Урок за Scikit-Learn: Как да инсталирате & примери за Scikit-Learn
Какво е Scikit-learn?
Научете се е с отворен код Python библиотека за машинно обучение. Той поддържа най-съвременни алгоритми като KNN, XGBoost, произволна гора и SVM. Той е изграден върху NumPy. Scikit-learn се използва широко в конкуренцията на Kaggle, както и в известни технологични компании. Помага при предварителна обработка, намаляване на размерността (избор на параметри), класификация, регресия, групиране и избор на модел.
Scikit-learn има най-добрата документация от всички библиотеки с отворен код. Той ви предоставя интерактивна диаграма на https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html.
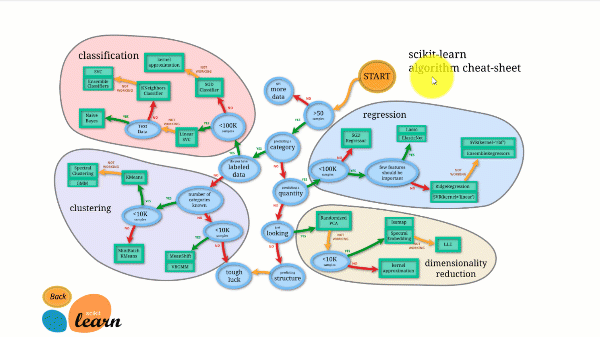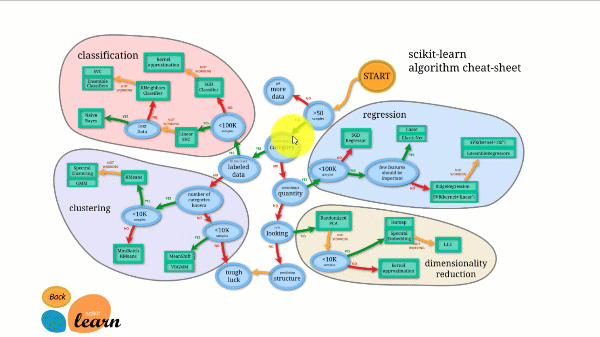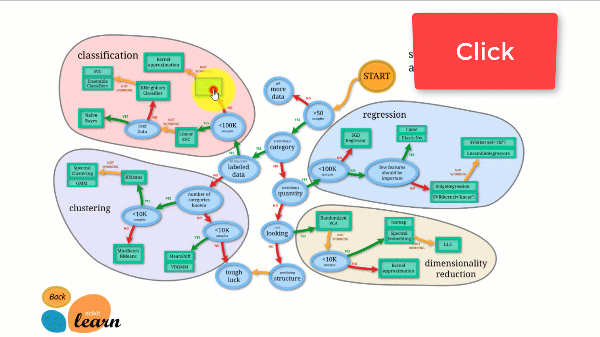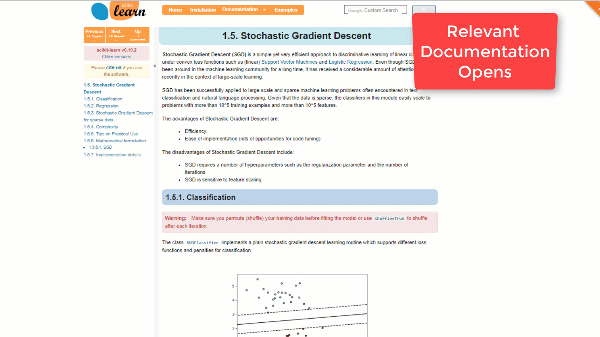
Scikit-learn не е много труден за използване и осигурява отлични резултати. Обаче scikit learn не поддържа паралелни изчисления. Възможно е да стартирате алгоритъм за дълбоко обучение с него, но това не е оптимално решение, особено ако знаете как да използвате TensorFlow.
