西浦氏の Scientific Reports 論文について(7)「ワクチンで感染者が9割減」は誤り はこちらに。
https://sarkov28.hatenablog.com/entry/2024/12/17/184600
「接触8割減」の問題をまとめた論考 はこちらに。
https://sarkov28.hatenablog.com/entry/2024/05/17/213470
私がネット上でしていることの まとめ はこちらに。
https://sarkov28.hatenablog.com/entry/2022/03/29/160915
目次
- (1)序論
- (2)Google Colab で動作する改変プログラム
- (3)開示プログラムは、論文の Figure S5 を再現しない
- (4)デルタ株比率の最適化計算のコスト関数は不適切
- (5)デルタ株比率推定の初期値設定が不適切
- (6)結果
- (7)考察
- (付録A) デルタ株に関する2つの概念
- (付録B) プログラムA移動部分の動作確認
- (付録C) 高精度パラメータが必要な理由
- (付録D) 計算環境の検証
- (付録E) 局所極小の実態
- 更新履歴
(1)序論
西浦氏らのグループは、2023-10 に Scientific Reports にコロナワクチンに関する論文 [Kayano 2023] を発表しました。
これは後に共同通信が「コロナワクチンで死者9割以上減 京都大チームが推計」と報じた論文です。(以下では [Kayano 2023] を Sci Rep 2023 論文、と書きます。)
Evaluating the COVID-19 vaccination program in Japan, 2021 using the counterfactual reproduction number
https://doi.org/10.1038/s41598-023-44942-6
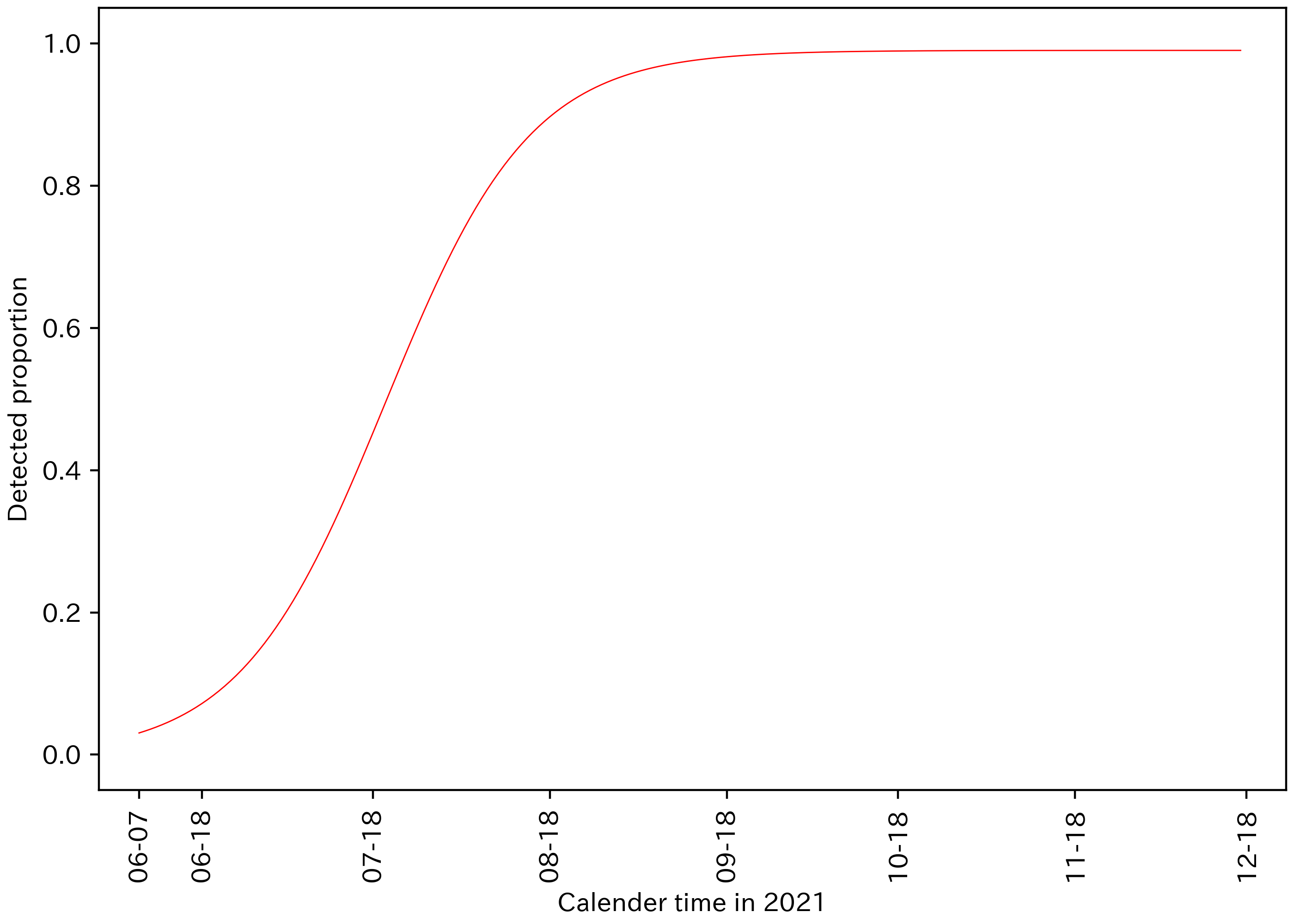
Sci Rep 2023 論文は、補足情報の Figure S5 に、白丸でデルタ株比率の観測値を示し、赤線でそれをモデル化しています。論文はこの赤線を、最大値が 1 のロジスティック曲線だと説明しています。図1.1 が論文の Figure S5 です。

図1.1 Sci Rep 2023 論文 補足情報 Figure S5
最近(2025-04-19)になって西浦氏は、この論文の(HER-SYS データを除く)データと、計算に用いたプログラムを Zenodo で開示しました。プログラムは Evaluating the COVID-19 vaccination programs in Japan 2021_shared code_04112025.R です。本稿は、このプログラムの検証を行います。以後このプログラムを 開示プログラム と呼びます [注1a]。HER-SYS データが示されていないので、開示プログラムの主要部分は動きません。しかしある程度は動かすことができます。
私は開示プログラムを改変し、Google Colab 上で動作するプログラムを作成しました。改変の内容については(2)節 で説明します。 (3)節 では、開示プログラムが論文の Figure S5 を再現しないことを示します。 (4)節 では、デルタ株比率の最適化計算のコスト関数に不適切なところがあることを述べます。 (5)節 では、デルタ株比率の最適化計算における初期値の決定方法が不適切であることを述べます。 (6)節 では結果を述べ、(7)節 では考察を述べます。
[注1a] 本稿では可搬性を考慮し、開示プログラムのファイル名を Evaluating the COVID-19 vaccination programs in Japan 2021_shared code_04112025.R と表記します。Zenodo で公開されているファイルでは COVID-19 のハイフンが 見た目が似た別の文字になっていますが、ここでは通常のハイフンに置き換えました。(Zenodo 版は Unicode で U+2011、本稿が使う ASCII のハイフンは U+002D。)
(2)Google Colab で動作する改変プログラム
(2-1) 作成したプログラムの内容
私は、Zenodo で開示された R言語のプログラムを改変し、2つのプログラムを作成しました。
- プログラムA(基準版)
開示プログラムに検証のための必要最小限の修正をしたもの。
https://colab.research.google.com/drive/1M3FMaatdXp8kppEvuzKZnMme_svwbAFh?usp=drive_link - プログラムB(R 言語 4.0.0 版)
プログラムAの一部を、R 言語 version 4.0.0 で動作するようにしたもの。
https://colab.research.google.com/drive/1LwZZY6JG9U1ugaY0AySOERECnos7GB_C?usp=drive_link
また、python でプログラムCとプログラムDを作成しました。これらはプログラムAと同じ問題を計算したり、この記事に示したグラフを作成するためのものです。
- プログラムC
各種の計算とグラフ描画のためのもの。
https://colab.research.google.com/drive/1ztMyYaFYr-Yz234ir2eOOf8Qmxd01QK4?usp=drive_link - プログラムD
図4.2 や 図E.1 のためのもの。
