
In a previous post I gave the context for my pet project ieee1275-rs, it is a framework to build bootable ELF payloads on Open Firmware (IEEE 1275). OF is a standard developed by Sun for SPARC and aimed to provide a standardized firmware interface that was rich and nice to work with, it was later adopted by IBM, Apple for POWER and even the OLPC XO.
The crate is intended to provide a similar set of facilities as uefi-rs, that is, an abstraction over the entry point and the interfaces. I started the ieee1275-rs crate specifically for IBM’s POWER platforms, although if people want to provide support for SPARC, G3/4/5s and the OLPC XO I would welcome contributions.
There are several ways the firmware takes a payload to boot, in Fedora we use a PReP partition type, which is a ~4MB partition labeld with the 41h type in MBR or 9E1A2D38-C612-4316-AA26-8B49521E5A8B as the GUID in the GPT table. The ELF is written as raw data in the partition.
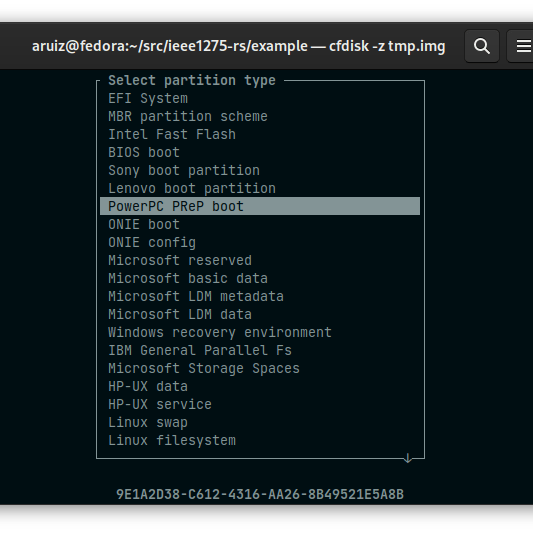
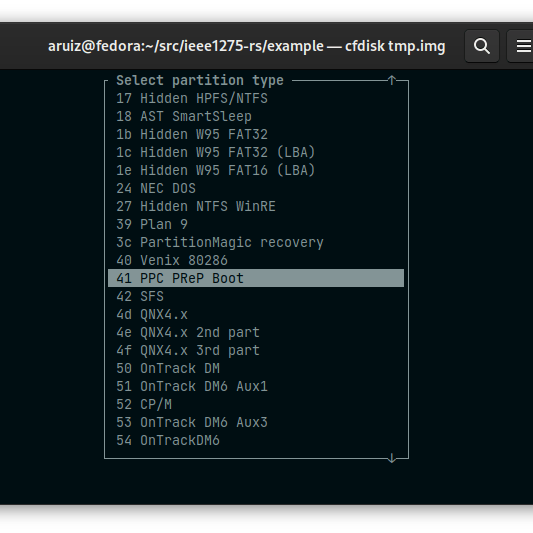
Another alternative is a so called CHRP script in “ppc/bootinfo.txt”, this script can load an ELF located in the same filesystem, this is what the bootable CD/DVD installer uses. I have yet to test whether this is something that can be used across Open Firmware implementations.
To avoid compatibility issues, the ELF payload has to be compiled as a 32bit big-endian binary as the firmware interface would often assume that endianness and address size.
The entry point
As I entered this problem I had some experience writing UEFI binaries, the entry point in UEFI looks like this:
#![no_main]
#![no_std]
use uefi::prelude::*;
#[entry]
fn main(_image_handle: Handle, mut system_table: SystemTable<Boot>) -> Status {
uefi::helpers::init(&mut system_table).unwrap();
system_table.boot_services().stall(10_000_000);
Status::SUCCESS
}Basically you get a pointer to a table of functions, and that’s how you ask the firmware to perform system functions for you. I thought that maybe Open Firmware did something similar, so I had a look at how GRUB does this and it used a ppc assembler snippet that jumps to grub_ieee1275_entry_fn(), yaboot does a similar thing. I was already grumbling of having to look into how to embed an asm binary to my Rust project. But turns out this snippet conforms to the PPC function calling convention, and since those snippets mostly take care of zeroing the BSS segment but turns out the ELF Rust outputs does not generate one (although I am not sure this means there isn’t a runtime one, I need to investigate this further), I decided to just create a small ppc32be ELF binary with the start function into the top of the .text section at address 0x10000.
I have created a repository with the most basic setup that you can run. With some cargo configuration to get the right linking options, and a script to create the disk image with the ELF payload on the PReP partition and run qemu, we can get this source code being run by Open Firmware:
#![no_std]
#![no_main]
use core::{panic::PanicInfo, ffi::c_void};
#[panic_handler]
fn _handler (_info: &PanicInfo) -> ! {
loop {}
}
#[no_mangle]
#[link_section = ".text"]
extern "C" fn _start(_r3: usize, _r4: usize, _entry: extern "C" fn(*mut c_void) -> usize) -> isize {
loop {}
}Provided we have already created the disk image (check the run_qemu.sh script for more details), we can run our code by executing the following commands:
$ cargo +nightly build --release --target powerpc-unknown-linux-gnu
$ dd if=target/powerpc-unknown-linux-gnu/release/openfirmware-basic-entry of=disk.img bs=512 seek=2048 conv=notrunc
$ qemu-system-ppc64 -M pseries -m 512 --drive file=disk.img
[...]
Welcome to Open Firmware
Copyright (c) 2004, 2017 IBM Corporation All rights reserved.
This program and the accompanying materials are made available
under the terms of the BSD License available at
http://www.opensource.org/licenses/bsd-license.php
Trying to load: from: /vdevice/v-scsi@71000003/disk@8000000000000000 ... Successfully loadedTa da! The wonders of getting your firmware to run an infinite loop. Here’s where the fun begins.
Doing something actually useful
Now, to complete the hello world, we need to do something useful. Remeber our _entry argument in the _start() function? That’s our gateway to the firmware functionality. Let’s look at how the IEEE1275 spec tells us how we can work with it.
This function is a universal entry point that takes a structure as an argument that tells the firmware what to run, depending on the function it expects some extra arguments attached. Let’s look at how we can at least print “Hello World!” on the firmware console.
The basic structure looks like this:
#[repr(C)]
pub struct Args {
pub service: *const u8, // null terminated ascii string representing the name of the service call
pub nargs: usize, // number of arguments
pub nret: usize, // number of return values
}This is just the header of every possible call, nargs and nret determine the size of the memory of the entire argument payload. Let’s look at an an example to just exit the program:
#[no_mangle]
#[link_section = ".text"]
extern "C" fn _start(_r3: usize, _r4: usize, entry: extern "C" fn(*mut Args) -> usize) -> isize {
let mut args = Args {
service: "exit\0".as_ptr(),
nargs: 0,
nret: 0
};
entry (&mut args as *mut Args);
0 // The program will exit in the line before, we return 0 to satisfy the compiler
}When we run it in qemu we get the following output:
Trying to load: from: /vdevice/v-scsi@71000003/disk@8000000000000000 ... Successfully loaded
W3411: Client application returned.Aha! We successfully called firmware code!
To be continued…
To summarize, we’ve learned that we don’t really need assembly code to produce an entry point to our OF bootloader (tho we need to zero our bss segment if we have one), we’ve learned how to build a valid OF ELF for the PPC architecture and how to call a basic firmware service.
In a follow up post I intend to show a hello world text output and how the ieee1275 crate helps to abstract away most of the grunt to access common firmware services. Stay tuned!