Как да изтеглите и инсталирате Scikit-learn
Сега в това Python Урок за Scikit-learn, ще научим как да изтеглим и инсталираме Scikit-learn:
Вариант 1: AWS
scikit-learn може да се използва над AWS. моля вижте Докер изображението, което има предварително инсталиран scikit-learn.
За да използвате версията за разработчици, използвайте командата in Jupyter
import sys
!{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Вариант 2: Mac или Windows с помощта на Anaconda
За да научите за инсталацията на Anaconda, вижте https://www.guru99.com/download-install-tensorflow.html
Наскоро разработчиците на scikit пуснаха версия за разработка, която се занимава с често срещан проблем, с който се сблъсква текущата версия. Намерихме за по-удобно да използваме версията за разработчици вместо текущата версия.
Как да инсталирате scikit-learn с Conda Environment
Ако сте инсталирали scikit-learn със средата conda, моля, следвайте стъпката за актуализиране до версия 0.20
Стъпка 1) Активирайте среда tensorflow
source activate hello-tf
Стъпка 2) Премахнете scikit lean с помощта на командата conda
conda remove scikit-learn
Стъпка 3) Инсталирайте версията за разработчици.
Инсталирайте версията за разработчици на scikit learn заедно с необходимите библиотеки.
conda install -c anaconda git pip install Cython pip install h5py pip install git+git://github.com/scikit-learn/scikit-learn.git
ЗАБЕЛЕЖКА: Windows потребителят ще трябва да инсталира Microsoft зрителен C++ 14. Можете да го получите от тук
Пример за Scikit-Learn с машинно обучение
Този урок за Scikit е разделен на две части:
- Машинно обучение с scikit-learn
- Как да се доверите на вашия модел с LIME
Първата част подробно описва как да изградите тръбопровод, да създадете модел и да настроите хиперпараметрите, докато втората част предоставя най-съвременните по отношение на избора на модел.
Стъпка 1) Импортирайте данните
По време на този урок за обучение на Scikit ще използвате набора от данни за възрастни.
За предистория в този набор от данни вижте Ако се интересувате да научите повече за описателната статистика, моля, използвайте инструментите Dive и Overview.
Отнесете този урок научете повече за Dive и Overview
Вие импортирате набора от данни с Pandas. Обърнете внимание, че трябва да преобразувате типа на непрекъснатите променливи в плаващ формат.
Този набор от данни включва осем категорични променливи:
Категоричните променливи са изброени в CATE_FEATURES
- работен клас
- образование
- брачен
- окупация
- връзка
- раса
- секс
- родна_страна
освен това шест непрекъснати променливи:
Непрекъснатите променливи са изброени в CONTI_FEATURES
- възраст
- fnlwgt
- образование_номер
- капиталова_печалба
- капиталова_загуба
- часове_седмица
Имайте предвид, че попълваме списъка на ръка, за да имате по-добра представа какви колони използваме. По-бърз начин за изграждане на списък с категорични или непрекъснати е да използвате:
## List Categorical
CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns
print(CATE_FEATURES)
## List continuous
CONTI_FEATURES = df_train._get_numeric_data()
print(CONTI_FEATURES)
Ето кода за импортиране на данните:
# Import dataset
import pandas as pd
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
### Define continuous list
CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week']
### Define categorical list
CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
## Prepare the data
features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False)
df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64')
df_train.describe()
| възраст | fnlwgt | образование_номер | капиталова_печалба | капиталова_загуба | часове_седмица | |
|---|---|---|---|---|---|---|
| броя | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| означава | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| станд | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| мин | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| макс | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Можете да проверите броя на уникалните стойности на функциите native_country. Можете да видите, че само едно домакинство идва от Холандия-Холандия. Това домакинство няма да ни даде никаква информация, но ще го направи чрез грешка по време на обучението.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Можете да изключите този неинформативен ред от набора от данни
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
След това съхранявате позицията на непрекъснатите характеристики в списък. Ще ви трябва в следващата стъпка за изграждане на тръбопровода.