https://colab.research.google.com/drive/1mcU_AFKKqI8JJM2bxtrY_ql0LWSb9eL9?usp=drive_link
(2-2) 開示プログラムからの必要最小限の改変
開示プログラムからプログラムA(基準版)への主な修正点は以下です。
- (a) ライブラリをインストールする関数、
install_libraries()を追加。 - (b)
install_libraries()を使ってライブラリpacmanをインストール。 - (c) データの読み込み先を指定する
default_data_dirを導入し、ファイル読み込みに使用。 - (d) デルタ株比率に関する処理を HER-SYS データ読み込みの前に移動。
- (e) デルタ株比率の数理モデルのパラメータ計算の結果
outcome_deltaを画面に出力。 - (f)
の計算結果
new_delta_df_v2をファイルに出力。
このうち、(d) が重要です。図 2.1 にその概要を示します。
開示プログラムでは、デルタ株比率に関する処理は、HER-SYS データの読み込みの後にあります。HER-SYS データの読み込みでプログラムは停止するため、このままではこの部分は計算されません。しかしこの計算は HER-SYS データや関連する処理に依存していなかったので、私はこの部分を HER-SYS データの読み込みの前に移動しました。具体的には、開示プログラムの 214行目から 286行目までを、155行目の前に移動しました。(以後、(・・・行目)と示すのは、開示プログラムにおける行数です。)
この移動により、デルタ株比率の数理モデルのパラメータ計算や の算出が行えるようになりました。(
については(付録A)をご参照下さい。)

図2.1 修正(d) の改変の概要。左は開示プログラムで、デルタ株比率などを計算するブロック(オレンジ)が File2 の処理より後ろに配置されている。右は同ブロックを File2 の処理より前へ移動した改変後の構成を示す。
(2-3) プログラムA(基準版)が開示プログラムと同様に動作することの確認
(2-2)節 に示した移動の後も、移動した部分(=デルタ株比率に関する処理)は開示プログラムと同様に動作しています。移動による動作の変化はありません。
私は、移動した部分が開示プログラムと同様に動作していることを確認しました。例えば開示プログラム 217行目は
delta_df <- data.frame(delta_0)
ですが、この右辺にあるのはその直前に読み込んだ変数なので、移動しても問題なく動作します。同様の確認を、移動対象(214行目から 286行目まで)の各行に対して行いました。(確認の詳細を(付録B)に示しました。)
したがって合理的に考えて、プログラムA(基準版)の移動した部分は、開示プログラムと同様に動作しています。
(3)開示プログラムは、論文の Figure S5 を再現しない
(3-1) 再現失敗の実証
プログラムA(基準版)は、デルタ株比率のロジスティック曲線のパラメータを最適化計算で計算しています。プログラムAは、初期値が (phi1, phi2, phi3) = (99, 45, 0.07) で収束値が (phi1, phi2, phi3) = (98.983709648339, 45.016562723587, 0.078734384848) になります [注3-1a]。このパラメータでグラフを作成しました。

図3.1 デルタ株比率のモデル曲線。開示プログラムと同じ計算によるパラメータから。
図3.1 は 図1.1(論文 Figure S5)の赤線と一致する必要があるので、重ね合わせて確認しました。

図3.2 論文の Figure S5 と 図3.1 との重ね合わせ
図3.2 の緑点線は、赤線に似ていますが一致しているとは言えません。
(2-3) 節で示したように、プログラムAは開示プログラムと同一のアルゴリズムで動作しています。そのプログラムAが白丸データから計算した緑点線は、論文補足情報の Figure S5 に示された赤線に近いものの、完全には一致せず(図3.2)、赤線を再現しませんでした [注3-1b]。
同一アルゴリズムであるプログラムAが Figure S5 の赤線を再現しないため、開示プログラムも Figure S5 の赤線を再現しないと考えられます。したがって今回の開示は、論文を再現するものとして不十分です。
[注3-1a] パラメータに多くの桁数の有効数字を示している理由については、(付録C)をご参照下さい。
[注3-1b] 図3.2 で緑点線が赤線を再現しなかった理由が (phi1, phi2, phi3) の丸め誤差ではないことは別途確認しています。これらパラメータを有効数字3桁で四捨五入した値を使ったグラフは(数値的に完全一致しないものの)視覚的には 図3.2 の緑点線と区別がつきませんでした。一方で 図3.2 の緑点線と赤線には明らかに視覚的な差があります。
(3-2) 図3.2 の不一致が私の作図上の不手際ではないことの検証
図3.2 は不一致を示していますが、赤線と緑点線は似ています。この不一致が、画像を重ねた私の不手際によるものなのかを検証するため、以下の要領で 図3.3 を作図しました。
- 論文 Figure S5 の赤線を再現する曲線を最適化計算で計算する。
- 論文の Figure S5 と 得られた曲線とを、図3.2 と同じ手順で重ね合わせる。
最適化計算や、重ね合わせ手順に不手際があれば、この要領で得られる 図3.3 には不一致が見られるはずです。

図3.3 最適化計算や重ね合わせ手順に不備があれば不一致になる図
