10 Bedste Test Data Generator Værktøjer (2026)

Har du nogensinde følt dig fastlåst, når værktøjer af dårlig kvalitet har forsinket din testproces? At vælge de forkerte værktøjer fører ofte til upålidelige datasæt, tidskrævende manuelle rettelser, hyppige fejl i arbejdsgange og endda dataafvigelser, der afsporer hele projekter. Det kan også forårsage compliance-risici, inkonsekvent testdækning, spildte ressourcer og unødvendigt omarbejde. Disse problemer skaber frustration og lavere produktivitet. På den anden side forenkler de rigtige værktøjer processen, forbedrer nøjagtigheden og sparer værdifuld tid.
jeg brugte løbet 180 timer omhyggeligt at undersøge og sammenligne 40+ værktøjer til testdatagenerator inden jeg lavede denne guide. Ud af disse har jeg udvalgt de 12 mest effektive muligheder. Denne anmeldelse er baseret på min førstehåndserfaring med disse værktøjer. I denne artikel deler jeg deres vigtigste funktioner, fordele og ulemper samt priser for at give dig fuldstændig klarhed. Sørg for at læse til slutningen for at vælge det bedste match til dine behov. Læs mere…
Bedste Test Data Generator Værktøjer: Topvalg!
| Testdata Generator Værktøj | Nøglefunktioner | Gratis prøveperiode / garanti | Link |
|---|---|---|---|
| EMS Data Generator | JSON-typeunderstøttelse, databasemigrering, datakodning | 30-dages gratis prøveperiode | Få mere at vide |
| Informatica TDM | Automatiseret maskering af følsomme data, præbyggede acceleratorer, compliance-rapportering | Gratis demo tilgængelig | Få mere at vide |
| dobbelt | Stærk overvågning, database-API-integration, datastyring | Anmod om demo | Få mere at vide |
| Broadcom EDMS | Samlet PII-scanning, skalerbar maskering over store datasæt, understøttelse af NoSQL-databaser | Anmod om demo | Få mere at vide |
| SAP Test Data Migration Server | Snapshot-funktion, dataudvælgelsesparallelisering, oprettelse af aktiv skal | Anmod om demo | Få mere at vide |
1) EMS Data Generator
EMS Data Generator er et intuitivt værktøj, der er skræddersyet til at generere syntetiske data på tværs af flere databasetabeller samtidigt. Jeg satte pris på, hvor nemt det gjorde det muligt for mig at konfigurere randomiserede datasæt og forhåndsvise resultater før brug. Dets skemabaserede genereringsfunktioner og brede understøttelse af datatyper som ENUM, SET og JSON gøre den fleksibel nok til at håndtere forskellige testbehov.
I ét tilfælde udnyttede jeg EMS Data Generator til seeding af testdatabaser under et migreringsprojekt, og det strømlinede processen uden at gå på kompromis med dataenes nøjagtighed. Værktøjets evne til at generere parametriserede datasæt og gemme dem som SQL-scripts sikrer problemfri testning, hvilket gør det til et pålideligt valg for databaseadministratorer og QA-ingeniører, der håndterer både små og store arbejdsbyrder.
Funktioner:
- Datakodning: Denne funktion giver dig mulighed for at håndtere forskellige kodningsmuligheder problemfrit, hvilket er afgørende, når du arbejder på tværs af flere miljøer. Den understøtter Unicode-filer, så selv flersprogede testdata dækkes uden besvær. Jeg brugte den til at administrere scripts problemfrit, og resultaterne var altid ensartede.
- Programinstallation: Den pakker bekvemt genererede testdata i installationspakker, hvilket sikrer, at alt forbliver samlet til øjeblikkelig brug. Jeg fandt dette yderst nyttigt, når jeg hurtigt skulle sætte miljøer op på nye systemer. Mens jeg testede denne funktion, bemærkede jeg, hvor meget den reducerede gentagne opsætningsopgaver.
- Databasemigration: Du kan nemt migrere mellem databasesystemer uden at bekymre dig om at miste kritiske oplysninger. Det har hjulpet mig med at overføre store datasæt fra MySQL til PostgreSQL problemfrit. Jeg vil anbefale at tjekke migreringslogfiler grundigt for at verificere skemakompatibilitet, før implementering i produktion.
- Understøttelse af JSON-datatyper: Den understøtter JSON-datatyper til populære databaser som f. Oracle 21c, MySQL 8, Ildfugl 4 og PostgreSQL 16Dette gør den fremtidssikret til moderne applikationer, der er afhængige af dokumentlagring. I ét tilfælde brugte jeg den til at validere API-testscenarier ved at generere JSON direkte i databasen.
- Understøttelse af komplekse datatyper: Ud over standardfelter håndterer værktøjet SET-, ENUM- og GEOMETRY-typer, hvilket er et stort plus for avancerede databasemodeller. Jeg har testet dette, mens jeg modellerede lokationsbaserede datasæt, og det fungerede perfekt uden at kræve manuelle justeringer.
- Forhåndsvisning og redigering af genererede data: Denne funktion giver dig mulighed for at forhåndsvise og ændre genererede data, før de færdiggøres, hvilket sparer tid under fejlfinding. Værktøjet giver dig mulighed for at gemme ændringer direkte i SQL-scripts, hvilket gør integration i CI/CD-pipelines nemmere. Jeg foreslår at bruge versionskontrol til disse scripts for at opretholde reproducerbarhed på tværs af testkørsler.