Кодът по-долу ще премине през всички имена на колони в CONTI_FEATURES и ще получи тяхното местоположение (т.е. неговия номер) и след това ще го добави към списък, наречен conti_features
## Get the column index of the categorical features
conti_features = []
for i in CONTI_FEATURES:
position = df_train.columns.get_loc(i)
conti_features.append(position)
print(conti_features)
[0, 2, 10, 4, 11, 12]
Кодът по-долу върши същата работа като по-горе, но за категориалната променлива. Кодът по-долу повтаря това, което сте правили преди, с изключение на категоричните функции.
## Get the column index of the categorical features
categorical_features = []
for i in CATE_FEATURES:
position = df_train.columns.get_loc(i)
categorical_features.append(position)
print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Можете да разгледате набора от данни. Имайте предвид, че всяка категорична характеристика е низ. Не можете да захранвате модел със стойност на низ. Трябва да трансформирате набора от данни с помощта на фиктивна променлива.
df_train.head(5)
Всъщност трябва да създадете една колона за всяка група във функцията. Първо, можете да изпълните кода по-долу, за да изчислите общия брой необходими колони.
print(df_train[CATE_FEATURES].nunique(),
'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9 education 16 marital 7 occupation 15 relationship 6 race 5 sex 2 native_country 41 dtype: int64 There are 101 groups in the whole dataset
Целият набор от данни съдържа 101 групи, както е показано по-горе. Например характеристиките на работната класа имат девет групи. Можете да визуализирате имената на групите със следните кодове
unique() връща уникалните стойности на категориалните характеристики.
for i in CATE_FEATURES:
print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Следователно наборът от данни за обучение ще съдържа 101 + 7 колони. Последните седем колони са непрекъснатите характеристики.
Scikit-learn може да се погрижи за конвертирането. Извършва се в две стъпки:
- Първо, трябва да конвертирате низа в ID. Например State-gov ще има ID 1, Self-emp-not-inc ID 2 и т.н. Функцията LabelEncoder прави това вместо вас
- Транспонирайте всеки идентификатор в нова колона. Както бе споменато по-горе, наборът от данни има 101 идентификатор на група. Следователно ще има 101 колони, обхващащи групите на всички категорични характеристики. Scikit-learn има функция, наречена OneHotEncoder, която извършва тази операция
Стъпка 2) Създайте комплекта за обучение/тест
Сега, когато наборът от данни е готов, можем да го разделим 80/20.
80 процента за комплекта за обучение и 20 процента за комплекта за тестване.
Можете да използвате train_test_split. Първият аргумент е рамката с данни е характеристиките, а вторият аргумент е рамката с данни на етикета. Можете да посочите размера на тестовия набор с test_size.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_train[features],
df_train.label,
test_size = 0.2,
random_state=0)
X_train.head(5)
print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Стъпка 3) Изградете тръбопровода
Конвейерът улеснява захранването на модела с последователни данни.
Идеята зад нея е да поставите необработените данни в „тръбопровод“, за да извършвате операции.
Например, с текущия набор от данни трябва да стандартизирате непрекъснатите променливи и да конвертирате категоричните данни. Имайте предвид, че можете да извършвате всяка операция вътре в конвейера. Например, ако имате „NA“ в набора от данни, можете да ги замените със средна стойност или медиана. Можете също да създавате нови променливи.
Вие имате избор; кодирайте твърдо двата процеса или създайте конвейер. Първият избор може да доведе до изтичане на данни и да създаде несъответствия с течение на времето. По-добрият вариант е да използвате тръбопровода.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Тръбопроводът ще извърши две операции, преди да захрани логистичния класификатор:
- Стандартизирайте променливата: `StandardScaler()“
- Преобразувайте категоричните характеристики: OneHotEncoder(sparse=False)
Можете да изпълните двете стъпки с помощта на make_column_transformer. Тази функция не е налична в текущата версия на scikit-learn (0.19). Не е възможно с текущата версия да се изпълни енкодерът на етикети и един горещ енкодер в конвейера. Това е една от причините да решим да използваме версията за разработчици.
make_column_transformer е лесен за използване. Трябва да дефинирате кои колони да приложите трансформацията и каква трансформация да оперирате. Например, за да стандартизирате непрекъснатата функция, можете да направите:
- conti_features, StandardScaler() в make_column_transformer.