図3.3 の赤線と緑点線は、視覚的には区別できません。最適化計算や重ね合わせ手順に、不手際はないと思われます [注3-2a]。
[注3-2a] 厳密に言うと、図3.3 の一致は最適化計算や重ね合わせ手順に不備がない可能性を完全に排除はしていません。例えば何らかの不備があっても、それを別の不備が相殺したために結果的に一致して見えている可能性を排除できないからです。しかしこのようなことが起こる可能性は一般にかなり小さいと考えられます。この可能性を含めて確認したい場合は、プログラムCの "Figure3_3.png" の作図部分をご参照下さい。
(3-3) 計算環境への依存性について
(3-1)節 で検討したのは、開示プログラムが論文のグラフを再現しないという問題です。本来こうした検討の際には、(使用言語の version などの)検証用の環境を論文の環境と一致させることが好ましいです。今回の開示情報には R 言語のバージョンに関する情報がないので、検証用の R 言語のバージョンを開示情報に合わせることはできませんでした。
しかし本稿が行った検証の計算は、西浦氏の開示プログラムの計算と一致していると考えられるので、その理由を(付録D)に述べました。なお(3)節以外で述べている問題には、R 言語のバージョンなどの計算環境との実質的な関係はありません。
(4)デルタ株比率の最適化計算のコスト関数は不適切
(4-1) コスト関数の問題点とその回避策
開示プログラムのデルタ株比率の最適化計算のコスト関数は以下です。
ここで は週を表す変数であり、図1.1(論文 Figure S5)の各白丸の x軸の値に対応しています。
はデルタ株比率の観測値です。
はデルタ株比率のモデル値です。式(1) は、観測値とモデル値が近づくと低下するように構成されています。
ただし は、
が 0 に近づくと 図4.1 に示すように急速に減少し、
では負の無限大に発散します(以下、単に 発散 と略記)。

図4.1 のグラフ。
は発散する。このグラフの左下は
(x, y) = (0.000001, -13.8)。
したがって はいずれかの
で
になる場合(あるいは0に近づく場合)は有限な値を計算できなくなります。これは特殊な状況ではなく、
関数を使い、このような(引数が 0 に近づく)計算を行う場合は常に注意すべき問題です。特に今回の計算では、
となるのは想定すべき事態です。最適化計算がこの状態を目指しているからです。
の問題を回避するのは難しいことではありません。例えば 式(1) の末尾に正の
を加えれば、
関数の引数が
に近づくのを回避できます [注4-1a]。
これはよく採られる回避策であり、特殊なものではありません。しかし開示プログラムはこうした対応を採っていません。開示プログラムのコスト関数 式(1) はこの意味で不適切です。
本稿の検討では特記しない限り 式(1) を使いました。可能な限り開示プログラムと同じ計算をするためです。しかし一部では の問題が発生し、式(2) を使ったこともあります。(この場合でも最終的な関数の評価値としては 式(1) を使いました [注4-1b]。)
[注4-1a] として幾つを使うのが適切なのかは、ここでは検討しません。
は、コスト関数に与える影響を小さくするものとして使用しています。また
への対策としては他に、異なる関数を用いる方法もあります。
[注4-1b] この回避方法は万全ではありません。最終的な関数の評価値計算に 式(1) が使用できない状況もあり得るからです。こうした状況があり得るので、式(1) のようなコスト関数を使うべきではないのです。
(4-2) コスト関数の断面の形状 ─ 最適化を誤誘導する仕組み
本節で示すグラフは、コスト関数の特徴的な形状を可視化したものです。
開示プログラムのコスト関数は (phi1, phi2, phi3) と開示情報の File5 から計算されます。File5 は所与のものと考えていいので、コスト関数は実質的に3パラメータです。本節ではコスト関数の特定の断面のグラフをプログラムDを用いて計算します。
開示プログラムの初期値 (phi1, phi2, phi3) = (99, 45, 0.07) を基準としました。この周辺で、phi1 だけを変化させながらコスト関数値を計算し、横軸を phi1、縦軸をコスト関数値とするグラフを作成しました。図4.2 です。

図4.2 (phi2, phi3) = (45, 0.07) で phi1 を変化させた時のコスト関数値
図4.2 には12個の「局所極小」があります。これは、以下の状況があるからです。
(phi2, phi3) = (45, 0.07)に対して、各白丸を通過するphi1が存在する。その(phi1, phi2, phi3)では、(通過する白丸に関する残差がなくなるために)コスト関数 式(1) がを計算し、関数値が発散する。
図4.2 に12個の「局所極小」が見えているのは、上の状況が 図1.1(論文 Figure S5)の12個の白丸それぞれで起きているからであることを、別途確認しています。(正確にはこれは局所極小ではなく、実質的な局所極小にすぎません。(付録E)をご参照ください。)
またこれら「局所極小」は、図4.2 に示したように形状が極端に狭く、中心に向かって勾配が急峻化しています。(この形状は、図4.1の左端の形状と密接に関連しています。)
つまりコスト関数 式(1) は
- 無数の「局所極小」がある。
- それぞれの「局所極小」の形状が極端に狭く、中心に向かって勾配が急峻化する。
という性質があります。このため最適化計算は、「局所極小」に収束しやすくなります。なお 式(2) のように を加えればコスト関数値は発散しなくなり、比較不能になる問題は解消します。それでも
