den Testsatz.
Sie können train_test_split verwenden. Das erste Argument ist der Datenrahmen für die Features und das zweite Argument ist der Beschriftungsdatenrahmen. Sie können die Größe des Testsatzes mit test_size angeben.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_train[features],
df_train.label,
test_size = 0.2,
random_state=0)
X_train.head(5)
print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Schritt 3) Erstellen Sie die Pipeline
Die Pipeline erleichtert die Versorgung des Modells mit konsistenten Daten.
Die Idee dahinter besteht darin, die Rohdaten in eine „Pipeline“ einzuspeisen, um Operationen durchzuführen.
Beispielsweise müssen Sie im aktuellen Datensatz die kontinuierlichen Variablen standardisieren und die kategorialen Daten konvertieren. Beachten Sie, dass Sie innerhalb der Pipeline jeden Vorgang ausführen können. Wenn der Datensatz beispielsweise „NAs“ enthält, können Sie diese durch den Mittelwert oder Median ersetzen. Sie können auch neue Variablen erstellen.
Sie haben die Wahl; Codieren Sie die beiden Prozesse fest oder erstellen Sie eine Pipeline. Die erste Wahl kann zu Datenlecks führen und im Laufe der Zeit zu Inkonsistenzen führen. Eine bessere Option ist die Verwendung der Pipeline.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Die Pipeline führt zwei Vorgänge aus, bevor sie den Logistikklassifizierer speist:
- Standardisieren Sie die Variable: „StandardScaler()“
- Konvertieren Sie die kategorialen Funktionen: OneHotEncoder(sparse=False)
Sie können die beiden Schritte mit dem make_column_transformer ausführen. Diese Funktion ist in der aktuellen Version von scikit-learn (0.19) nicht verfügbar. Mit der aktuellen Version ist es nicht möglich, den Label-Encoder und einen Hot-Encoder in der Pipeline auszuführen. Dies ist einer der Gründe, warum wir uns für die Entwicklerversion entschieden haben.
make_column_transformer ist einfach zu verwenden. Sie müssen definieren, auf welche Spalten die Transformation angewendet werden soll und welche Transformation durchgeführt werden soll. Um beispielsweise die kontinuierliche Funktion zu standardisieren, können Sie Folgendes tun:
- conti_features, StandardScaler() innerhalb von make_column_transformer.
- conti_features: Liste mit der kontinuierlichen Variablen
- StandardScaler: Standardisieren Sie die Variable
Das Objekt OneHotEncoder in make_column_transformer codiert die Beschriftung automatisch.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Sie können testen, ob die Pipeline mit fit_transform funktioniert. Der Datensatz sollte die folgende Form haben: 26048, 107
preprocess.fit_transform(X_train).shape
(26048, 107)
Der Datentransformator ist einsatzbereit. Sie können die Pipeline mit make_pipeline erstellen. Sobald die Daten transformiert sind, können Sie sie in die logistische Regression einspeisen.
model = make_pipeline(
preprocess,
LogisticRegression())
Ein Modell mit scikit-learn zu trainieren ist trivial. Sie müssen die Objektanpassung vor der Pipeline, also dem Modell, verwenden. Sie können die Genauigkeit mit dem Score-Objekt aus der scikit-learn-Bibliothek ausdrucken
model.fit(X_train, y_train)
print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Schließlich können Sie die Klassen mit predict_proba vorhersagen. Es gibt die Wahrscheinlichkeit für jede Klasse zurück. Beachten Sie, dass die Summe eins ergibt.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Schritt 4) Verwendung unserer Pipeline in einer Rastersuche
Das Optimieren der Hyperparameter (Variablen, die die Netzwerkstruktur wie versteckte Einheiten bestimmen) kann mühsam und anstrengend sein.
Eine Möglichkeit zur Bewertung des Modells könnte darin bestehen, die Größe des Trainingssatzes zu ändern und die Leistungen zu bewerten.
Sie können diese Methode zehnmal wiederholen, um die Bewertungsmetriken anzuzeigen. Allerdings ist es zu viel Arbeit.
Stattdessen bietet scikit-learn eine Funktion zur Parameteroptimierung und Kreuzvalidierung.