- conti_features: списък с непрекъснатата променлива
- StandardScaler: стандартизира променливата
Обектът OneHotEncoder вътре в make_column_transformer автоматично кодира етикета.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Можете да тествате дали тръбопроводът работи с fit_transform. Наборът от данни трябва да има следната форма: 26048, 107
preprocess.fit_transform(X_train).shape
(26048, 107)
Трансформаторът на данни е готов за употреба. Можете да създадете тръбопровода с make_pipeline. След като данните се трансформират, можете да подадете логистичната регресия.
model = make_pipeline(
preprocess,
LogisticRegression())
Обучението на модел със scikit-learn е тривиално. Трябва да използвате напасването на обекта, предшествано от тръбопровода, т.е. модел. Можете да отпечатате точността с резултатния обект от библиотеката scikit-learn
model.fit(X_train, y_train)
print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
И накрая, можете да предвидите класовете с predict_proba. Връща вероятността за всеки клас. Обърнете внимание, че сумата е една.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Стъпка 4) Използване на нашия конвейер при търсене в мрежа
Настройването на хиперпараметъра (променливи, които определят мрежовата структура като скрити единици) може да бъде досадно и изтощително.
Един от начините за оценка на модела може да бъде промяна на размера на набора за обучение и оценка на представянето.
Можете да повторите този метод десет пъти, за да видите показателите за резултата. Това обаче е твърде много работа.
Вместо това scikit-learn предоставя функция за извършване на настройка на параметри и кръстосано валидиране.
Кръстосана проверка
Кръстосаното валидиране означава, че по време на обучението комплектът за обучение се приплъзва n пъти на гънки и след това оценява модела n пъти. Например, ако cv е зададено на 10, наборът за обучение се обучава и оценява десет пъти. Във всеки кръг класификаторът избира произволно девет сгъвания, за да обучи модела, а 10-тото сгъване е предназначено за оценка.
Търсене в мрежата
Всеки класификатор има хиперпараметри за настройка. Можете да опитате различни стойности или да зададете мрежа с параметри. Ако отидете на официалния уебсайт на scikit-learn, можете да видите, че логистичният класификатор има различни параметри за настройка. За да направите обучението по-бързо, избирате да настроите параметъра C. Той контролира параметъра за регулиране. Трябва да е положително. Малка стойност придава по-голяма тежест на регулатора.
Можете да използвате обекта GridSearchCV. Трябва да създадете речник, съдържащ хиперпараметрите за настройка.
Изброявате хиперпараметрите, последвани от стойностите, които искате да опитате. Например, за да настроите параметъра C, използвате:
- 'logisticregression__C': [0.1, 1.0, 1.0]: Параметърът се предшества от името, с малки букви, на класификатора и две долни черти.
Моделът ще изпробва четири различни стойности: 0.001, 0.01, 0.1 и 1.
Обучавате модела, като използвате 10 сгъвания: cv=10
from sklearn.model_selection import GridSearchCV
# Construct the parameter grid
param_grid = {
'logisticregression__C': [0.001, 0.01,0.1, 1.0],
}
Можете да обучите модела с помощта на GridSearchCV с параметъра gri и cv.