が小さければ「局所極小」は残るので、最適化が初期値に強く依存することに変わりはありません。
(4-3) コスト関数が「適切」と示す曲線が白丸のモデルとして適切とは限らない
式(1) が示すように、また 図4.2 が例示するように、開示プログラムのコスト関数は「計算されたパラメータによる曲線が一つの白丸の上を通過すれば、(他の白丸との位置と無関係に)関数値が発散する」との性質を持っています。
開示プログラムが使用しているロジスティック曲線の式は、式(3) です。
式(3) を phi3 について解くと、式(4) になります。
したがって 式(4) を満たす 正の x, y, phi1, phi2 があれば (x, y) を通過する (phi1, phi2, phi3) を計算できます。
式(4) を使い、例として File5 の8番目の白丸、(x, y) = ('2021-07-26', 67) を通過する phi3 を (phi1, phi2) = (85, 35) で計算しました [注4-3a]。この曲線のコスト関数は発散します。こうして得られた (phi1, phi2, phi3) による曲線を描画し、論文の Figure S5 と重ね合わせたのが 図4.3 です。

図4.3 (x, y) = ('2021-07-26', 67) を通過し、コスト関数が発散する曲線と、論文 Figure S5 との重ね合わせ
図4.3 の緑点線が白丸の列全体と乖離していることは一目で分かります。しかしこの緑点線は、('2021-07-26', 67) の白丸を通過しているためにコスト関数値は負の無限大に発散していて、数値的にはこの曲線を「最適」と示しています。この緑点線はコスト関数が不適切であることの端的な例です。開示プログラムのコスト関数の値は、「曲線の白丸のモデルとしての適切さ」を表現できていません。しかも上の計算方法から明らかなように、この緑点線と同様にコスト関数が「最適」と示す曲線は無数にあります [注4-3b]。
なお 式(2) のように を加えるとこの曲線のコスト関数値は「最適」にはなりません。
のために発散しなくなり、他の白丸と緑点線との不一致によってこのコスト関数の値は(「局所極小」ではありますが、「局所極小」の値としては)小さめのものにならないからです [注4-3c]。
[注4-3a] 計算された phi3 の値は 0.08762139076632007 なので、描いた曲線のパラメータは (phi1, phi2, phi3) = (85, 35, 0.08762139076632007) です。この phi3 は(付録C)で例示した小数点以下12桁では精度が足りず、16桁の精度が必要です。16桁ならば 式(1) は発散しますが、15桁では約-24.0 になります。 付近の発散が起きるところでは高精度の数値が必要なのですが、この事例はこれに該当しています。
[注4-3b] 今回は (phi1, phi2) = (85, 35) で計算しましたが、他の (phi1, phi2)、例えば (81.2, 35) でも同様の計算を行うことができ、異なる曲線が得られ、その曲線のコスト関数値は発散します。
[注4-3c] 図4.3 の緑点線の 式(2) の値は約12.1 であり、小さめとは言えません。例えば 図3.1 の曲線の 式(2) の値は約-13.4 です。
(4-4) コスト関数を改善する 式(2) 以外の方法
開示プログラムのコスト関数 式(1) を改善する一つの方法は、式(1) を 式(2) のように修正することです。式(2) では を使いましたが、この値が最適とは限りません [注4-1a]。(付録E)では、別の
の値について述べています。
コスト関数を改善する他の方法として、別のコスト関数の使用があります。別稿 は Zenodo への情報開示の前に書いた記事ですが、ここではよく使われる別のコスト関数 を用いた場合について検討しています。
(5)デルタ株比率推定の初期値設定が不適切
(4)節 では、開示プログラムのコスト関数が、「曲線の白丸のモデルとしての適切さ」を表現できていないと述べました。しかし本節では、この問題をとりあえず措き、開示プログラムの主張「より小さなコスト関数値の曲線が、より適切なモデルである」に沿って検討します。
(5-1) 単一初期値での最適化は不適切
論文は、デルタ株比率をロジスティック曲線でモデル化したと述べています。ロジスティック曲線のパラメータ (phi1, phi2, phi3) は、コスト関数 nll_func_delta を最小化して計算されています。(コスト関数は、ロジスティック曲線が白丸に近づくと低下するように構成されていますが、(4)節に述べた問題があります。数式は(4)節の 式(1) を参照。)
開示プログラムの処理は、
単一の初期値による最適化計算の収束値を最終的な結果とする
との方法です(主に、開示プログラムの255行、256行)。一般論として、この方法でも(プログラム作成者が意図したであろうレベルの)適切な計算結果が得られる可能性がゼロとは言えません。しかし一般に(この問題のような非線形最適化問題では)異なる初期値から計算を開始すると、異なる収束値が得られることがあります。プログラム作成者は、少なくともそうなることを想定したプログラムを作成すべきです。これを想定した場合、
複数の(しばしば多数の)初期値による最適化計算の収束値を得て、その中からコスト関数の意味で最適なものを最終的な結果とする
