

こんにちは!PRESIDENT CARDでソフトウェアエンジニアをしているアダチ(@dikxs118)です。
PRESIDENT CARDではAI活用が非常に盛んで、ChatGPTやClaudeはもちろん、Gemini, GitHub Copilot, Devin, v0, Cursorなど... エンジニアは自分に合ったAIツールを選び、それぞれの開発スタイルで貪欲に最新のAIをキャッチアップして、爆速で開発を進めたり、マイクロサービスを量産したりしています。
ツールに関しても、会社が費用をサポートしてくれますし、セキュリティやリーガル的な文脈でも弊社では専門のリーガルチームとcorpITチームがいるので、エンジニアが主体で攻めつつ、守りも安心して利用することができます。
今回はそんな中で直近で私が担当した「Difyを使ったチャットボット構築」を題材に、実際にどのようにAI Agentを活用して開発を進めたかをご紹介します。 本記事では、「AIネイティブな開発フロー」に着目して書いていきます。
なお、DifyのワークフローやRAGの構築、デリバリ基盤といった技術的な詳細については、別記事にて詳しく解説しますので、そちらも合わせてご覧ください。
※本内容はアプリケーション作成時点の内容であり、AIの進化に合わせて日々スタイルは変化しています。
プロジェクト概要:1ヶ月でリリースまで完走する
まず、今回構築したシステムの概要は以下の図の通りです。
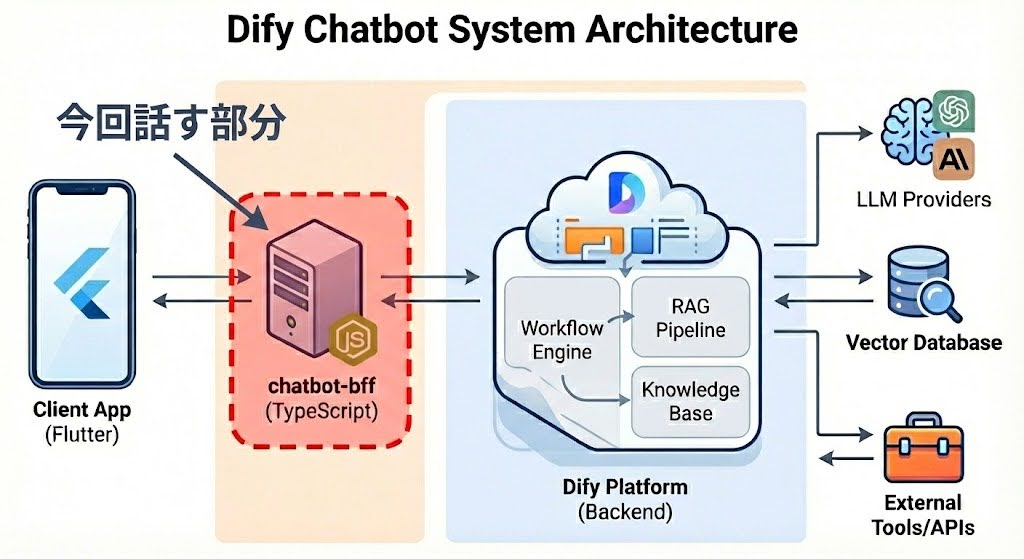
Chatbot-BFFが担っているのは、主にセキュリティと統制の役割です。
具体的には、以下の機能をBFF層で処理しています。
- RateLimit(アクセス制限)
- Difyへの個人情報送信を防ぐための検閲とデータのマスキング
- 認証
- 監査ログやアラート
なぜBFFが必要だったかというと、Difyは初期フェーズとしてSaaS版を利用しているためです。ユーザーの入力をそのまま信用して渡してしまうと、個人情報が漏洩するリスクがあります。そのため、BFFを挟んでフィルタリングを行う構成を採用しました。
今回の開発では、「ゼロの状態から1ヶ月でのリリース」という、非常にタイトなスケジュールが求められました。
しかし、実際の進行としては、アプリケーション実装が約1週間ほどで終わり、インフラ設定やデプロイ作業も同じチームのメンバーが迅速に進めてくれました。
そのため、テストやアプリケーションとのインターフェース調整を含め、実際には1ヶ月もかからずにGKE (Google Kubernetes Engine) 上で稼働させることができました。
Chatbot-BFF自体はそこまで複雑なアプリケーションではないので、アプリの詳細な仕様は割愛し、ここからは「開発ワークフロー」について解説していきます。
具体的な開発フロー:爆速PoCから堅牢なプロダクトへ
では、実際にどうやって1週間でアプリケーションを作り上げたのか。そして、どうやってそれを「本番で使える品質」まで引き上げたのかについて、
ここからは、私が当時実践した「マルチエージェント ✖️ ワークツリー」を駆使した開発フローを、3つのフェーズで具体的に解説します。
Phase 1: 要件定義をし、タスクを分割
まずは、Cursorを話しながら要件を定義しました。
要件を詰める際は、曖昧な要件やよくわからないけど出力されたアウトプットは徹底的に会話して、不要なら排除し、必要なら曖昧さがなくなるまで会話をします。
次に、仕様を決めて、タスクを分割していきます。基本的に 1タスク = 1PR になるので、タスクの粒度は小さいほうがいいです。逆に言えば、適切なPRのサイズになるまで、タスクを分解します。
また、タスクを作る際は、「実装計画」が一番大事だと感じています。 どのエージェントを使うかとか、どんなプロンプトを設定するかとかよりも、「タスクの境界を明確にし、膨大な情報は与えず、事前に実装計画を立てさせること」が本質なのかなと感じています。
なので、例えば、
User 👤: 「認証機能を追加して。」
ではなくて、
User 👤:「auth_controller.ts の Login メソッドを実装して。リクエストボディを LoginRequest 構造体にBindし、事前に定義した AuthUseCase.ts インターフェースを呼び出すだけにして。JWTの発行ロジックやDB検証はここでは書かず、UseCaseの戻り値をハンドリングすることに集中して」