# Train the model
grid_clf = GridSearchCV(model,
param_grid,
cv=10,
iid=False)
grid_clf.fit(X_train, y_train)
OUTPUT
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))]),
fit_params=None, iid=False, n_jobs=1,
param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
За достъп до най-добрите параметри, използвайте best_params_
grid_clf.best_params_
OUTPUT
{'logisticregression__C': 1.0}
След обучение на модела с четири различни стойности на регулация, оптималният параметър е
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
най-добра логистична регресия от търсене в мрежата: 0.850891
За достъп до прогнозираните вероятности:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
Модел XGBoost с scikit-learn
Нека опитаме Scikit-learn примери, за да обучим един от най-добрите класификатори на пазара. XGBoost е подобрение спрямо произволната гора. Теоретичната основа на класификатора е извън обхвата на това Python Урок за Scikit. Имайте предвид, че XGBoost спечели много състезания по kaggle. Със среден размер на набора от данни, той може да работи толкова добре, колкото алгоритъм за дълбоко обучение или дори по-добре.
Класификаторът е предизвикателство за обучение, защото има голям брой параметри за настройка. Можете, разбира се, да използвате GridSearchCV, за да изберете параметъра вместо вас.
Вместо това, нека да видим как да използваме по-добър начин за намиране на оптималните параметри. GridSearchCV може да бъде досаден и много дълъг за обучение, ако предавате много стойности. Пространството за търсене расте заедно с броя на параметрите. Предпочитано решение е да използвате RandomizedSearchCV. Този метод се състои в избиране на произволни стойности на всеки хиперпараметър след всяка итерация. Например, ако класификаторът е обучен за 1000 итерации, тогава се оценяват 1000 комбинации. Работи горе-долу като. GridSearchCV
Трябва да импортирате xgboost. Ако библиотеката не е инсталирана, моля, използвайте pip3 install xgboost или
use import sys
!{sys.executable} -m pip install xgboost
In Jupyter заобикаляща среда
След
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Следващата стъпка в този Scikit Python урокът включва определяне на параметрите за настройка. Можете да се обърнете към официалната документация, за да видите всички параметри за настройка. В името на Python Урок за Sklearn, вие избирате само два хиперпараметъра с по две стойности. XGBoost отнема много време за обучение, колкото повече хиперпараметри в мрежата, толкова по-дълго време трябва да чакате.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Създавате нов тръбопровод с XGBoost класификатор. Вие избирате да дефинирате 600 оценителя. Имайте предвид, че n_estimators са параметър, който можете да настройвате. Високата стойност може да доведе до прекомерно оборудване. Можете да опитате сами различни стойности, но имайте предвид, че това може да отнеме часове. Използвате стойността по подразбиране за другите параметри
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Можете да подобрите кръстосаното валидиране с кръстосания валидатор Stratified K-Folds. Тук създавате само три гънки, за да ускорите изчислението, но понижавате качеството. Увеличете тази стойност до 5 или 10 у дома, за да подобрите резултатите.
Вие избирате да обучите модела през четири повторения.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Рандомизираното търсене е готово за използване, можете да обучите модела
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False) random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min [Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Както можете да видите, XGBoost има по-добър резултат от предишната logisitc регресия.
print("Best parameter", random_search.best_params_)
print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Създайте DNN с MLPClassifier в scikit-learn
И накрая, можете да тренирате алгоритъм за дълбоко обучение със scikit-learn. Методът е същият като при другия класификатор. Класификаторът е наличен в MLPClassifier.
from sklearn.neural_network import MLPClassifier
Вие дефинирате следния алгоритъм за дълбоко обучение:
- Решател на Адам
- Функция за активиране на Relu
- Алфа = 0.0001
- размер на партидата 150
- Два скрити слоя съответно със 100 и 50 неврона
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Можете да промените броя на слоевете, за да подобрите модела
model_dnn.fit(X_train, y_train)
print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN регресионен резултат: 0.821253
LIME: Доверете се на своя модел
Сега, когато имате добър модел, имате нужда от инструмент, за да му се доверите. машина обучение Алгоритъмът, особено случайната гора и невронната мрежа, са известни като алгоритъм на черна кутия. Кажете по друг начин, работи, но никой не знае защо.
Трима изследователи са измислили страхотен инструмент, за да видят как компютърът прави прогноза. Документът се казва Защо трябва да ви вярвам?