などの対策を採ります。しかし開示プログラムはこうした対策を採っていません。 特に、開示プログラムのコスト関数には、図4.2 が例示したように無数の「局所極小」があります。このようなコスト関数において単一の初期値から計算を開始すると、その計算は初期値に近い「局所極小」に収束する可能性が高いです。
これは論文の主たる計算に用いる重要なパラメータを求める計算であるのに、開示プログラムは結果が初期値に強く依存する設計になっています。開示プログラムの「単一の初期値による」との方法で (phi1, phi2, phi3) を計算するのは不適切です [注5-1a]。
[注5-1a] 多数の初期値から計算をするなどの対策を講じても、(phi1, phi2, phi3) の計算から偶然の要素(運の要素)を完全に排除することは一般にできません。ここで述べている「不適切」というのは、「問題を回避するために通常採られる対策を採っていない」という意味です。
(5-2) 別初期値でのコストの改善
(5-1)節 では、開示プログラムが単一の初期値による収束値を最終的な結果としている問題を一般論として指摘しました。本節ではこの問題が(一般論ではなく)現実化している例を示します。
本節ではプログラムCを使います。開示プログラムの単一の初期値は、(phi1, phi2, phi3) = (99, 45, 0.07) であり(255行目)、プログラムAも同じ値を使っています。本節ではこれを以下のように変更しながら計算しました。
「phi1 を [98, 99, 100]、phi2 を [44, 45, 46]、phi3 を [0.06, 0.07, 0.08] と変化させながら初期値を作成し、この初期値から最適化計算を行う」という方法です。
最初に作成される初期値は (98, 44, 0.06) であり、最後は (100, 46, 0.08) であり、合計で 個の初期値になります。
27個の中には開示プログラムの初期値 (99, 45, 0.07) が含まれていて、この場合の収束値はプログラムAと(したがって開示プログラムと)同じものになります。
ここで採用しているのは、開示プログラムが用いた単一の初期値の周辺を探索する方法として、きわめて素朴なものです。これは、初期値決定の良い方法として示しているのではなく、むしろ開示プログラムのように単一の初期値を採用する前に、論文著者らが少なくともこのような探索を試みるべきだ、という例として示しています。
27個の初期値から計算し、結果を集計すると 表5.1 になりました。
| 計算の特徴 | 計算回数 | 得られた 解の個数 |
より適切な 解の個数 |
|---|---|---|---|
| 開示プログラムと 同じ計算 ただし初期値を変更 |
27 |
27 (100%) |
11 (40.7%) |
表5.1 (5-2)節の 27個の初期値による計算結果の集計。「より適切」は「開示プログラムより 式(1) の値が小さい」。
表5.1 に「得られた解の個数」という項目があるのは、初期値によっては解が求まらないことがあるからです。今回の場合、そうした事例はありませんでした。また全27回のうち 11回で、開示プログラムより小さなコスト関数値が得られました。
表5.1 で集計した 27個の初期値のうち、最小のコスト関数値になった初期値の計算を、開示プログラムの初期値の計算と比較したのが 表5.2 です。
| 初期値の特徴 | 初期値 | 計算結果(収束値) | 収束値の コスト関数値 |
|---|---|---|---|
| (a) 開示プログラム の初期値 |
(99, 45, 0.07) |
(98.98, 45.02, 0.07873) |
-13.4 |
| (b) 表5.1のうち コスト関数値 最小の初期値 |
(99, 46, 0.08) |
(99.00, 46.00, 0.07721) |
-31.0 |
表5.2 開示プログラムの初期値による計算結果と、表5.1 のうちコスト関数値最小の計算結果の比較。初期値と収束値は (phi1, phi2, phi3)。収束値とコスト関数値は概数。収束値のより詳細な値については [注5-2a]。コスト関数値は小さいほど適切と見なす構成なので、開示プログラムよりも適切な計算結果が得られている。
(b) のコスト関数値は、プログラムAのコスト関数値(約-13.4)よりも小さな値(約-31.0)になりました。これは、コスト関数の意味で開示プログラムより適切なパラメータを発見したことを意味します。(5-1)節 で「「単一の初期値による」との方法で計算するのは不適切」と述べましたが、今回見つけた収束値はその指摘が妥当だったことの実例です。
ただしここで発見した収束値によるグラフと、開示プログラムの収束値によるグラフ(図3.1)とにおいて、どちらが白丸のモデルとして適切なのかは、視覚的にははっきりしません。図3.2 と同じ要領で重ね合わせを作成しました。図5.1 です。

図5.1 論文の Figure S5 と 表5.2 (b) の収束値による曲線との重ね合わせ
[注5-2a] 表5.2 (a) の収束値の詳細は (3-1)節 に。(b) の収束値の詳細は (99.001589540997, 45.997614933974, 0.077212061586) です。多くの桁数を示す理由は(付録C)をご参照下さい。
(5-3) 広範な初期値探索でのコストの大きな改善
(5-2)節 では、初期値を素朴な方法で複数用意した結果を開示プログラムの方法と比較しました。本節で示すのはランダムな1000個の初期値による計算です。また、最適化アルゴリズムを開示プログラムが採用している BFGS 法から Nelder-Mead 法 に変更しました。