Quervalidierung
Kreuzvalidierung bedeutet, dass der Trainingssatz während des Trainings n-mal in Falten verschoben wird und dann das Modell n-mal ausgewertet wird. Wenn cv beispielsweise auf 10 eingestellt ist, wird der Trainingssatz zehnmal trainiert und ausgewertet. In jeder Runde wählt der Klassifikator zufällig neun Faltungen aus, um das Modell zu trainieren, und die zehnte Faltung ist für die Bewertung bestimmt.
Rastersuche
Jeder Klassifikator verfügt über zu optimierende Hyperparameter. Sie können verschiedene Werte ausprobieren oder ein Parameterraster festlegen. Wenn Sie die offizielle Website von scikit-learn besuchen, können Sie sehen, dass der Logistikklassifikator verschiedene Parameter optimieren muss. Um das Training zu beschleunigen, optimieren Sie den C-Parameter. Es steuert den Regularisierungsparameter. Es sollte positiv sein. Ein kleiner Wert verleiht dem Regularisierer mehr Gewicht.
Sie können das Objekt GridSearchCV verwenden. Sie müssen ein Wörterbuch erstellen, das die zu optimierenden Hyperparameter enthält.
Sie listen die Hyperparameter auf, gefolgt von den Werten, die Sie ausprobieren möchten. Um beispielsweise den C-Parameter zu optimieren, verwenden Sie:
- 'logisticregression__C': [0.1, 1.0, 1.0]: Dem Parameter werden der Name des Klassifikators in Kleinbuchstaben und zwei Unterstriche vorangestellt.
Das Modell probiert vier verschiedene Werte aus: 0.001, 0.01, 0.1 und 1.
Sie trainieren das Modell mit 10 Falten: cv=10
from sklearn.model_selection import GridSearchCV
# Construct the parameter grid
param_grid = {
'logisticregression__C': [0.001, 0.01,0.1, 1.0],
}
Sie können das Modell mit GridSearchCV mit den Parametern gri und cv trainieren.
# Train the model
grid_clf = GridSearchCV(model,
param_grid,
cv=10,
iid=False)
grid_clf.fit(X_train, y_train)
AUSGABE
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))]),
fit_params=None, iid=False, n_jobs=1,
param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
Um auf die besten Parameter zuzugreifen, verwenden Sie best_params_
grid_clf.best_params_
AUSGABE
{'logisticregression__C': 1.0}
Nachdem das Modell mit vier verschiedenen Regularisierungswerten trainiert wurde, ist der optimale Parameter
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
Beste logistische Regression aus der Rastersuche: 0.850891
So greifen Sie auf die vorhergesagten Wahrscheinlichkeiten zu:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
XGBoost-Modell mit scikit-learn
Versuchen wir Scikit-learn-Beispiele, um einen der besten Klassifikatoren auf dem Markt zu trainieren. XGBoost ist eine Verbesserung gegenüber dem Random Forest. Der theoretische Hintergrund des Klassifikators liegt außerhalb des Rahmens dieses Python Scikit-Tutorial. Bedenken Sie, dass XGBoost viele Kaggle-Wettbewerbe gewonnen hat. Bei einer durchschnittlichen Datensatzgröße kann es genauso gut oder sogar besser abschneiden als ein Deep-Learning-Algorithmus.
Das Trainieren des Klassifikators ist eine Herausforderung, da eine große Anzahl an Parametern angepasst werden muss. Sie können natürlich GridSearchCV verwenden, um den Parameter für Sie auszuwählen.