FORDELE
ULEMPER
Pris:
Her er nogle af de startplaner, der tilbydes af EMS Data Generator
| EMS Data Generator til InterBase/Firebird (Business) + 1 års vedligeholdelse | EMS Data Generator forum Oracle (Erhverv) + 1 års vedligeholdelse | EMS Data Generator til SQL Server (Business) + 1 års vedligeholdelse |
|---|---|---|
| $110 | $110 | $110 |
Gratis prøveversion: 30-dages prøveversion
Forbindelse: https://www.sqlmanager.net/products/datagenerator
2) Informatica Test Data Management
Informatica Test Data Management er en af de mest avancerede løsninger, jeg har arbejdet med til oprettelse af syntetiske data og robust beskyttelse. Jeg var imponeret over, hvor problemfrit det automatiserede dataidentifikation og maskering på tværs af komplekse databaser, hvilket sparede mig for tidskrævende manuelle kontroller. Muligheden for at maskere følsomme data, samtidig med at skemaintegriteten blev opretholdt, gav mig tillid til at opfylde compliance-krav uden at forsinke projekter.
Jeg fandt det særligt nyttigt, når jeg forberedte parametriserede datasæt til automatiserede testcases, da det lod mig oprette delmængder uden at overbelaste infrastrukturen. Denne tilgang forbedrede ikke kun ydeevnen, men gjorde også testcyklusser hurtigere og mere omkostningseffektive. Informatica TDM er virkelig fremragende, når det kommer til håndtering af følsomme produktionsdata, der skal maskeres og genbruges i sikre testmiljøer.
Funktioner:
- Automatiseret dataidentifikation: Denne funktion identificerer hurtigt følsomme data på tværs af flere databaser, hvilket gør det meget nemmere at administrere compliance og sikkerhed. Den anvender løbende maskering, hvilket sikrer, at ingen rådata forbliver eksponeret under testning. Jeg fandt dette især nyttigt, når jeg arbejdede med sundhedsdatasæt, hvor HIPAA-compliance var et must.
- Dataundersæt: Du kan oprette mindre datasæt med høj værdi, der fremskynder testudførelsen, samtidig med at infrastrukturomkostningerne sænkes. Dette er yderst praktisk til regressionstest, hvor gentagne kørsler kræver hurtig adgang til ensartede datasæt. Mens jeg brugte dette, bemærkede jeg, at testcyklusser blev mere effektive med reduceret systembelastning.
- Præbyggede acceleratorer: Den leveres med indbyggede maskeringsacceleratorer til almindelige dataelementer, hvilket hjælper dig med at overholde reglerne uden at skulle opfinde hjulet på ny. Disse acceleratorer sparer tid og forbedrer pålideligheden, når du håndterer fortrolige felter som CPR-numre eller kortoplysninger. Jeg foreslår at undersøge tilpasningsmuligheder for branchespecifikke dataformater for at maksimere værdien.
- Overvågning og rapportering: Denne funktion giver detaljeret overvågning og revisionsklar rapportering for risiko og compliance. Det bringer governance-teams direkte ind i processen, hvilket hjælper med at tilpasse QA til virksomhedens datapolitikker. Jeg vil anbefale at planlægge automatiserede rapporter i CI/CD-pipelines, så compliance-kontroller bliver en del af den daglige testning snarere end et sidste-øjebliks-kaos.
- Ensartet datastyring: Det sikrer, at der anvendes ensartede politikker på tværs af virksomheden, hvilket reducerer compliance-risici. Jeg har set, hvordan dette hjælper store organisationer med at undgå siloer, samtidig med at de opretholder nøjagtige og pålidelige data.
- Automatiseret dataintelligens: Den udnytter AI-drevet automatisering til at levere kontinuerlig indsigt i dataforbrug, -afstamning og -kvalitet. Dette forbedrer ikke kun gennemsigtigheden, men fremskynder også beslutningstagningen. Under testningen bemærkede jeg, at det reducerede den manuelle indsats med at spore dataoprindelse og -transformationer betydeligt.
FORDELE
ULEMPER
Pris:
- Pris: Du kan anmode om et tilbud på salg
- Gratis prøveversion: Du får en gratis demo
3) Dobbelt
Doble skiller sig ud som et praktisk valg for organisationer, der har brug for struktureret håndtering af testdata. Da jeg brugte det til at organisere store sæt af randomiserede datasæt på tværs af afdelinger, bemærkede jeg, hvor meget mere gnidningsfri testningen blev. Værktøjet gør det nemt at rense, konvertere og kategorisere data, hvilket sikrer nøjagtighed ved håndtering af forskellige testplaner. Dets evne til at integrere med API'er og business intelligence-værktøjer tilføjer reel værdi i de daglige testworkflows.
Jeg satte pris på, hvordan det strømlinede test på feltniveau ved at konsolidere resultater i logiske mapper, hvilket reducerede forvirringen omkring spredte datasæt. Efter at have oplevet dets pålidelighed i håndteringen af maskerede produktionsdata, vil jeg sige, at Doble er særligt nyttigt for teams, der prioriterer datakonsistens og -styring, samtidig med at det reducerer omkostningerne ved manuel organisering.
Funktioner:
- Håndtering af data: Denne funktion giver dig mulighed for at administrere forskellige testdatatyper, såsom SFRA og DTA, med ensartethed. Den hjælper med at opretholde produktiviteten på tværs af projekter og understøtter skemabaseret generering, hvor det er nødvendigt. Jeg har personligt brugt den til at oprette organiserede, genanvendelige skabeloner, der reducerer den manuelle indsats.
- Stærkt tilsyn: Det sørger for tilsyn for at håndhæve robuste standarder for datastyring. Dette er ikke kun reducerer overflødige processer men forbedrer også compliance-venlige arbejdsgange. Mens jeg testede det, bemærkede jeg, hvor godt det integreres i DevOps-pipelines i virksomhedsklassen, hvilket gør det nemmere at opdage ineffektivitet, før den eskalerer.
- Datastyring: Denne funktion sikrer logisk lagring og sikkerhedskopiering, hvilket holder testdata strukturerede og tilgængelige. Den indbygger pålidelighed i performance- og regressionstestscenarier. Jeg anbefaler at udnytte dette, når du arbejder med maskerede produktionsdata, da det strømliner revision, samtidig med at sikkerheden bevares.