プログラムCを使いました。初期値はラテンハイパーキューブサンプリングによる1000個です。この計算をコスト関数 式(1) を用いて行うと(4)節 で述べた に関する問題が発生したので、コスト関数は 式(2) を使いました。
1000個の結果を集計すると 表5.3 になりました。
| 計算の特徴 | 計算回数 | 得られた 解の個数 |
より適切な 解の個数 |
|---|---|---|---|
| 開示プログラムから 計算言語、 最適化アルゴリズム、 初期値を変更 |
1000 |
870 (87.0%) |
839 (83.9%) |
表5.3 1000個の初期値による計算結果の集計。「より適切」は「開示プログラムより 式(1) の値が小さい」。
表5.3 で集計した 1000個の初期値のうち最小のコスト関数値になった計算を、開示プログラムの初期値の計算などと比較したのが 表5.4 です。比較のため、表5.2 に追加する形で示します。
| 初期値の特徴 | 初期値 | 計算結果(収束値) | 収束値の コスト関数値 |
|---|---|---|---|
| (a) 開示プログラム の初期値 |
(99, 45, 0.07) |
(98.98, 45.02, 0.07873) |
-13.4 |
| (b) 表5.1のうち コスト関数値 最小の初期値 |
(99, 46, 0.08) |
(99.00, 46.00, 0.07721) |
-31.0 |
| (c) 表5.3のうち コスト関数値 最小の初期値 |
(93.06, 42.41, 0.09895) |
(94.53, 42.20, 0.1004) |
-140.3 |
表5.4 表5.3 のうちコスト関数値最小の計算結果。表5.2 に追加して示した。一部の結果は概数。より詳細な値については [注5-3a]。コスト関数値は小さいほど適切と見なす構成なので、(c) が最も適切な計算結果になる。
表5.4(c) の収束値によるグラフで、図3.2 と同じ要領で重ね合わせを作成したのが、図5.2 です。

図5.2 論文の Figure S5 と 表5.4 (c) の収束値による曲線との重ね合わせ
図5.2 の緑点線は、視覚的にも赤線より白丸のモデルに適合しています。図5.2 の緑点線の存在は、(5-1)節 に示した「「単一の初期値による」との方法で計算するのは不適切」との指摘の正しさを強く支えます。
なお本来なら、数理モデルの白丸への適合は、専らコスト関数で評価すべきです。ところがコスト関数には(4)節 に述べた問題があるので、この関数の値だけを指標とすることには疑問があります。このため、(主観的になるので好ましくない)視覚的な判断が必要になっています。
[注5-3a] 表5.4 の (a)(b) の詳細については [注5-2a] をご参照ください。(c) のより詳細な初期値は (93.059492680469, 42.405480670085, 0.098950644407)、収束値は (94.530734183607, 42.198896016416, 0.100367830190) です。多くの桁数を示す理由は(付録C)に。
(6)結果
西浦氏は、Sci Rep 2023 論文 に関連して Zenodo にプログラムとデータを開示しました。
開示されたプログラムは本来、論文の補足情報の Figure S5 の赤線のパラメータを再現するはずですが、(3)節 で示したように、実際には再現しません。
さらにこのプログラムのコスト関数は、 になる可能性のある値に対して
を計算しています。このコスト関数は負の無限大に発散する可能性があることを(4)節で述べました。この問題を回避する一般的な方法がありますが、開示されたプログラムはこの方法を採用していません。コスト関数の特定の断面を 図4.2 に示し、コスト関数の形状に問題があることを確認しました。
また、白丸のモデルとして適切とは言えない曲線のコスト関数が負の無限大に発散する(=適切だと評価する)例として 図4.3 を示しました。この曲線は特別な例ではなく、同様の事例は無数にあります。つまりこのコスト関数は、「白丸のモデルの適切さを評価する」との目的を果たせていません。
(5)節では、開示されたプログラムが Figure S5 の赤線のパラメータを求める計算を、単一の初期値により行っている問題を検討しました。開示プログラムの初期値の周辺を素朴な方針で探索するだけでも、コスト関数の意味で優れた収束値が見つかることを 表5.1、表5.2 に示しました。また、多数の初期値から計算を開始することでさらにコスト関数の意味で優れた収束値が見つかることを、表5.3、表5.4 に示しました。表5.4 (c) の曲線は、視覚的にも Figure S5 白丸によく適合します(図5.2)。また、問題のあるコスト関数ではありますが関数値を参考までに示しておくと、開示プログラムと同じロジックが示す収束値では約-13.4 である一方、表5.4(c) では約-140 です。
(7)考察
本稿で検討した問題の中でも重大で、かつ事実として明確なのは、「プログラムA(=開示プログラムと同様に動作)が、論文のデルタ株比率 Figure S5 の赤線を再現しない」という点です。(3)節 に示したこの問題は、単なる数値の不一致ではなく、論文に掲載された図が、開示されたプログラムとデータによって再現できないことを意味しています。この点において、開示されたプログラムは論文の計算を再現する情報開示ではありません。再現性は科学的検証の前提条件であり、これが実現していないため、論文の信頼性に重大な疑義が生じています。
