
Bayesian Additive Regression Trees (BART), proposed by Chipman et al. (2010) (Reference 1), is a Bayesian “sum-of-trees” model where we use the sum of trees to model or approximate the target function ![f(x) = \mathbb{E}[Y \mid x]](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+%5Cmathbb%7BE%7D%5BY+%5Cmid+x%5D&bg=ffffff&fg=333333&s=0&c=20201002)



As a Bayesian method, all we have to do is to specify the prior distribution for the parameters and the likelihood. From there, we can turn the proverbial Bayesian crank to get the posterior distribution of parameters and with it, posterior inference of any quantity we are interested in (e.g. point and estimate estimates of
Likelihood
The likelihood is easy to specify once we get definitions out of the way. Let 





For a given 
The likelihood for BART is

The response is the sum of 
Prior specification: General comments
We need to choose priors for 

Chipman et al. actually decided not to put a prior on 
As for the other parameters, we introduce independence assumptions to simplify the prior specification. If 

![\begin{aligned} p \left( (T_1, M_1), \dots, (T_m, M_m), \sigma \right) &= \left[ \prod_j p(T_j, M_j) \right] p(\sigma) \\ &= \left[ \prod_j p(M_j \mid T_j) p(T_j) \right] p(\sigma), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+p+%5Cleft%28+%28T_1%2C+M_1%29%2C+%5Cdots%2C+%28T_m%2C+M_m%29%2C+%5Csigma+%5Cright%29+%26%3D+%5Cleft%5B+%5Cprod_j+p%28T_j%2C+M_j%29+%5Cright%5D+p%28%5Csigma%29+%5C%5C++%26%3D+%5Cleft%5B+%5Cprod_j+p%28M_j+%5Cmid+T_j%29+p%28T_j%29+%5Cright%5D+p%28%5Csigma%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
and that

To complete the prior specification, we just need to specify the priors for 
The
For

where 

- Get some estimate
of
and take the residual standard deviation).
- Pick a value of
- Pick a value of
th quantile of the prior on
. Chipman et al. recommend considering
,
or
.
For users who don’t want to choose 

The
The prior for a tree
- The probability that a node at depth
(the root node having depth 0) is non-terminal.
- If a node is non-terminal, the probability that the
- Once the splitting variable for a node has been chosen, a probability over the possible cut-points for this variable.
Chipman et al. suggest the following:
, where
and
are hyperparameters. Authors suggest
and
to favor small trees. With this choice, trees with 1, 2, 3, 4 and
terminal nodes have prior probability of 0.05, 0.55, 0.28, 0.09 and 0.03 respectively.
- Chipman et al. suggest the uniform distribution over the
- Given the splitting variable, Chipman et al. suggest the uniform prior on the discrete set of available splitting values for this variable.
The
For computational efficiency, Chipman et al. suggest using the conjugate normal distribution

where 

![\mathbb{E}[Y \mid x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY+%5Cmid+x%5D&bg=ffffff&fg=333333&s=0&c=20201002)




If we choose 
![\mathbb{E}[Y \mid x] \in (y_{min}, y_{max})](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY+%5Cmid+x%5D+%5Cin+%28y_%7Bmin%7D%2C+y_%7Bmax%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)
Other notes
In theory, once we define a prior and likelihood we have a posterior. The practical question is whether we can derive this posterior or sample from it efficiently. Section 3 of the paper outlines a Bayesian backfitting MCMC algorithm that allows us to sample from the posterior distribution.
The set-up above applies for quantitative
References:
- Chipman, H. A., George, E. I., and McCulloch, R. E. (2010). BART: Bayesian additive regression trees.
- Chipman, H. A., George, E. I., and McCulloch, R. E. (1998). Bayesian CART model search.
 and design matrix
and design matrix  . In an
. In an 

 is a second hyperparameter which is usually taken to be greater than 1. The penalty function can be written explicitly:
is a second hyperparameter which is usually taken to be greater than 1. The penalty function can be written explicitly:
 and
and  . The dotted lines are the penalties’ transition points (
. The dotted lines are the penalties’ transition points ( and
and  ). The SCAD and lasso penalties are the same for
). The SCAD and lasso penalties are the same for ![\beta \in [-\lambda, \lambda]](https://s0.wp.com/latex.php?latex=%5Cbeta+%5Cin+%5B-%5Clambda%2C+%5Clambda%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The SCAD and MCP penalties are constant for
. The SCAD and MCP penalties are constant for ![\beta \notin [-a \lambda, a \lambda]](https://s0.wp.com/latex.php?latex=%5Cbeta+%5Cnotin+%5B-a+%5Clambda%2C+a+%5Clambda%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
 (“selection”) and
(“selection”) and  for all
for all  (“unbiasedness”), MCP minimizes the maximum concavity
(“unbiasedness”), MCP minimizes the maximum concavity
 representing
representing  observations, each consisting of
observations, each consisting of  , and
, and  is estimated as the solution to the optimization problem
is estimated as the solution to the optimization problem
 is
is
 factor is sometimes written as
factor is sometimes written as  : the two formulations are equivalent.)
: the two formulations are equivalent.)
 is a symmetric and positive semidefinite matrix to be chosen by the user. The idea is that
is a symmetric and positive semidefinite matrix to be chosen by the user. The idea is that  reduces the structured elastic net penalty to the usual one. I would also like to point out that
reduces the structured elastic net penalty to the usual one. I would also like to point out that  -consistency of structured elastic net (Theorem 1), and determine conditions for selection consistency analogous to the
-consistency of structured elastic net (Theorem 1), and determine conditions for selection consistency analogous to the  for each feature
for each feature  ) gives structured elastic net selection consistency (Theorem 4).
) gives structured elastic net selection consistency (Theorem 4).