- Database API: Database API'en leverer et fleksibelt servicelag til hentning af testdata og analytiske resultater såsom FRANK™-scorer. Den understøtter integration med BI-værktøjer, hvilket muliggør automatiseringsklare rapporteringspipelines. Jeg foreslår at bruge dette til CI/CD-support, hvor dataindsigt skal være kontinuerligt tilgængelig.
- Standardiserede processer: Denne funktion fokuserer på at eliminere manuelle og redundante processer ved at standardisere, hvordan data indsamles og lagres. Den muliggør kompatibilitet på tværs af platforme og reducerer risikoen for fragmenterede arbejdsgange. Jeg har set, at den sparer timer under omfattende softwarevalideringsindsatser, hvor dækning af edge cases var afgørende.
- Vidensressourcer og træning: Doble giver adgang til strukturerede vejledninger og træning, der hjælper teams med at implementere bedste praksis. Dette sikrer konsistens i, hvordan testdata håndteres på tværs af afdelinger. Derudover bemærkede jeg, at det skræddersyede læringsmateriale gør implementeringen hurtigere, selv i agile-venlige miljøer.
FORDELE
ULEMPER
Pris:
- Pris: Du kan anmode om et tilbud på salg
- Gratis prøveversion: Du anmoder om en demo
Forbindelse: https://www.doble.com/product/test-data-management/
4) Broadcom EDMS
Broadcom EDMS er en kraftfuld platform til generering af testdata, som jeg fandt særligt effektiv til at bygge skemabaserede og regeldrevne datasæt. Jeg kunne godt lide, hvordan den tillod mig at udtrække og genbruge forretningsdata, samtidig med at jeg anvendte maskeringsregler, der beskyttede følsomme oplysninger. Dens delmængder – som sletning, indsættelse og afkortning – gav præcis kontrol over oprettelsen af datasæt, hvilket gjorde test mere tilpasningsdygtig.
I ét scenarie brugte jeg det til at generere randomiserede datasæt til API-testning, hvilket sikrede, at edge cases blev dækket uden at eksponere produktionsdata. Den omfattende detektion af fortrolige kilder kombineret med planlægningsmuligheder gjorde det lettere at opretholde compliance, samtidig med at det fremskyndede automatiserede testcases. Broadcom EDMS udmærker sig ved at balancere avanceret sikkerhed med fleksibilitet i dataforberedelse.
Funktioner:
- Dataassistent Plus: Denne funktion skaber realistiske, skemabaserede syntetiske data ved hjælp af regeldrevne algoritmer, der efterligner produktionslogik uden at eksponere følsomme oplysninger. Jeg har set, at den fremskynder testcase-beredskabet ved at give testere mulighed for at simulere sjældne fejltilstande uden at vente på produktionsdata.
- Samlet PII-scanning, maskering og revisionsworkflow: Den lokaliserer, klassificerer og håndterer PII sikkert gennem en problemfri arbejdsgang – scanning, maskering og derefter revision for overholdelse. Den sikrer, at privatlivslove som GDPR/HIPAA overholdes, hvilket gør data kompatible og sikre før testbrug.
- Skalerbar maskering over store datasæt: Den understøtter maskering af store datamængder med minimal konfigurationsoverhead. Den kan skalere maskeringsjob horisontalt (f.eks. på Kubernetes-klynger), automatisk allokere ressourcer afhængigt af volumen og derefter nedbryde dem efter brug.
- Understøttelse af NoSQL-databaser: Du kan nu anvende praksisser for håndtering af testdata (maskering, syntetisk generering osv.) på NoSQL platforme som MongoDB, CassandraBigQueryDette udvider anvendeligheden ud over relationelle systemer. Jeg har brugt dette i miljøer, hvor blandede relationelle og dokumentdatabaser forårsagede forsinkelser. Dermed har jeg ét værktøj, der dækker både forbedret reproducerbarhed og nem integration.
- Selvbetjeningsportal og datareservation: Testere kan bruge en portal til at anmode om og reservere specifikke datasæt (f.eks. finde og reservere operationer) uden at kopiere hele produktionssæt. Dette hjælper med at reducere leveringstider og undgår unødvendig dataduplikering.
- Integration af CI/CD og DevOps-pipeline: Værktøjet understøtter integration af testdatalevering, generering af syntetiske data, maskering og datadelsætoperationer i CI/CD-pipelines. Det flytter TDM "til venstre" - dvs. til design- og byggefaser - så testcyklusserne er kortere, og testning er mindre af en flaskehals.
FORDELE
ULEMPER
Pris:
- Pris: Du kan kontakte salgsafdelingen for at få et tilbud
- Gratis prøveversion: Du anmoder om en demo
5) SAP Test Data Migration Server
SAP Test Data Migration Server er en pålidelig løsning til at generere og migrere realistiske SAP testdata på tværs af systemer. Jeg fandt det særligt effektivt, når jeg håndterede testscenarier i stor skala, fordi det strømlinede mine arbejdsgange, samtidig med at det sikrede overholdelse af standarder for databeskyttelse. Den indbyggede kryptering af følsomme oplysninger gav mig tillid til, at testdata afspejlede produktionsdata sikkert.
I praksis brugte jeg det til at replikere komplekse datasæt til træningsmiljøer, hvilket drastisk reducerede opsætningstid og infrastrukturomkostninger. Funktioner som parallelisering af dataudvælgelse og oprettelse af aktive shells gjorde processen yderst effektiv, hvilket gjorde det muligt for mig at udføre automatiserede testcases med maskerede produktionsdata og simulere end-to-end-testning på rekordtid.