開示プログラムのコスト関数には(4)節 で示した問題があります。 は、残差ゼロ付近で数値的に不安定になります。一般には
を加えるなどで安定化が図られるのですが、開示されたプログラムはこれを行っていません。これは実装ミスではなく、設計方針における選択の問題だと思われ、計算の安定性に対する配慮不足を示唆しています。この意味でこのコスト関数は不適切です。
さらに(5)節 で検討した通り、このプログラムは重要なロジスティック曲線のパラメータ推定で、単一の初期値による最適化計算を行っています。 これも設計方針における選択の問題であり、非線形最適化でよく用いられる方法と比較して、結果の信頼性を大きく損なうものと言えます。さらに、異なる初期値から開始した計算がより良いコスト関数値に収束することを示したので、この初期値に関する設計方針は、一般論としての問題ではなく、開示プログラムが解こうとしている課題における、具体的な問題につながっています。この意味でこの初期値の設定方法は不適切です。
論文が、こうした設計方針を正当化する説明を論文本文、補足情報、開示プログラムなどで十分に示していない点も問題です。単一の初期値で十分である、単一の初期値としては (99, 45, 0.07) が適切であると判断したなら、あるいはコスト関数の安定化が不要だと判断したなら、その理由を明示的に示す必要があります。明示的な説明がない以上、読み手はこれらが特段の理由なく判断されたと捉えざるを得ません。
西浦氏が Zenodo で開示したのは、論文の最終的な計算を行うものではなく、試作段階の小規模で不完全な計算を行うプログラムだった可能性もありますが、いずれにせよ西浦氏ら論文著者には、まず次の最重要の問題があること確認し、その理由を説明する責任があります。
- 開示したプログラムが、論文の Figure S5 の曲線を厳密に再現しないこと。
現状は、情報開示によって論文の再現性を担保するという科学的要件が満たされていません。
また西浦氏ら論文著者には、デルタ株比率の数理モデル計算に関して以下を説明する責任があります。
- 開示したプログラムが、
- 開示したプログラムが、最適化計算を単一の初期値で行っている理由。
- 開示したプログラムが、単一の初期値として他の値ではなく特に
(99, 45, 0.07)を選択した根拠。 - 開示したプログラムが
(99, 45, 0.07)以外の初期値から計算を開始すれば、コスト関数の意味でより適切な数理モデルが得られる例があることの説明。
これらは、開示したプログラムが示している計算の妥当性を示すために必要です。
本稿は開示プログラムのうちデルタ株比率に関する部分のみを検証し、幾つかの問題を指摘しました。HER-SYS データがないため、感染者数推計など後続解析の再計算は行えていません。HER-SYS データが必要な計算部分についても、同様の検証を行う必要があります。
(付録A) デルタ株に関する2つの概念
論文には、デルタ株に関する2つの概念があります。
1つ目の概念は「その時点で市中にあるデルタ株の比率」です。これは 図1.1(論文 Figure S5)の縦軸であり、[0, 1] の範囲です。本稿ではこれを単に「デルタ株比率」と記述します。図1.1 の白丸がデルタ株比率の観測値であり、赤線がデルタ株比率のモデル値(=数式で表現した値)です。
2つ目の概念は、論文が「その時点でのデルタ株による感染性増加のプロファイル」と説明している変数 です。これは
[1, 1.5] の範囲です。本稿ではこれを と記述します。
(=2つ目)は、デルタ株比率のモデル値(=1つ目のモデル値。図1.1 の赤線。)を変換して計算します。開示プログラムで
は、変数
new_delta_df_v2 に入ります(開示プログラム 280行目)。
(付録B) プログラムA移動部分の動作確認
箇条書きで示したのは、プログラムA(基準版)の移動部分が開示プログラムと同様に動作することの確認の一部です。(2-3)節 に述べた事項の詳細です。
移動した行と、それぞれの動作が移動後も変わらない理由を述べています。
- (a) 215行
delta_0 <- read.csv('.../File5.Delta_japan.csv')
この右辺はファイルからの読み込みです。 - (b) 217行
delta_df <- data.frame(delta_0)
この右辺にあるのは (a) で読み込んだ変数です。 - (c) 222行
delta_df2 <- delta_df %>% filter(Date <= as.Date("2021-08-23"))
この右辺にあるのは (b) で定義した変数と定数です。 - (d) 224行
delta_duration <- as.numeric(max(delta_df2$Date) - min(delta_df2$Date)) + 1
この右辺にあるのは (c) で定義した変数です。 - (e) 226行
obs_delta <- numeric(delta_duration)
この右辺にあるのは (d) で定義した変数です。
(a)~(e) の要領で開示プログラムの移動する部分の全て(214行目から 286行目まで)を検討し、これらを 155行目の前に移動しても動作が変わらないことを確認しました。移動する全ての行についての確認は、
https://docs.google.com/spreadsheets/d/1AdPOYo7mWRaJetWOdxmqJTXkgdk6RcuOZ4ZoFEcrtIM/edit?usp=sharing
をご参照下さい。
(付録C) 高精度パラメータが必要な理由