のような情報を与えて、実装計画を細かく書いてもらい、これを見れば誰でも実装できるなというレベルまで一緒に計画してあげることが大切です。
タスクを細かく分割し、一つ一つのタスクに実装計画があり、そのタスクの順序を管理することができれば、Phase1は終了です。
Phase 2: vibe-kanbanでマルチエージェント並列実装
タスクが切れたら、実装フェーズです。 今回は、vibe-kanban というOSSを使いました。
これはKanban形式でタスクを管理しながらvibeコーディングを行うことができるワークツリーのラッパーです。
私の当時のやり方は、「タスクをDuplicate(複製)して、複数のエージェントに並列処理させる」というものです。 現在はCursorでも似たようなことができますが、当時は工夫が必要だったのと、Kanban形式の方が見やすいし外部に進捗も共有しやすいので、vibe-kanbanを利用しました。
実際のフローとしては、
- 分割したタスクをKanbanに投入し、同じタスクを複製する
- それぞれを異なるAgent(当時はCodex, Claude Code, Cursorなど)に割り当てて実行させる
- 上がってきたコードを見比べ、「A案はロジックが良い」「B案は可読性が高い」といった具合に良いものをピックアップしたり、お互いのコードをマージさせてブラッシュアップさせる
単一のAIに頼るとハマったりあまり信用できないこともありますが、マルチエージェントを使うことで、最適解に辿り着くスピードが格段に上がります。これである程度動くアプリケーション(PoC)が完成します。
Phase 3: 要件を逆輸入し、Kiroで再構築
Phase 2で作ったものは、あくまでスピード重視のPoCです。そのままプロダクトで長期運用するには、保守性や堅牢性の面で少し心許ありません。 なので実際にPoCして、動かしてみて、そのコードからさらに要件を逆輸入します。
というのも、作ってみて初めてわかる要件や改善点って結構あると思うんですよね。最初から完璧な要件を定義して設計できればいいですが、それを頑張るより「実際に雑に動かしてみて、そこから要件やドキュメントを逆輸入する」方がコスパがいいなと現段階では感じています。
最後はその要件をもとに Kiro で、より良いコードに書き換えました。DDDを導入し、テストもこの段階で入れました。
Q. 最初からKiroでPoCしないのはなぜ?
クレジットの問題もありますし、上述の通りしっかり会話して、マルチエージェントで作った方が、より詳細なドキュメントを逆輸入できる「質の高いPoC」ができるからですね。
Q. 逆に再構築にKiroを使うのはなぜ?
「AI-DLC(AI Development Life Cycle)という新たな開発手法に興味があったから(笑)」というのが本音ですが、後付けで理由をつけるなら、KiroにはDDDやTDDといった設計技術が統合されているので、今回再構築したいモチベーションを満たすのに適していると感じたからです。 別にKiroじゃなくてもいいんですが、このような新しいツールへの挑戦が認められるのもPRESIDENT CARDの良いところです!
「動くもの」がすでにある状態で、それを正解データとして「堅牢な設計」に書き直させる。 このプロセスを経ることで、「爆速で作ったプロトタイプ」を「堅牢で保守可能なプロダクトコード」へと生まれ変わらせ、最終的なリリースを行いました。
まとめ
今回の開発フローをまとめると、以下のようになります。
- Cursorで計画: AIが実行可能な粒度までタスクを徹底的に分割
- vibe-kanbanで実装: タスクを複製し、マルチエージェントで最良のコードを採用してPoCを作成
- Kiroで再構築: 仕様を逆輸入し、DDDやテストを含めたプロダクトコードへ昇華
AI Agentを適材適所で組み合わせることで、開発スピードと品質(堅牢性)を両立させることができました。
今回はPRESIDENT CARDにおける「AIネイティブな開発フロー」についてご紹介しましたが、 このシステムの中身であるDify製のチャットボットの技術詳細については、別記事にて解説しているので興味のある方はそちらもみてみてください!
We Are Hiring !!
株式会社UPSIDERでは現在積極採用をしています。 ぜひお気軽にご応募ください。
UPSIDER Engineering Deckはこちら📣