Funktioner:
- Snapshot funktion: Denne funktion giver dig mulighed for at indsamle et logisk øjebliksbillede af datamængder, hvilket giver dig et pålideligt overblik over en specifik lagringstilstand. Den hjælper med at reproducere ensartede miljøer til test og træning uden at duplikere hele datasæt. Jeg har brugt den til at strømline regressionstestning, og den sparer virkelig tid.
- Parallelisering af dataudvælgelse: Det giver dig mulighed for køre flere batchjob samtidigt ved udvælgelse af data. Dette fremskynder migreringsprocessen og sikrer, at oprettelsen af testdata i stor skala er mere effektiv. Jeg vil anbefale at bruge mindre jobopdelinger ved håndtering af komplekse SAP landskaber for at undgå flaskehalse.
- Oprettelse af brugerroller: Du kan definere rollebaseret adgang på tværs af hele datamigreringsprocestræet. Det sikrer, at testere og udviklere kun ser de data, de har brug for, hvilket forbedrer både sikkerhed og compliance. Mens jeg brugte dette, bemærkede jeg, hvordan det forenklede revision under testcyklusser.
- Oprettelse af aktiv skal: Denne funktion gør det muligt at kopiere applikationsdata fra én SAP system til et andet ved hjælp af kernesystemets kopieringsprocessen. Det er yderst nyttigt til hurtigt at konfigurere træningssystemer. Jeg testede det i et projekt, hvor en klient havde brug for flere sandkassemiljøer, og det reducerede provisioneringstiden drastisk.
- Dataforvrængning: Værktøjet inkluderer effektive dataforvrængningsmetoder til at anonymisere følsomme forretningsdata under overførsler. Det hjælper organisationer overhold GDPR og andre privatlivsreglerDu vil bemærke, hvor fleksible scrambling-reglerne er, især når de skræddersys til økonomiske og HR-data.
- Datamigrering på tværs af systemer: Den understøtter overførsel af testdata på tværs af ikke-forbundne datacentre, hvilket gør den yderst værdifuld for globale virksomheder. Denne funktion er især praktisk for teams, der arbejder med kontinuerlig integration og DevOps-pipelines, hvor miljøer er distribueret over hele verden. Jeg foreslår at planlægge migreringer i perioder med lav trafik for at sikre optimal ydeevne.
FORDELE
ULEMPER
Pris:
- Pris: Du kan kontakte salgsafdelingen for at få et tilbud
- Gratis prøveversion: Du anmoder om en demo
6) Upscene – Advanced Data Generator
Upscene – Advanced Data Generator udmærker sig ved at skabe realistiske, skemabaserede testdatasæt til databaser. Jeg var især imponeret over, hvor intuitiv brugerfladen føltes, når jeg designede datamodeller og håndhævede begrænsninger på tværs af relaterede tabeller. Inden for få minutter kunne jeg producere randomiserede datasæt, der føltes autentiske nok til at validere forespørgselsydelse og stressteste min database.
Da jeg arbejdede på et projekt, der krævede stresstest før implementering, hjalp Upscene mig generere parameteriserede datasæt skræddersyet til specifikke scenarier uden manuel indsats. Dens understøttelse af flere datatyper og makroer sikrede, at jeg havde fuld fleksibilitet i at opbygge pipelines til oprettelse af syntetiske data, hvilket i sidste ende forbedrede testdækningen og automatiserede valideringsprocesser.
Funktioner:
- HiDPI-bevidst grænseflade: Denne opdatering forbedrer tilgængeligheden med store værktøjslinjeikoner, skalerede skrifttyper og skarpere grafik, hvilket gør det meget nemmere at bruge på moderne skærme med høj opløsning. Du vil bemærke, at selv lange testsessioner føles mere jævne på grund af reduceret belastning, når du navigerer i datasæt.
- Udvidede databiblioteker: Den inkluderer nu franske, tyske og italienske navne, gader og bydata, hvilket udvider dine muligheder for at simulere globale brugerscenarier. Dette er især værdifuldt, hvis din software har brug for compliance-venlige datasæt til flersprogede markeder. Jeg brugte disse biblioteker til at validere formularvalideringer i en tværregional HR-app, og det føltes ubesværet.
- Avanceret datagenereringslogik: Du kan nu generere værdier på tværs af flere passager, anvende makroer til at skabe komplekse outputog opbygge numeriske data, der refererer til tidligere poster. Mens jeg testede denne funktion, fandt jeg den fremragende til simulering af statistiske datasæt i performancetestscenarier, især når man bygger trendbaserede simuleringer.
- Automatiske sikkerhedskopier: Alle projekter drager nu fordel af automatisk backup-funktionalitet, som sikrer, at du aldrig mister dine konfigurationer eller testdatascripts. Det er en lille tilføjelse, men jeg gendannede engang en overskrevet skemaopsætning på få minutter takket være denne sikkerhedsforanstaltning – det sparede timevis af omarbejde.
- Generer fornuftige data: Denne funktion hjælper dig med at oprette realistiske testdata, der er klar til præsentation, og som undgår tilfældigt volapyk, der ofte bruges under test. Den inkluderer omfattende databiblioteker og flersproget understøttelse, så du kan generere navne, adresser og andre felter på forskellige sprog. Jeg fandt dette især nyttigt, når jeg forberedte demomiljøer til klienter, der krævede lokaliserede datasæt.
- Komplekse data med flere tabeller: Denne funktion giver dig mulighed for at generere testdata på tværs af flere indbyrdes relaterede tabeller, hvilket sparer dig meget tid ved validering af relationelle databaser. Den sikrer konsistens i sammenkædede poster, hvilket gør regressionstest og skemavalidering mere pålidelig. Jeg så også, hvor problemfrit den bevarede relationer mellem fremmednøgler og eliminerede risikoen for poster, der ikke matchede.
