Výuka hlubokého učení pro začátečníky: Základy neuronové sítě
Co je hluboké učení?
Hluboké učení je počítačový software, který napodobuje síť neuronů v mozku. Jedná se o podmnožinu strojového učení založeného na umělých neuronových sítích s učením reprezentace. Říká se tomu hluboké učení, protože využívá hluboké neuronové sítě. Toto učení může být pod dohledem, částečně pod dozorem nebo bez dozoru.
Algoritmy hlubokého učení jsou konstruovány s propojenými vrstvami.
- První vrstva se nazývá vstupní vrstva
- Poslední vrstva se nazývá výstupní vrstva
- Všechny vrstvy mezi nimi se nazývají skryté vrstvy. Slovo hluboký znamená, že síť spojuje neurony ve více než dvou vrstvách.
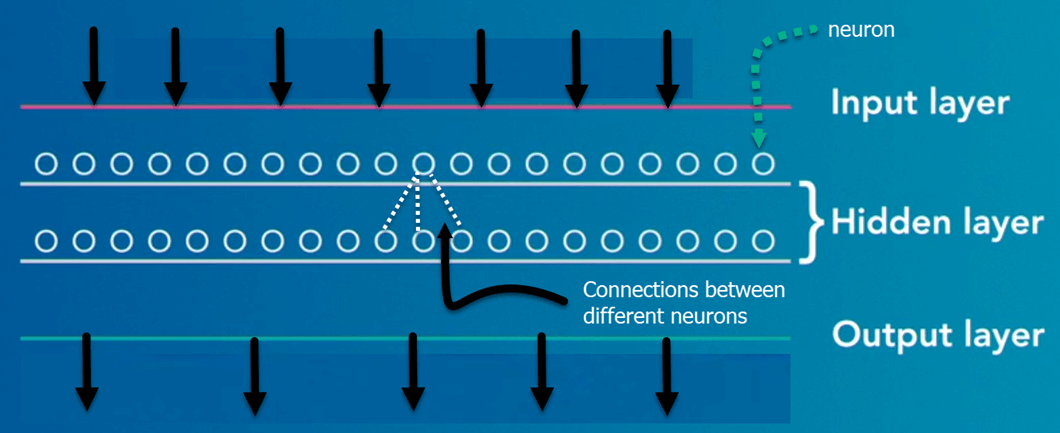
Každá skrytá vrstva se skládá z neuronů. Neurony jsou vzájemně propojeny. Neuron zpracuje a poté šíří vstupní signál, který obdrží, vrstvou nad ním. Síla signálu daného neuronu v další vrstvě závisí na váze, zkreslení a aktivační funkci.
Síť spotřebovává velké množství vstupních dat a provozuje je prostřednictvím více vrstev; síť se může naučit stále složitější vlastnosti dat na každé vrstvě.
Proces hlubokého učení
Hluboká neuronová síť poskytuje nejmodernější přesnost v mnoha úlohách, od detekce objektů až po rozpoznávání řeči. Mohou se učit automaticky, bez předem definovaných znalostí explicitně kódovaných programátory.

Abyste pochopili myšlenku hlubokého učení, představte si rodinu s dítětem a rodiči. Batole ukazuje předměty malíčkem a vždy říká slovo 'kočka'. Když se jeho rodiče zajímají o jeho vzdělání, neustále mu říkají: „Ano, to je kočka“ nebo „Ne, to není kočka“. Dítě setrvává v ukazování předmětů, ale s „kočkami“ se stává přesnějším. To malé dítě v hloubi duše neví, proč může říct, že je to kočka nebo ne. Právě se naučil, jak hierarchizovat složité rysy kočky tím, že se dívá na mazlíčka jako celek a nadále se soustředí na detaily, jako jsou ocasy nebo nos, aby se rozhodl.
Neuronová síť funguje úplně stejně. Každá vrstva představuje hlubší úroveň znalostí, tj. hierarchii znalostí. Neuronová síť se čtyřmi vrstvami se naučí složitější funkci než se dvěma vrstvami.
Učení probíhá ve dvou fázích:
První fáze: První fáze spočívá v aplikaci nelineární transformace vstupu a vytvoření statistického modelu jako výstupu.
Druhá fáze: Druhá fáze se zaměřuje na vylepšení modelu pomocí matematické metody známé jako derivace.
Neuronová síť opakuje tyto dvě fáze stovky až tisíckrát, dokud nedosáhne snesitelné úrovně přesnosti. Opakování této dvoufázové fáze se nazývá iterace.
Chcete-li uvést příklad hlubokého učení, podívejte se na pohyb níže, model se snaží naučit tančit. Po 10 minutách tréninku modelka neumí tančit a vypadá to jako klikyháky.

Po 48 hodinách učení počítač ovládá taneční umění.