Те разработиха алгоритъм на име Локални интерпретируеми модели-агностични обяснения (LIME).
Вземете пример:
понякога не знаете дали можете да се доверите на прогноза от машинно обучение:
Един лекар, например, не може да се довери на диагноза само защото компютърът го е казал. Също така трябва да знаете дали можете да се доверите на модела, преди да го пуснете в производство.
Представете си, че можем да разберем защо всеки класификатор прави прогноза дори за невероятно сложни модели като невронни мрежи, произволни гори или svms с всяко ядро
ще стане по-достъпно за доверие в прогноза, ако можем да разберем причините зад нея. От примера с лекаря, ако моделът му каже кои симптоми са съществени, ще му се доверите, също така е по-лесно да разберете дали не трябва да се доверявате на модела.
Lime може да ви каже какви функции влияят на решенията на класификатора
Подготовка на данните
Това са няколко неща, които трябва да промените, за да работите с LIME питон. На първо място, трябва да инсталирате вар в терминала. Можете да използвате pip install lime
Lime използва обект LimeTabularExplainer, за да приближи модела локално. Този обект изисква:
- набор от данни във формат numpy
- Името на функциите: имена_на_функции
- Името на класовете: class_names
- Индексът на колоната на категорийните признаци: категорични_характеристики
- Името на групата за всяка категорична характеристика: categorical_names
Създайте набор от влакове numpy
Можете да копирате и конвертирате df_train от pandas в буца много лесно
df_train.head(5) # Create numpy data df_lime = df_train df_lime.head(3)
Вземете името на класа Етикетът е достъпен с обекта unique(). Трябва да видите:
- „<=50K“
- '>50K'
# Get the class name class_names = df_lime.label.unique() class_names
array(['<=50K', '>50K'], dtype=object)
индекс на колоната на категориалните характеристики
Можете да използвате метода, който сте използвали преди, за да получите името на групата. Вие кодирате етикета с LabelEncoder. Повтаряте операцията върху всички категорични характеристики.
##
import sklearn.preprocessing as preprocessing
categorical_names = {}
for feature in CATE_FEATURES:
le = preprocessing.LabelEncoder()
le.fit(df_lime[feature])
df_lime[feature] = le.transform(df_lime[feature])
categorical_names[feature] = le.classes_
print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Сега, когато наборът от данни е готов, можете да конструирате различния набор от данни, както е показано в примерите за обучение на Scikit по-долу. Вие всъщност трансформирате данните извън тръбопровода, за да избегнете грешки с LIME. Наборът за обучение в LimeTabularExplainer трябва да бъде numpy масив без низ. С метода по-горе имате вече конвертиран набор от данни за обучение.
from sklearn.model_selection import train_test_split
X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features],
df_lime.label,
test_size = 0.2,
random_state=0)
X_train_lime.head(5)
Можете да направите тръбопровода с оптимални параметри от XGBoost
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))])
Получаваш предупреждение. Предупреждението обяснява, че не е необходимо да създавате енкодер на етикети преди конвейера. Ако не искате да използвате LIME, можете да използвате метода от първата част на урока за машинно обучение със Scikit-learn. В противен случай можете да продължите с този метод, първо да създадете кодиран набор от данни, да зададете получаване на горещия енкодер в конвейера.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Преди да използваме LIME в действие, нека създадем numpy масив с характеристиките на грешната класификация. Можете да използвате този списък по-късно, за да получите представа какво е подвело класификатора.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1)