[注3-1a]、[注5-2a]、[注5-3a] では、(phi1, phi2, phi3) の値として多くの桁数を示しています。多くの桁数が必要な理由は以下です。
この最適化計算の入力データ(File5 の、市中のデルタ株比率)の有効数字は高々2桁です。しかし特記のない限り本稿では、ロジスティック関数のパラメータを小数点以下の有効数字を12桁で示します。多くの桁数で示すのは、コスト関数の値がこれらパラメータの値に非常に敏感な場合があるためです。
例えばパラメータ phi3 が 1e-12 変化しただけで、コスト関数の値が約-140 から約-136 へと変化することがあります。こうしたことが起きるのは、この最適化計算に用いているコスト関数が の形であるため、残差が 0 に近づく付近でのコスト関数の傾きが極めて大きくなるからです。この敏感さは(4)節 で述べているコスト関数の問題に密接に関わっています。グラフを視覚上区別できない程度に描くためならばこれほどの精度は必要ありません。高精度の数値が必要になるのは、曲線が目標データ(の一部)に接近した状況でコスト関数値を計算する場合です。[注4-3a] に挙げた例は特にこの場合に該当していて、16桁の精度が必要になっています。
(付録D) 計算環境の検証
本記事で行った検証の計算が、西浦氏の計算環境における開示プログラムの計算と一致していると考える根拠を述べます。(3-3)節 に述べた事項の詳細になります。
- (a) 西浦氏が 2020-05 に github https://github.com/contactmodel/COVID19-Japan-Reff に示した R 言語のプログラムには、version 4.0.0 で動作した旨が明記されています。
- (b) 私は、プログラムBとして R 言語 version 4.0.0 の環境を作り、今回の開示プログラムのデルタ株比率に関する処理を動作させました。すると R 言語 version 4.5.0(=検証に用いた R 言語)での動作と、計算結果が一致しました。(R 言語 version 4.2.2 でも結果は同様でした。)
論文が発表されのは、(a) のおよそ 3年半後ですから、論文の計算を行った R 言語は version 4.0.0 以降であろうと推測できます。その version 4.0.0 (や version 4.2.2)と検証に用いた version 4.5.0 が、開示プログラムのデルタ株比率に関する処理で同様に動いています。
よって本稿が用いた R 言語 version 4.5.0 での計算は、西浦氏の計算環境における開示プログラムの計算と一致していると考えることができます。
なお論文には、ライブラリ surveillance の version 1.20.3 を使ったとの記述があります。しかし surveillance version 1.20.3 に必要なのは R 言語本体 version 3.6.0 以降なので、surveillance の version 情報から R 言語本体の version を特定することはできません。
(付録E) 局所極小の実態
(4-2)節 の 図4.2 では、コスト関数 式(1) の断面の「局所極小」を示しました。正確に言うとこれは局所極小ではありません。
なぜなら 図4.2 の「窪み」は、単独の窪みではなく、「窪みが繋がった谷」のような形状だからです。図E.1 は、phi3 = 0.07 を固定し、phi1 と phi2 を変化させた時のコスト関数の値です。図E.1 の断面が 図4.2 です [注Ea]。(本来なら 図E.1 には12本の谷が見えるはずですが、図で個々の谷は判別しにくくなっています。)

図E.1 phi3 = 0.07 で phi1, phi2 を変化させた時のコスト関数値
一方でこれらの「谷」は、最適化計算上は無数の局所極小のように見えます。
ある初期値から開始した最適化計算は「谷」の低いところを探すのですが、この際、必ずしも大局的に低い方向ではなく、現在地で判定した下降方向に向かいます。結果的に大局的に低いところに至る場合もありますが、図E.1 のコスト関数では、谷に入ってさらに狭い谷の下方を目指すため、狭いところで「動きが取れなくなって」停止します。この停止位置は計算開始位置に強く左右されるので、異なる初期値からは、ほぼ異なる収束値に至ります。したがって実質的に無数の局所極小があるかのように見えるのです。ここでコスト関数としてどうしても 式(1) を用いる必要があるなら、最適化アルゴリズムの工夫を検討すべきでしょう。しかし「デルタ株比率の数理モデル化」に対処するために行うべきことは、コスト関数の改善だと思われます。
や
のように極端に大きな値の
が効果的かも知れません。このような
は、発散を回避するというより局所極小を埋めるためのものです。こうした
でも数式上は各白丸に近い曲線への収束が期待されるところ、別途行った確認によると、実際に有望と思われる曲線が得られています。
[注Ea] 図E.1 の方が空間の分割が粗い上、図E.1 は scipy.ndimage.gaussian_filter(sigma=1, truncate=2.0) で処理しているので、コスト関数の値には違いがあります。
更新履歴
- 2025-05-27
公開。 - 2025-08-24
(4-4)節 を追加。 - 2025-09-10
- 「(対策を)取る」という語を用いていた何ヵ所かを「採る」に修正しました。
- (3-2)節 のタイトルに「私の」を追加して誤解を招かないようにしました。


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}