Klasifikace neuronových sítí
Mělká neuronová síť: Mělká neuronová síť má pouze jednu skrytou vrstvu mezi vstupem a výstupem.
Hluboká neuronová síť: Hluboké neuronové sítě mají více než jednu vrstvu. Například model Google LeNet pro rozpoznávání obrázků čítá 22 vrstev.
V dnešní době se hluboké učení používá mnoha způsoby, jako je auto bez řidiče, mobilní telefon, vyhledávač Google, detekce podvodů, televize a tak dále.
Typy sítí hlubokého učení
Nyní v tomto tutoriálu Deep Neural Network se dozvíme o typech sítí Deep Learning:

Dopředné neuronové sítě
Nejjednodušší typ umělé neuronové sítě. S tímto typem architektury proudí informace pouze jedním směrem, dopředu. To znamená, že toky informací začínají na vstupní vrstvě, jdou do „skrytých“ vrstev a končí na výstupní vrstvě. Síť
nemá smyčku. Informace se zastaví na výstupních vrstvách.
Rekurentní neuronové sítě (RNN)
RNN je vícevrstvá neuronová síť, která může ukládat informace v kontextových uzlech, což jí umožňuje učit se datové sekvence a vydávat číslo nebo jinou sekvenci. Jednoduše řečeno, jedná se o umělé neuronové sítě, jejichž spojení mezi neurony zahrnují smyčky. RNN se dobře hodí pro zpracování sekvencí vstupů.

Pokud je například úkolem předpovědět další slovo ve větě „Chcete…………?
- Neurony RNN obdrží signál, který ukazuje na začátek věty.
- Síť přijme slovo „Do“ jako vstup a vytvoří vektor čísla. Tento vektor je přiváděn zpět do neuronu, aby poskytl paměť síti. Tato fáze pomáhá síti zapamatovat si, že přijala „Do“ a přijala jej na první pozici.
- Síť bude podobně pokračovat na další slova. Vyžaduje to slovo „vy“ a „chcete“. Stav neuronů se aktualizuje po obdržení každého slova.
- Poslední fáze nastává po obdržení slova „a“. Neuronová síť poskytne pravděpodobnost pro každé anglické slovo, které lze použít k dokončení věty. Dobře vyškolený RNN pravděpodobně přiřadí vysokou pravděpodobnost „kavárně“, „nápoji“, „burgeru“ atd.
Běžná použití RNN
- Pomozte obchodníkům s cennými papíry vytvářet analytické zprávy
- Odhalit abnormality ve smlouvě o účetní závěrce
- Odhalit podvodnou transakci kreditní kartou
- Poskytněte k obrázkům popisek
- Výkonní chatboti
- Standardní použití RNN nastává, když praktici pracují s daty nebo sekvencemi časových řad (např. audio nahrávky nebo text).
Konvoluční neuronové sítě (CNN)
CNN je vícevrstvá neuronová síť s jedinečnou architekturou navrženou tak, aby extrahovala stále složitější vlastnosti dat na každé vrstvě za účelem určení výstupu. CNN se dobře hodí pro percepční úkoly.