Sehen wir uns stattdessen an, wie Sie die optimalen Parameter besser finden können. Das Trainieren von GridSearchCV kann mühsam und sehr langwierig sein, wenn Sie viele Werte übergeben. Der Suchraum wächst mit der Anzahl der Parameter. Eine bevorzugte Lösung ist die Verwendung von RandomizedSearchCV. Diese Methode besteht darin, die Werte jedes Hyperparameters nach jeder Iteration zufällig auszuwählen. Wenn der Klassifikator beispielsweise über 1000 Iterationen trainiert wird, werden 1000 Kombinationen ausgewertet. Es funktioniert mehr oder weniger so. GridSearchCV
Sie müssen xgboost importieren. Wenn die Bibliothek nicht installiert ist, verwenden Sie bitte pip3 install xgboost oder
use import sys
!{sys.executable} -m pip install xgboost
In Jupyter Umwelt
Nächstes
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Der nächste Schritt in diesem Scikit Python Das Tutorial beinhaltet die Angabe der Parameter, die angepasst werden sollen. Sie können in der offiziellen Dokumentation nachsehen, welche Parameter angepasst werden sollen. Python Im Sklearn-Tutorial wählen Sie nur zwei Hyperparameter mit jeweils zwei Werten aus. Das Training von XGBoost nimmt viel Zeit in Anspruch. Je mehr Hyperparameter im Raster vorhanden sind, desto länger müssen Sie warten.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Sie konstruieren eine neue Pipeline mit dem XGBoost-Klassifikator. Sie entscheiden sich, 600 Schätzer zu definieren. Beachten Sie, dass n_estimators ein Parameter ist, den Sie anpassen können. Ein hoher Wert kann zu Überanpassung führen. Sie können selbst verschiedene Werte ausprobieren, aber seien Sie sich bewusst, dass dies Stunden dauern kann. Sie verwenden den Standardwert für die anderen Parameter
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Sie können die Kreuzvalidierung mit dem Kreuzvalidator Stratified K-Folds verbessern. Sie konstruieren hier nur drei Falten, um die Berechnung zu beschleunigen, aber die Qualität zu verringern. Erhöhen Sie diesen Wert zu Hause auf 5 oder 10, um die Ergebnisse zu verbessern.
Sie entscheiden sich dafür, das Modell über vier Iterationen zu trainieren.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Die zufällige Suche ist einsatzbereit, Sie können das Modell trainieren
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False) random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min [Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Wie Sie sehen, hat XGBoost eine bessere Punktzahl als die vorherige logistische Regression.
print("besten parameter", random_search.best_params_)
print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
besten parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Erstellen Sie DNN mit MLPClassifier in scikit-learn
Schließlich können Sie mit scikit-learn einen Deep-Learning-Algorithmus trainieren. Die Methode ist die gleiche wie bei den anderen Klassifikatoren. Der Klassifikator ist bei MLPClassifier verfügbar.
from sklearn.neural_network import MLPClassifier
Sie definieren den folgenden Deep-Learning-Algorithmus:
- Adam-Löser
- Relu-Aktivierungsfunktion
- Alpha = 0.0001
- Losgröße 150
- Zwei verborgene Schichten mit jeweils 100 und 50 Neuronen
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Sie können die Anzahl der Schichten ändern, um das Modell zu verbessern
model_dnn.fit(X_train, y_train)
print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN-Regressionswert: 0.821253
LIME: Vertrauen Sie Ihrem Modell
Da Sie nun über ein gutes Modell verfügen, benötigen Sie ein Werkzeug, um ihm vertrauen zu können. Maschinelles Lernen Algorithmen, insbesondere Random Forest und neuronale Netzwerke, gelten als Black-Box-Algorithmen. Anders gesagt: Sie funktionieren, aber niemand weiß, warum.
Drei Forscher haben ein großartiges Tool entwickelt, um zu sehen, wie der Computer eine Vorhersage trifft. Der Artikel trägt den Titel „Warum sollte ich Ihnen vertrauen?“
Sie entwickelten einen Algorithmus namens Lokale interpretierbare modellunabhängige Erklärungen (LIME).
Nehmen Sie ein Beispiel:
Manchmal weiß man nicht, ob man einer Vorhersage durch maschinelles Lernen vertrauen kann:
Ein Arzt zum Beispiel kann einer Diagnose nicht vertrauen, nur weil ein Computer sie sagt. Sie müssen auch wissen, ob Sie dem Modell vertrauen können, bevor Sie es in Produktion nehmen.
Stellen Sie sich vor, wir könnten verstehen, warum jeder Klassifikator selbst unglaublich komplizierte Modelle wie neuronale Netze, Zufallswälder oder SVMs mit jedem Kernel vorhersagt
Wir werden es leichter haben, einer Vorhersage zu vertrauen, wenn wir die Gründe dafür verstehen können. Anhand des Beispiels mit dem Arzt: Wenn das Modell ihm sagen würde, welche Symptome wesentlich sind, würden Sie ihm vertrauen, ist es auch einfacher herauszufinden, ob Sie dem Modell nicht vertrauen sollten.