FORDELE
ULEMPER
Pris:
Her er nogle af de planer, der tilbydes af Upscene:
| Avancerede data Generator for adgang | Avancerede data Generator forum MySQL | Avancerede data Generator til Firebird |
|---|---|---|
| €119 | €119 | €119 |
Gratis prøveversion: Du kan downloade en gratis version
Forbindelse: https://www.upscene.com/advanced_data_generator/
7) Mockaroo
Mockaroo er et kraftfuldt og fleksibelt værktøj til generering af testdata, der hurtigt blev en af mine favoritter. Jeg satte pris på, hvor nemt det var at producere tusindvis af rækker i formater som JSON, CSV, Excel eller SQL, perfekt tilpasset mine behov for generering af testdata. Det brede sæt af databiblioteker lod mig konfigurere skemabaseret generering med præcis kontrol over felter som adresser, telefonnumre og geokoordinater.
I ét tilfælde brugte jeg det til at oprette en database med randomiserede datasæt til API-testning, hvilket hjalp med at afdække edge cases, jeg ikke havde forudset. Ved at give mig mulighed for at designe mock API'er og definere brugerdefinerede svar, gjorde Mockaroo det problemfrit at simulere virkelige scenarier, samtidig med at jeg bevarede kontrollen over variabilitet og fejlforhold.
Funktioner:
- Hånende biblioteker: Den leveres med omfattende biblioteker, der understøtter flere programmeringssprog og platforme. Dette gør integration i CI/CD-pipelines eller automatiseringsframeworks næsten ubesværet. Jeg foreslår at udforske de API-drevne muligheder her, fordi de giver dig mulighed for at bygge parametriserede datasæt, der kan genbruges i forskellige regressionstestcyklusser. Denne fleksibilitet kan spare dig for timers gentagen opsætning.
- Tilfældige testdata: Du kan generere tilfældige datasæt øjeblikkeligt i CSV-, SQL-, JSON- eller Excel-formaterJeg brugte dette under et performancetestprojekt, og det reducerede den manuelle indsats betydeligt, samtidig med at dataene forblev diversificerede. Mens jeg brugte denne funktion, bemærkede jeg, at justering af randomiseringsindstillinger for edge cases - som usædvanligt lange strenge - hjælper med at afsløre skjulte fejl tidligt.
- Brugerdefineret skemadesign: Denne funktion giver dig mulighed for at oprette skemabaserede genereringsregler, så dataene afspejler dine faktiske produktionsstrukturer. Det er især nyttigt til databaseseeding i agile sprints. Jeg husker, at jeg byggede et skema til et sundhedsprojekt, og det gjorde valideringer mere kompatible med følsomme datamodeller uden at eksponere rigtige poster.
- API-simulering: Du kan hurtigt designe mock API'er, definere URL'er, svar og fejltilstande. Dette er en livredder for teams, der venter på backend-tjenester, da det holder frontend-udviklingen glidende. Jeg vil anbefale at versionere dine mock-endpoints logisk – især når flere udviklere tester samtidigt – for at undgå konflikter og forvirring.
- Skalerbarhed og volumen: Mockaroo understøtter generering store datamængder til storskala testningJeg brugte det én gang til at simulere over en million rækker til en finansiel regressionstest, og det opretholdt både hastighed og pålidelighed. Det er automatiseringsklar, hvilket betyder, at du kan integrere det i kontinuerlige integrationsflows og skalere med udviklende projektkrav.
- Indstillinger for dataeksport: Værktøjet tillader eksport i flere formater, hvilket sikrer kompatibilitet på tværs af systemer og testframeworks. Du vil bemærke, hvor praktisk dette bliver, når du skifter mellem SQL-baserede tests og Excel-drevne testcases. Værktøjet giver dig mulighed for at håndtere scenarier på tværs af platforme problemfrit, hvilket er især værdifuldt i QA-miljøer på virksomhedsniveau.
FORDELE
ULEMPER
Pris:
Her er Mockaroos årsplaner:
| Sølv | Guld | Enterprise |
|---|---|---|
| $60 | $500 | $7500 |
Gratis prøveversion: Du får en gratis plan med 1000 rækker pr. fil
Forbindelse: https://mockaroo.com/
8) GenerateData
GenerateData er en open source testdatagenerator bygget med PHP, MySQLog JavaScript, der gør det nemt at producere store mængder realistiske, skemabaserede datasæt til test. Jeg fandt det særligt nyttigt, da jeg havde brug for hurtig oprettelse af syntetiske data på tværs af flere formater, fra CSV til SQL, uden at gå på kompromis med struktur eller integritet. Dets udvidelsesmuligheder gennem brugerdefinerede datatyper giver udviklere mulighed for at skræddersy datasæt præcist til projektets krav.
Da jeg brugte den til at oprette en database til automatiserede testcases, sparede fleksibiliteten til at definere regeldrevet generering og tilføje sammenkoblede plugins til postnumre og regioner timer med manuel opsætning. Med dens enkle brugerflade og GNU-licenserede framework, GenerateData viste sig at være en pålidelig ledsager til randomiserede datasæt og parameteriseret datagenerering under iterative testcyklusser.
Funktioner:
- Sammenkoblede data: Det giver dig mulighed for at generere lokationsspecifikke værdier såsom byer, regioner og postnumre, der er logisk knyttet sammen. Denne sammenkoblede tilgang sikrer repeterbarhed og realistiske relationer på tværs af datasæt. Jeg foreslår at bruge dette, når du tester compliance-venlige dataworkflows, da det afspejler produktionslignende forhold meget nøje.
- GNU-licensfleksibilitet: At være fuldt ud GNU-licenseret, dette værktøj giver frihed til tilpasning og distribution uden begrænsninger. Det er især nyttigt for teams, der ønsker en skalerbar løsning i virksomhedsklassen uden leverandørbinding. Jeg har integreret det i en CI/CD-pipeline, hvor automatiseringsklare værktøjer var afgørende, og det øgede produktiviteten betydeligt.