CNN se většinou používá, když existuje nestrukturovaná datová sada (např. obrázky) a praktici z ní potřebují extrahovat informace.
Pokud je například úkolem předpovědět popisek obrázku:
- CNN obdrží obrázek řekněme kočky, tento obrázek, v počítačovém pojetí, je souborem pixelu. Obecně jedna vrstva pro obrázek ve stupních šedi a tři vrstvy pro barevný obrázek.
- Během učení vlastností (tj. skrytých vrstev) síť identifikuje jedinečné rysy, například ocas kočky, ucho atd.
- Když se síť důkladně naučila, jak rozpoznat obrázek, může poskytnout pravděpodobnost pro každý obrázek, který zná. Označení s nejvyšší pravděpodobností se stane predikcí sítě.
Posílení učení
Posílení učení je podpolí strojového učení, ve kterém jsou systémy trénovány přijímáním virtuálních „odměn“ nebo „trestů“, v podstatě se učí metodou pokusu a omylu. DeepMind společnosti Google využil učení posilování k poražení lidského šampióna ve hrách Go. Posílení učení se také používá ve videohrách ke zlepšení herního zážitku poskytováním chytřejších robotů.
Jedním z nejznámějších algoritmů jsou:
- Q-učení
- Deep Q síť
- State-Action-Reward-State-Action (SARSA)
- Deep Deterministic Policy Gradient (DDPG)
Příklady aplikací hlubokého učení
Nyní v tomto tutoriálu Deep Learning pro začátečníky se pojďme dozvědět o aplikacích Deep Learning:
AI ve financích
Sektor finančních technologií již začal používat AI k úspoře času, snížení nákladů a přidané hodnoty. Hluboké učení mění odvětví půjček používáním robustnějšího kreditního hodnocení. Osoby s rozhodovací pravomocí v oblasti úvěrů mohou používat AI pro robustní aplikace pro poskytování úvěrů, aby dosáhli rychlejšího a přesnějšího posouzení rizik, a to pomocí strojové inteligence k zohlednění charakteru a kapacity žadatelů.
Underwrite je fintech společnost poskytující řešení AI pro společnosti vyrábějící úvěry. underwrite.ai používá AI ke zjištění, který žadatel s větší pravděpodobností splatí půjčku. Jejich přístup radikálně předčí tradiční metody.
AI v HR
Under Armour, společnost zabývající se sportovním oblečením, přináší revoluci do náboru a modernizuje zkušenosti kandidátů s pomocí AI. Under Armour ve skutečnosti zkracuje dobu náboru svých maloobchodních prodejen o 35 %. Under Armour čelil rostoucímu zájmu o popularitu již v roce 2012. Měli v průměru 30000 XNUMX životopisů měsíčně. Přečtení všech těchto žádostí a zahájení procesu prověřování a pohovoru trvalo příliš dlouho. Zdlouhavý proces najímání a přijímání lidí ovlivnil schopnost Under Armour mít své maloobchodní prodejny plně obsazené, nastartované a připravené k provozu.
V té době měl Under Armour všechny „nezbytné“ HR technologie na místě, jako jsou transakční řešení pro získávání zdrojů, aplikace, sledování a onboarding, ale tyto nástroje nebyly dostatečně užitečné. Vyberte si Under armour HireVue, poskytovatel umělé inteligence pro HR řešení pro pohovory na vyžádání i živé rozhovory. Výsledky byly blafování; podařilo se jim zkrátit dobu naplnění o 35 %. Na oplátku si najali kvalitnější štáby.
AI v marketingu
Umělá inteligence je cenným nástrojem pro správu zákaznických služeb a výzvy v oblasti personalizace. Vylepšené rozpoznávání řeči ve správě call-center a směrování hovorů v důsledku použití technik umělé inteligence umožňuje zákazníkům hladší zážitek.
Například hloubková analýza zvuku umožňuje systémům posoudit emocionální tón zákazníka. Pokud zákazník špatně reaguje na AI chatbot, systém může přesměrovat konverzaci na skutečné lidské operátory, kteří problém převezmou.
Kromě tří výše uvedených příkladů hlubokého učení je umělá inteligence široce používána v jiných sektorech/odvětvích.
Proč je hluboké učení důležité?
Hluboké učení je mocný nástroj k tomu, aby se predikce stala použitelným výsledkem. Hluboké učení vyniká v objevování vzorů (učení bez dozoru) a předpovědi založené na znalostech. Big údaje je palivem pro hluboké učení. Když se obojí spojí, může organizace sklízet nebývalé výsledky z hlediska produktivity, prodeje, řízení a inovací.
Hluboké učení může překonat tradiční metodu. Například algoritmy hlubokého učení jsou o 41 % přesnější než algoritmus strojového učení v klasifikaci obrázků, o 27 % přesnější v rozpoznávání obličeje a o 25 % v rozpoznávání hlasu.
Omezení hlubokého učení
Nyní v tomto tutoriálu neuronové sítě se dozvíme o omezeních hlubokého učení:
Označování dat
Většina současných modelů umělé inteligence je trénována prostřednictvím „učení pod dohledem“. Znamená to, že lidé musí označovat a kategorizovat základní data, což může být rozsáhlá a náchylná k chybám. Například společnosti vyvíjející technologie pro samořídící auta najímají stovky lidí, aby ručně anotovali hodiny videí z prototypů vozidel, aby pomohli tyto systémy trénovat.
Získejte obrovské tréninkové datové sady
Ukázalo se, že jednoduché techniky hlubokého učení, jako je CNN, mohou v některých případech napodobovat znalosti odborníků z medicíny a dalších oborů. Současná vlna strojové učení, však vyžaduje trénovací datové sady, které jsou nejen označené, ale také dostatečně široké a univerzální.
Metody hlubokého učení vyžadovaly tisíce pozorování, aby se modely staly relativně dobrými v klasifikačních úkolech, a v některých případech miliony pozorování, aby mohly fungovat na úrovni lidí. Není překvapením, že hluboké učení je známé v obřích technologických společnostech; používají velká data k akumulaci petabajtů dat. Umožňuje jim vytvořit působivý a vysoce přesný model hlubokého učení.
Vysvětlete problém
Velké a složité modely může být těžké vysvětlit lidsky. Například proč bylo získáno konkrétní rozhodnutí. Jedním z důvodů je pomalé přijímání některých nástrojů umělé inteligence v oblastech aplikací, kde je interpretovatelnost užitečná nebo skutečně vyžadována.
Kromě toho, jak se aplikace AI rozšiřuje, regulační požadavky by také mohly vést k potřebě více vysvětlitelných modelů AI.
Shrnutí
Přehled hlubokého učení: Hluboké učení je nový stav techniky pro umělá inteligence. Architektura hlubokého učení se skládá ze vstupní vrstvy, skrytých vrstev a výstupní vrstvy. Slovo hluboký znamená, že existují více než dvě plně propojené vrstvy.
Existuje obrovské množství neuronových sítí, kde je každá architektura navržena tak, aby vykonávala daný úkol. Například CNN pracuje velmi dobře s obrázky, RNN poskytuje působivé výsledky s časovými řadami a analýzou textu.
Hluboké učení je nyní aktivní v různých oblastech, od financí po marketing, dodavatelský řetězec a marketing. Velké firmy jsou první, kdo používá hluboké učení, protože již mají velký soubor dat. Hluboké učení vyžaduje rozsáhlou trénovací datovou sadu.