 . The LASSO corresponds to the case where
. The LASSO corresponds to the case where  and ridge regression corresponds to the case where
and ridge regression corresponds to the case where  . We typically do not consider the case where
. We typically do not consider the case where  as it results in a non-convex minimization problem which is hard to solve for globally.
as it results in a non-convex minimization problem which is hard to solve for globally. , where
, where  is the OLS solution. This is known as soft-thresholding, where we reduce something by a fixed value (in this case
is the OLS solution. This is known as soft-thresholding, where we reduce something by a fixed value (in this case  .
. ![p'(\beta) = \lambda \left[ I(\beta \leq \lambda) + \dfrac{(a\lambda - \beta)_+}{(a-1)\lambda}I(\beta > \lambda) \right],](https://s0.wp.com/latex.php?latex=p%27%28%5Cbeta%29+%3D+%5Clambda+%5Cleft%5B+I%28%5Cbeta+%5Cleq+%5Clambda%29+%2B+%5Cdfrac%7B%28a%5Clambda+-+%5Cbeta%29_%2B%7D%7B%28a-1%29%5Clambda%7DI%28%5Cbeta+%3E+%5Clambda%29+%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 . This corresponds to a quadratic spline function with knots at
. This corresponds to a quadratic spline function with knots at  . Explicitly, the penalty is
. Explicitly, the penalty is


 line. The line in black represents soft-thresholding (LASSO estimates) while the line in red represents the SCAD estimates. We see that the SCAD estimates are the same as soft-thresholding for
line. The line in black represents soft-thresholding (LASSO estimates) while the line in red represents the SCAD estimates. We see that the SCAD estimates are the same as soft-thresholding for  and are equal to hard-thresholding for
and are equal to hard-thresholding for  ; the estimates in the remaining regions are linear interpolations of these two regimes.
; the estimates in the remaining regions are linear interpolations of these two regimes.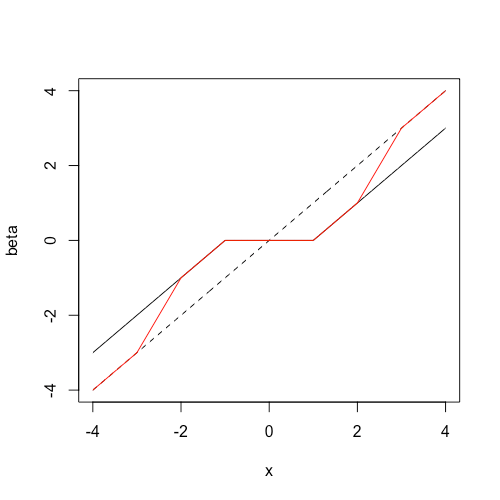
 , and for simplicity, assume that
, and for simplicity, assume that  and the columns of
and the columns of  . In ordinary least squares (OLS), we seek to minimize the objective function
. In ordinary least squares (OLS), we seek to minimize the objective function
 . When
. When 
 are usually non-zero, meaning that all features need to be included in the model. Sometimes, we prefer to have the model be sparse, i.e. have the response as a function of a small subset of features only. LASSO regression (Tibshirani 1996) achieves this by replacing the sum-of-squares penalty with an
are usually non-zero, meaning that all features need to be included in the model. Sometimes, we prefer to have the model be sparse, i.e. have the response as a function of a small subset of features only. LASSO regression (Tibshirani 1996) achieves this by replacing the sum-of-squares penalty with an  penalty:
penalty:
 . The “pointyness” of the
. The “pointyness” of the  , the LASSO can select at most
, the LASSO can select at most 
 and
and  are both tuning parameters.
are both tuning parameters.
![\phi \in (0, 1]](https://s0.wp.com/latex.php?latex=%5Cphi+%5Cin+%280%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is the parameter controlling the shrinkage of the coefficients, and
is the parameter controlling the shrinkage of the coefficients, and  is the indicator function on the set of variables
is the indicator function on the set of variables  so that
so that  if
if  ,
,  otherwise. When
otherwise. When  , we obtain the LASSO solution and as
, we obtain the LASSO solution and as  , we obtain the OLS solution for the selected variables.
, we obtain the OLS solution for the selected variables. .) The adaptive lasso minimizes
.) The adaptive lasso minimizes
 for some hyperparameter
for some hyperparameter  . The adaptive LASSO is selection consistent (under some assumptions).
. The adaptive LASSO is selection consistent (under some assumptions). ,
, ![\text{Annual Income } \in [\$40k, \$100k]](https://s0.wp.com/latex.php?latex=%5Ctext%7BAnnual+Income+%7D+%5Cin+%5B%5C%2440k%2C+%5C%24100k%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and  , we may want all 3 to be in the model or all 3 to be out of the model, but not just 1 of them in the model. The group LASSO (Yuan & Lin 2005) achieves this by imposing an
, we may want all 3 to be in the model or all 3 to be out of the model, but not just 1 of them in the model. The group LASSO (Yuan & Lin 2005) achieves this by imposing an  penalty on groups of coefficients. Let
penalty on groups of coefficients. Let  be a partition of
be a partition of  , i.e.
, i.e.  . The group LASSO minimizes
. The group LASSO minimizes
 .
.
![\alpha \in [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) is a parameter.
is a parameter.