- Generering af datavolumen: Denne funktion giver dig mulighed for at producere store mængder datasæt på tværs af flere formater, f.eks. CSV, JSON eller SQLDu kan nemt seed-baser til regressionstest eller simulere API-test i stor skala. Ved at bruge det så jeg, at generering af store datasæt i batches kan reducere hukommelsesforbruget og forbedre effektiviteten.
- Plugin-understøttelse til udvidelse: GenerateData understøtter tilføjelse af plugins, så du kan udvide funktionaliteten med nye landedatasæt eller regeldrevne genereringsmuligheder. Det forbedrer fleksibiliteten og fremtidssikringen til unikke brugsscenarier. Et praktisk scenarie er at bygge testmiljøer, der kræver tilpasset dataanonymisering til globale teams.
- Eksport af flere formater: Du kan øjeblikkeligt generere testdata i mere end ti outputformater, herunder JSON, XML, SQL, CSV og endda kodestykker i Python, C# eller Ruby. Dette sikrer problemfri integration i forskellige DevOps-pipelines. Jeg vil anbefale at eksportere små batches først under opsætningen, så din skemavalidering kører problemfrit.
- Lagring og genbrug af datasæt: Der er også en mulighed, der giver dig mulighed for at gemme dine datasæt under en brugerkonto, hvilket gør det nemt at genbruge konfigurationer på tværs af flere projekter. Dette reducerer manuel indsats og sikrer reproducerbarhed. Jeg har brugt dette i kontinuerlige integrationsmiljøer for at holde testkørsler konsistente over tid.
FORDELE
ULEMPER
Pris:
Det er et open source-projekt
9) Delphix
Delphix er en kraftfuld platform til generering og styring af testdata, der leverer maskerede produktionsdata og sikre syntetiske datasæt for at accelerere udviklingen. Det, der skilte sig ud for mig, var dens evne til at virtualisere datamiljøer – hvilket gør det muligt at bogmærke, nulstille og dele versioner uden afbrydelser. Jeg fandt dette især effektivt, når jeg arbejdede på parallelle automatiserede testcases, hvor overholdelse af GDPR og CCPA var ikke til forhandling.
I ét scenarie brugte jeg Delphix at levere dataundersæt efter behov, hvilket sikrer hurtigere CI/CD-integration, samtidig med at følsomme oplysninger bevares gennem foruddefinerede maskeringsalgoritmer. Dens udvidelige API-understøttelse og problemfri synkronisering med forskellige testmiljøer gjorde den til en hjørnesten for pålidelig databaseseeding, parametriserede datasæt og kontinuerlig levering af pipelines.
Funktioner:
- Fejl ved deling af bogmærker: Denne funktion gør det nemt at dele snapshots af problematiske miljøer med udviklere, hvilket drastisk reducerer fejlfindingstiden. Jeg har brugt den under regressionstest, og den hjalp mit team med hurtigt at identificere tilbagevendende problemer. Jeg foreslår at navngive bogmærker logisk, så alle nemt kan spore fejl.
- Dataoverholdelse: Det sikrer, at følsomme oplysninger konsekvent anonymiseres på tværs af millioner af rækker, hvilket stemmer overens med GDPR, CCPA og andre regler. Mens jeg brugte det i et finansielt projekt, bemærkede jeg, hvor problemfri maskeringen føltes uden at bryde skemaforhold. Du vil bemærke, at compliance-rapportering bliver mere jævn, når den integreres i revisionsarbejdsgange.
- Udvidelig og åben: Delphix tilbyder fleksible muligheder med brugergrænseflade, CLI og API'er, hvilket giver teams mulighed for at administrere dataoperationer på tværs af forskellige opsætninger. Jeg fandt dens integration med CI/CD pipelines særligt effektiv til kontinuerlig testning. Denne funktion understøtter også forbindelser med flere overvågnings- og konfigurationsstyringsværktøjer, hvilket øger fleksibiliteten i DevOps-pipelines.
- Versionskontrol og nulstilling: Jeg kunne godt lide hvordan Delphix lader mig bogmærke og nulstille datasæt til enhver tidligere tilstand, hvilket forbedrer repeterbarheden under performancetest. Jeg brugte det, da jeg rullede tilbage til en ren baseline, før jeg kørte edge case coverage tests. Det sparer timers omarbejde og sikrer ensartede testscenarier.
- Data Synchronisering: Du kan holde testmiljøer løbende justeret med produktionslignende datasæt uden afbrydelser. Under et sundhedsprojekt så jeg, hvordan synkroniserede data reducerede uoverensstemmelser mellem mock-tjenester og det system, der blev testet. Denne konsistens forbedrer reproducerbarheden og opbygger tillid til testresultaterne.
- Brugerdefineret og foruddefineret maskering Algorithms: Den leveres med robuste maskeringsteknikker til at beskytte følsomme felter, samtidig med at brugervenligheden bevares. Jeg vil anbefale at eksperimentere med regeldrevet maskering i sandkassemiljøer, før den anvendes på produktionslignende data, da dette hjælper med at identificere eventuelle uregelmæssigheder tidligt. Balancen mellem sikkerhed og funktionalitet er et af dens stærkeste træk.
FORDELE
ULEMPER
Pris:
- Pris: Du kan kontakte salg for et tilbud.
- Gratis prøveversion: Brugere kan anmode om en demo
10) Original Software
Original Software bringer en omfattende tilgang til generering af testdata ved at understøtte både Test på databaseniveau og brugergrænsefladeniveauJeg værdsatte dets evne til at opretholde referentiel integritet, samtidig med at det oprettede delmængder af syntetiske testdata, hvilket sikrede, at randomiserede datasæt afspejlede virkelige forhold. Værktøjets evne til at integrere med andre testframeworks forbedrede den samlede kvalitet og reducerede redundans i mine arbejdsgange.