Lime kann Ihnen sagen, welche Merkmale die Entscheidungen des Klassifikators beeinflussen
Datenaufbereitung
Dies sind ein paar Dinge, die Sie ändern müssen, um LIME auszuführen python. Zunächst müssen Sie Kalk im Terminal installieren. Sie können Pip Install Lime verwenden
Lime verwendet das LimeTabularExplainer-Objekt, um das Modell lokal anzunähern. Dieses Objekt erfordert:
- ein Datensatz im Numpy-Format
- Der Name der Features: feature_names
- Der Name der Klassen: class_names
- Der Index der Spalte der kategorialen Features: categorical_features
- Der Name der Gruppe für jedes kategoriale Feature: categorical_names
Erstellen Sie einen Numpy-Zugsatz
Sie können df_train von Pandas nach kopieren und konvertieren numpig sehr leicht
df_train.head(5) # Create numpy data df_lime = df_train df_lime.head(3)
Rufen Sie den Klassennamen ab Auf das Label kann mit dem Objekt unique() zugegriffen werden. Das solltest du sehen:
- '<= 50K'
- '> 50K'
# Get the class name class_names = df_lime.label.unique() class_names
array(['<=50K', '>50K'], dtype=object)
Index der Spalte der kategorialen Merkmale
Sie können die Methode verwenden, die Sie zuvor gelernt haben, um den Namen der Gruppe zu erhalten. Sie codieren das Label mit LabelEncoder. Sie wiederholen den Vorgang für alle kategorialen Merkmale.
##
import sklearn.preprocessing as preprocessing
categorical_names = {}
for feature in CATE_FEATURES:
le = preprocessing.LabelEncoder()
le.fit(df_lime[feature])
df_lime[feature] = le.transform(df_lime[feature])
categorical_names[feature] = le.classes_
print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Nachdem der Datensatz nun fertig ist, können Sie die verschiedenen Datensätze erstellen, wie in den folgenden Scikit-Lernbeispielen gezeigt. Sie transformieren die Daten tatsächlich außerhalb der Pipeline, um Fehler mit LIME zu vermeiden. Der Trainingssatz im LimeTabularExplainer sollte ein Numpy-Array ohne String sein. Mit der oben beschriebenen Methode haben Sie bereits einen Trainingsdatensatz konvertiert.
from sklearn.model_selection import train_test_split
X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features],
df_lime.label,
test_size = 0.2,
random_state=0)
X_train_lime.head(5)
Sie können die Pipeline mit den optimalen Parametern von XGBoost erstellen
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))])
Sie erhalten eine Warnung. Die Warnung erklärt, dass Sie vor der Pipeline keinen Label-Encoder erstellen müssen. Wenn Sie LIME nicht verwenden möchten, können Sie die Methode aus dem ersten Teil des Tutorials „Machine Learning mit Scikit-learn“ verwenden. Andernfalls können Sie bei dieser Methode bleiben, zuerst einen codierten Datensatz erstellen und den Hot-One-Encoder innerhalb der Pipeline abrufen.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Bevor wir LIME in Aktion verwenden, erstellen wir ein Numpy-Array mit den Merkmalen der falschen Klassifizierung. Sie können diese Liste später verwenden, um eine Vorstellung davon zu bekommen, was den Klassifizierer in die Irre geführt hat.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1)
temp['predicted'] = model_xgb.predict(X_test_lime)
temp['wrong']= temp['label'] != temp['predicted']
temp = temp.query('wrong==True').drop('wrong', axis=1)
temp= temp.sort_values(by=['label'])
temp.shape
(826, 16)
Sie erstellen eine Lambda-Funktion, um die Vorhersage aus dem Modell mit den neuen Daten abzurufen. Sie werden es bald brauchen.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float) X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Sie konvertieren den Pandas-Datenrahmen in ein Numpy-Array