temp['predicted'] = model_xgb.predict(X_test_lime)
temp['wrong']= temp['label'] != temp['predicted']
temp = temp.query('wrong==True').drop('wrong', axis=1)
temp= temp.sort_values(by=['label'])
temp.shape
(826, 16)
Създавате ламбда функция, за да извлечете прогнозата от модела с новите данни. Скоро ще ви трябва.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float) X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Преобразувате рамката от данни на pandas в масив numpy
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
import lime
import lime.lime_tabular
### Train should be label encoded not one hot encoded
explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime ,
feature_names = features,
class_names=class_names,
categorical_features=categorical_features,
categorical_names=categorical_names,
kernel_width=3)
Нека изберем произволно домакинство от набора от тестове и да видим прогнозата на модела и как компютърът е направил своя избор.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Можете да използвате обяснителя с expand_instance, за да проверите обяснението зад модела
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)
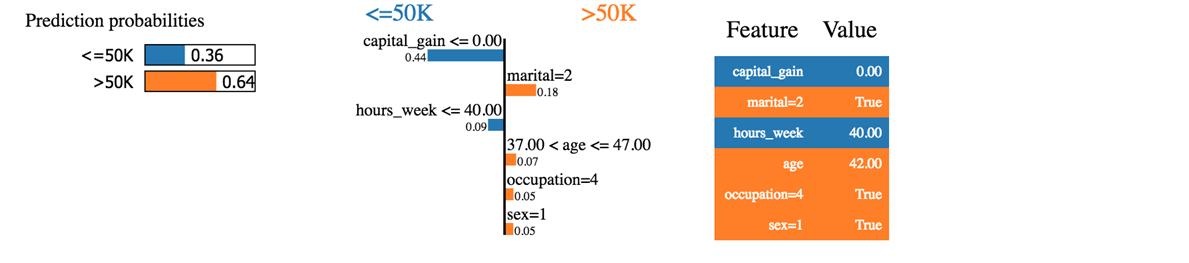
Виждаме, че класификаторът е предвидил правилно домакинството. Доходите наистина са над 50 хиляди.
Първото нещо, което можем да кажем е, че класификаторът не е толкова сигурен относно прогнозираните вероятности. Машината прогнозира, че домакинството има доход над 50 хиляди с вероятност от 64%. Тези 64% се състоят от капиталова печалба и брак. Синият цвят допринася отрицателно за положителния клас, а оранжевата линия - положително.
Класификаторът е объркан, тъй като капиталовата печалба на това домакинство е нула, докато капиталовата печалба обикновено е добър показател за богатство. Освен това домакинството работи по-малко от 40 часа седмично. Възрастта, професията и полът допринасят положително за класификатора.
Ако семейното положение беше необвързано, класификаторът щеше да предвиди доход под 50k (0.64-0.18 = 0.46)
Можем да опитаме с друго домакинство, което е грешно класифицирано
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1
print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K predicted >50K Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)

Класификаторът прогнозира доход под 50k, докато не е вярно. Това домакинство изглежда странно. Няма нито капиталова печалба, нито капиталова загуба. Той е разведен и е на 60 години и е образован човек, т.е. образование_num > 12. Според общия модел това домакинство трябва, както е обяснено от класификатора, да получи доход под 50k.
Опитвате се да си играете с LIME. Ще забележите груби грешки от класификатора.
Можете да проверите GitHub на собственика на библиотеката. Те предоставят допълнителна документация за класификация на изображения и текст.
Oбобщение
По-долу е даден списък с някои полезни команди с scikit learn версия >=0.20
| създаване на набор от данни за влак/тест | стажантите се разделят |
| Изградете тръбопровод | |
| изберете колоната и приложете трансформацията | makecolumntransformer |
| тип трансформация | |
| стандартизирам | StandardScaler |
| мин макс | MinMaxScaler |
| нормализирам | Нормализатор |
| Приписване на липсваща стойност | вменявам |
| Преобразувайте категорично | OneHotEncoder |
| Нагласете и трансформирайте данните | fit_transform |
| Направи тръбопровода | make_pipeline |
| Основен модел | |
| логистична регресия | Логистична регресия |
| XGBoost | XGB Класификатор |
| Невронна мрежа | MLPClassifier |
| Търсене в мрежата | GridSearchCV |
| Случайно търсене | RandomizedSearchCV |