Mens jeg håndterede et scenarie, der involverede API-testning, stolede jeg på dens detaljerede sporing af indsættelser, opdateringer og sletninger for at validere mellemliggende tilstande under batchbehandling. Denne regeldrevne generering, kombineret med stærke obfuskationsmetoder til følsomme data, gav mig tillid til, at både sikkerhed og effektivitet blev opretholdt. Det er et stærkt valg for teams, der værdsætter fleksibel oprettelse af syntetiske data med automatiseret testcasevalidering.
Funktioner:
- Vertikal datamaskering: Denne funktion giver dig mulighed for at maskere følsomme data i produktions- eller testdatasæt, så du bevarer fortroligheden, samtidig med at du stadig har realistiske værdier. Den understøtter selektiv maskering efter kolonne eller felt ("lodret"), så kun de virkelig følsomme dele skjules. Jeg har brugt lignende værktøjer og fundet ud af, at det at have brugerdefinerede maskeringsregler (f.eks. bevare format, længde, type) sparer omarbejde.
- Gendannelse af kontrolpunkt: Dette værktøj giver dig mulighed for at tage snapshots af din database og rulle tilbage til dem, når det er nødvendigt, hvilket giver præcis kontrol under test. Det reducerer afhængigheden af databasebaserede databaser og gør regressionscyklusser reproducerbare. Jeg gendannede engang hele skemaer på få minutter efter mislykkede migreringstests, hvilket sparede betydelig nedetid.
- Datavalidering Operators: Denne funktion bringer over 20 operatører til kontroller som f.eks. tilstedeværelse, detektion af ændrede værdier, forventede vs. faktiske værdier og validering på tværs af filer. Det giver fleksibilitet til at teste korrekthed på tværs af komplekse scenarier. Under testen bemærkede jeg, at kombinationen af SUM- og EXISTS-valideringer sikrer, at relationel integritet bevares under opdateringer.
- Database- og applikationsvalidering under test: Med denne funktion kan du ikke kun validere testdata, men også databaseændringer udløst af applikationslogik, såsom triggere, opdateringer og sletninger. Den er yderst effektiv til regressionstestning og sikrer, at downstream-processer forbliver kompatible og pålidelige.
- Krav til sporbarhed og dækning: Denne funktion forbinder testcases direkte med krav og knytter testresultater tilbage til dem, hvilket fremhæver huller i dækningen. Den holder synligheden transparent på tværs af teams og er især værdifuld under audits.
- Manuel og automatiseret testudførelse med CI/CD-integration: Denne funktion gør det muligt at udføre tests manuelt eller automatisk, hvilket gør den tilpasningsdygtig til udforskende test eller regressionstest. Den integreres problemfrit med CI/CD-pipelines og logger udførelsesresultater og statusser.
FORDELE
ULEMPER
Pris:
- Pris: Du kan kontakte salg for et tilbud.
- Gratis prøveversion: Brugere kan anmode om en demo
Forbindelse: https://originalsoftware.com/products/testbench/
Sammenligningstabel
Her er en hurtig sammenligningstabel for ovenstående værktøjer:
| Feature | EMS Data Generator | Informatica TDM | dobbelt | Broadcom |
|---|---|---|---|---|
| Syntetisk datagenerering | ✔️ | ✔️ | ❌ | ✔️ |
| Datamaskering / Anonymisering | begrænset | ✔️ | ❌ | ✔️ |
| Dataunderinddeling / stikprøveudtagning | ✔️ | ✔️ | ❌ | ✔️ |
| Henvisende Integrity Bevarelse | ✔️ | ✔️ | ✔️ | ✔️ |
| CI/CD/Automatiseringsintegration | begrænset | ✔️ | ✔️ | ✔️ |
| Testdatabibliotek / Versionsstyring | begrænset | ✔️ | ✔️ | begrænset |
| Virtualisering / Tidsrejser | ✔️ | begrænset | ❌ | begrænset |
| Selvbetjening / Brugervenlighed | ✔️ | ✔️ | ✔️ | begrænset |
Hvad er testdata Generator?
A Test Data Generator er et værktøj eller software, der automatisk opretter store datasæt til testformål. Disse data bruges typisk til at teste softwareapplikationer, databaser eller systemer for at sikre, at de kan håndtere forskellige scenarier, såsom høj volumen, ydeevne eller stressforhold. Testdata kan være syntetiske eller baseret på virkelige data, afhængigt af testbehovene. Det hjælper med at simulere reelle brugerinteraktioner og edge cases, hvilket gør testprocessen mere effektiv, grundig og mindre tidskrævende.
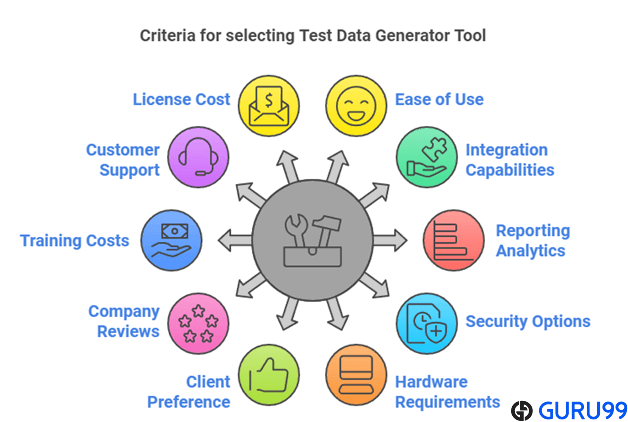
Hvordan udvalgte vi de bedste testdata Generator Værktøj?
Vi er en pålidelig kilde, fordi vi har investeret over 180 timer i at undersøge og sammenligne mere end 40 testdatageneratorværktøjer. Ud fra denne omfattende evaluering har vi omhyggeligt udvalgt de 12 mest effektive muligheder. Vores anmeldelse er baseret på direkte, praktisk erfaring, hvilket sikrer, at læserne får pålidelig, upartisk og praktisk indsigt til at træffe informerede valg.