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
import lime
import lime.lime_tabular
### Train should be label encoded not one hot encoded
explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime ,
feature_names = features,
class_names=class_names,
categorical_features=categorical_features,
categorical_names=categorical_names,
kernel_width=3)
Wählen wir einen zufälligen Haushalt aus dem Testsatz aus und sehen wir uns die Modellvorhersage an und sehen, wie der Computer seine Wahl getroffen hat.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Sie können den Erklärer mit EXPLAIN_INSTANCE verwenden, um die Erklärung hinter dem Modell zu überprüfen
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)
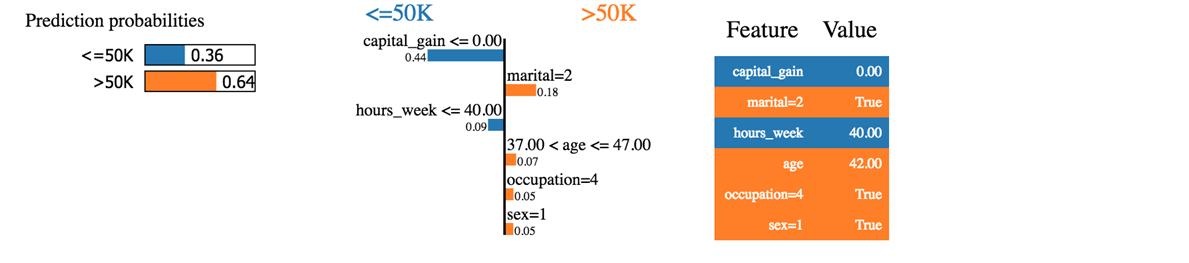
Wir können sehen, dass der Klassifikator den Haushalt richtig vorhergesagt hat. Das Einkommen liegt tatsächlich über 50.
Als erstes können wir sagen, dass der Klassifikator sich bei den vorhergesagten Wahrscheinlichkeiten nicht so sicher ist. Die Maschine sagt mit einer Wahrscheinlichkeit von 50 % voraus, dass der Haushalt ein Einkommen von über 64 hat. Diese 64 % setzen sich aus Kapitalgewinn und Ehegatteneinkommen zusammen. Die blaue Farbe trägt negativ zur positiven Klasse bei und die orange Linie positiv.
Der Klassifikator ist verwirrt, weil der Kapitalgewinn dieses Haushalts null ist, während der Kapitalgewinn normalerweise ein guter Indikator für Wohlstand ist. Außerdem arbeitet der Haushalt weniger als 40 Stunden pro Woche. Alter, Beruf und Geschlecht tragen positiv zum Klassifikator bei.
Wenn der Familienstand ledig wäre, hätte der Klassifikator ein Einkommen unter 50 vorausgesagt (0.64-0.18 = 0.46)
Wir können es mit einem anderen Haushalt versuchen, der falsch klassifiziert wurde
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1
print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K predicted >50K Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)

Der Klassifikator hat ein Einkommen unter 50 vorhergesagt, obwohl dies unwahr ist. Dieser Haushalt scheint seltsam. Es gibt weder einen Kapitalgewinn noch einen Kapitalverlust. Er ist geschieden und 60 Jahre alt, und es handelt sich um ein gebildetes Volk, d. h. education_num > 12. Gemäß dem Gesamtmuster sollte dieser Haushalt, wie durch den Klassifikator erklärt, ein Einkommen unter 50 erzielen.
Sie versuchen, mit LIME herumzuspielen. Sie werden grobe Fehler am Klassifikator bemerken.
Sie können den GitHub des Besitzers der Bibliothek überprüfen. Sie bieten zusätzliche Dokumentation zur Bild- und Textklassifizierung.
Zusammenfassung
Nachfolgend finden Sie eine Liste einiger nützlicher Befehle mit der Scikit-Learn-Version >=0.20
| Erstellen Sie einen Trainings-/Testdatensatz | Auszubildende trennten sich |
| Bauen Sie eine Pipeline | |
| Wählen Sie die Spalte aus und wenden Sie die Transformation an | makecolumntransformer |
| Art der Transformation | |
| standardisieren | Standardskala |
| Minimal Maximal | MinMaxSkalierer |
| Normalisieren | Normalizer |
| Fehlenden Wert zurechnen | unterstellen |
| Kategorisch umwandeln | OneHotEncoder |
| Passen Sie die Daten an und transformieren Sie sie | fit_transform |
| Machen Sie die Pipeline | make_pipeline |
| Grundmodell | |
| logistische Regression | Logistische Regression |
| XGBoost | XGBClassifier |
| Neuronales Netz | MLPClassifier |
| Rastersuche | GridSearchCV |
| Zufällige Suche | RandomizedSearchCV |