- Brugervenlighed: Vores team prioriterede værktøjer med intuitive brugerflader, hvilket sikrede, at testere og udviklere hurtigt kunne generere data uden en stejl læringskurve.
- Ydeevnehastighed: Vi fokuserede på løsninger, der leverer hurtig datagenerering i stor skala, hvilket giver virksomheder mulighed for at teste store applikationer effektivt med minimal nedetid.
- Datadiversitet: Vores anmeldere valgte værktøjer, der understøtter en bred vifte af datatyper og formater, for at simulere realistiske testscenarier på tværs af flere miljøer.
- Integrationsevne: Vi evaluerede kompatibilitet med CI/CD-pipelines, databaser og automatiseringsframeworks, hvilket sikrede mere problemfri arbejdsgange for udviklings- og testteams.
- Tilpasningsmuligheder: Vores eksperter lagde vægt på værktøjer, der tilbyder fleksible regler og konfigurationer, så teams kan skræddersy testdata til at opfylde unikke forretningskrav.
- Sikkerhedsforanstaltninger: Vi overvejede værktøjer med stærk compliance-understøttelse, maskerings- og anonymiseringsfunktioner for at beskytte følsomme oplysninger under oprettelse af testdata.
- Skalerbarhed: Forskergruppen testede, om værktøjerne kunne håndtere både små projekter og behov på virksomhedsniveau uden at gå på kompromis med ydeevne eller stabilitet.
- Support på tværs af platforme: Vi inkluderede kun de værktøjer, der er verificeret til at køre problemfrit på tværs af flere operativsystemer, databaser og cloud-miljøer.
- Værdi for pengene: Vi analyserede omkostninger versus funktioner for at anbefale værktøjer, der leverer maksimale fordele uden unødvendige omkostninger for organisationer af varierende størrelser.
Sådan fejlfindes almindelige problemer med test Generator Værktøj?
Her er nogle af de almindelige problemer, som brugere står over for, når de bruger testgeneratorværktøjer, og jeg har givet de bedste måder at løse dem på under hvert problem:
- Problem: Mange værktøjer genererer ufuldstændige eller inkonsistente datasæt, hvilket forårsager testfejl i komplekse miljøer.
Opløsning: Konfigurer altid regler omhyggeligt, valider output i forhold til skemakrav, og sørg for, at relationel konsistens bevares på tværs af alle genererede datasæt. - Problem: Nogle værktøjer har svært ved effektivt at maskere følsomme oplysninger, hvilket fører til compliance-risici.
Opløsning: Aktivér indbyggede maskeringsalgoritmer, verificér gennem revisioner, og anvend anonymisering på feltniveau for at beskytte privatlivets fred i regulerede miljøer. - Problem: Begrænset integration med CI/CD-pipelines gør automatisering og kontinuerlig testning vanskeligere.
Opløsning: Vælg værktøjer med REST API'er eller plugins, konfigurer problemfri DevOps-integration, og planlæg automatiseret datalevering med hver byggecyklus. - Problem: Genererede data mangler ofte tilstrækkelig volumen til at efterligne ydeevnetest i den virkelige verden.
Opløsning: Konfigurer generering af store datasæt med samplingsmetoder, brug syntetisk dataudvidelse, og sørg for, at stresstest dækker spidsbelastningsscenarier. - Problem: Licensrestriktioner forhindrer flere brugere i at samarbejde effektivt om testdataprojekter.
Opløsning: Vælg virksomhedslicenser, implementer delte lagre, og tildel rollebaserede tilladelser for at give flere teams mulighed for at få adgang til og samarbejde problemfrit. - Problem: Nye brugere finder værktøjernes brugerflader forvirrende, hvilket øger indlæringskurven betydeligt.
Opløsning: Udnyt leverandørdokumentation, aktivér selvstudier i værktøjet, og tilbyd intern træning for at forkorte implementeringstiden og forbedre produktiviteten hurtigt. - Problem: Dårlig håndtering af ustrukturerede eller NoSQL-data resulterer i unøjagtige testmiljøer.
Opløsning: Vælg værktøjer, der understøtter JSON, XML og NoSQL; valider datastrukturtilknytninger; og kør skematests før implementering for at sikre nøjagtighed. - Problem: Nogle gratis eller freemium-abonnementer pålægger strenge række- eller formatbegrænsninger på genererede datasæt.
Opløsning: Upgrade til betalte niveauer, når skalerbarhed er påkrævet, eller kombiner flere gratis datasæt med scripts for effektivt at omgå begrænsninger.
Bedømmelse:
Jeg fandt alle ovenstående testdatageneratorværktøjer pålidelige og værd at overveje. Min evaluering involverede en omhyggelig analyse af deres funktioner, brugervenlighed og evne til at opfylde forskellige testkrav. Jeg fokuserede især på, hvor godt de håndterer komplekse databehov med konsistens og tilpasning. Efter en grundig gennemgang var der tre værktøjer, der skilte sig mest ud for mig.
- EMS Data GeneratorDette værktøj imponerede mig med sin balance mellem overkommelighed og brugervenlighed. Min evaluering viste, at det effektivt kan generere testdata til både små og store databaser, og jeg kunne godt lide, hvor brugervenligt det føltes.
- Informatica Test Data ManagementDet er en af de mest avancerede løsninger, jeg har arbejdet med til oprettelse af syntetiske data og robust beskyttelse. Jeg var imponeret over, hvor problemfrit det automatiserede dataidentifikation og maskering på tværs af komplekse databaser.
- dobbeltDet skiller sig ud som et praktisk valg for organisationer, der har brug for struktureret håndtering af testdata. Da jeg brugte det til at organisere store sæt af randomiserede datasæt på tværs af afdelinger, bemærkede jeg, hvor meget mere gnidningsfri testning blev.