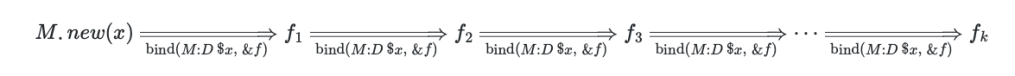Happy Pi Day! Today (3/14) we celebrate the most famous mathematical constant: π ≈ 3.141592653589793…
π is irrational and transcendental, appears in circles, waves, probability, physics, and even random walks.
Raku (with its built-in π constant, excellent rational support, lazy lists, and unicode operators) makes experimenting with π relatively easy and enjoyable.
In this blog post (notebook) we explore a selection of formulas and algorithms.
The built-in Raku constant pi (or π) is fairly low precision:
say π.fmt('%.25f')
# 3.1415926535897930000000000
One way to remedy that is to use continued fractions. For example, using the (first) sequence line of On-line Encyclopedia of Integer Sequences (OEIS) A001203 produces with precision 56:
It is interesting to consider the plotting the terms of continued fraction terms of .
First we ingest the more “pi-terms” from OEIS A001203 (20k terms):
my @ds = data-import('https://oeis.org/A001203/b001203.txt').split(/\s/)».Int.rotor(2);
my @terms = @ds».tail;
@terms.elems
# 20000
Here is the summary:
sink records-summary(@terms)
# +-------------------+
# | numerical |
# +-------------------+
# | 1st-Qu => 1 |
# | Median => 2 |
# | Min => 1 |
# | Max => 20776 |
# | Mean => 12.6809 |
# | 3rd-Qu => 5 |
# +-------------------+
Here is an array plot of the first 128 terms of the continued fraction approximating :
#% html
my @mat = |@terms.head(128)».&integer-digits(:2base);
my $max-digits = @mat».elems.max;
@mat .= map({ [|(0 xx (``max-digits - ``_.elems)), |$_] });
dot-matrix-plot(transpose(@mat), size => 10):svg
Next, we show the Pareto principle manifestation of for the continued fraction terms. First we observe that the terms a distribution similar to Benford’s law:
#% js
my @tally-pi = tally(@terms).sort(-*.value).head(16) <</>> @terms.elems;
my @terms-b = random-variate(BenfordDistribution.new(:10base), 2_000);
my @tally-b = tally(@terms-b).sort(-*.value).head(16) <</>> @terms-b.elems;
js-d3-bar-chart(
[
|@tally-pi.map({ %( x => ``_.key, y => ``_.value, group => 'π') }),
|@tally-b.map({ %( x => ``_.key, y => ``_.value, group => 'Benford') })
],
plot-label => "Pi continued fraction terms vs. Benford's law",
:$title-color,
:$background)
Here is the Pareto principle plot — ≈5% of the unique term values correspond to ≈80% of the terms:
#% js
js-d3-list-line-plot(
pareto-principle-statistic(@terms),
plot-label => "Pi continued fraction terms vs. Benford's law",
:$title-color,
:$background,
stroke-width => 5,
:grid-lines
)
3. Classic Infinite Series
Many ways to express π as an infinite sum — some converge slowly, others surprisingly fast.
In the plot above the blue segments correspond to origin terms ≤ 100, yellow segments to terms between 100 and 1000, and red segment for origin terms greater than 1000.
Give me a 5-step implementation plan for adding authentication to a FastAPI app. VERY CONCISE.
Magic cell parameter values can be assigned using the equal sign (“=”):
#%chat assistant1 > markdown
Now rewrite step 2 with test-first details.
Default chat object (NONE)
#%chat
Does vegetarian sushi exist?
# Yes, vegetarian sushi definitely exists! It's a popular option for those who avoid fish or meat. Instead of raw fish, vegetarian sushi typically includes ingredients like:
- Avocado
- Cucumber
- Carrots
- Pickled radish (takuan)
- Asparagus
- Sweet potato
- Mushrooms (like shiitake)
- Tofu or tamago (Japanese omelette)
- Seaweed salad
These ingredients are rolled in sushi rice and nori seaweed, just like traditional sushi. Vegetarian sushi can be found at many sushi restaurants and sushi bars, and it's also easy to make at home.
Gist: LLM::Functions::Chat(chat-id = assistant1, llm-evaluator.conf.name = ChatGPT, messages.elems = 6, last.message = ${:content("2. Write tests to verify user data retrieval and password verification; then define user model and fake user database accordingly."), :role("assistant"), :timestamp(DateTime.new(2026,3,14,9,23,6.901396036148071,:timezone(-14400)))})
Clear message history of one persona (keep persona)
Give me three Linux troubleshooting tips. VERY CONCISE.
Remark: In order to run the magic cell above you have to run a llamafile program/model on your computer. (For example, ./google_gemma-3-12b-it-Q4_K_M.llamafile.)
A dark-mode digital painting of a lighthouse in stormy weather.
Here we use a DALL-E meta cell to see how many images were generated in a notebook session:
#% dalle meta
elems
# 3
Here we export the second image — using the index 1 — into a file named “stormy-weather-lighthouse-2.png”:
#% dalle export, index=1
stormy-weather-lighthouse-2.png
# stormy-weather-lighthouse-2.png
Here we show all generated images:
#% dalle meta
show
Here we export all images (into file names with the prefix “cheatsheet”):
#% dalle export, index=all, prefix=cheatsheet
6) LLM provider access facilitation
API keys can be passed inline (api-key) or through environment variables.
Notebook-session environment setup
%*ENV<OPENAI_API_KEY> = "YOUR_OPENAI_KEY";
%*ENV<GEMINI_API_KEY> = "YOUR_GEMINI_KEY";
%*ENV<OLLAMA_API_KEY> = "YOUR_OLLAMA_KEY";
Ollama-specific defaults:
OLLAMA_HOST (default host fallback is http://localhost:11434)
OLLAMA_MODEL (default model if model=... not given)
The magic cells take as argument base-url. This allows to use LLMs that have ChatGPT compatible APIs. The argument base_url is a synonym of host for magic cell #%ollama.
7) Notebook/chatbook session initialization with custom code + personas JSON
Initialization runs when the extension is loaded.
A) Custom Raku init code
Env var override: RAKU_CHATBOOK_INIT_FILE
If not set, first existing file is used in this order:
~/.config/raku-chatbook/init.py
~/.config/init.raku
Use this for imports/helpers you always want in chatbook sessions.
B) Pre-load personas from JSON
Env var override: RAKU_CHATBOOK_LLM_PERSONAS_CONF
If not set, first existing file is used in this order:
~/.config/raku-chatbook/llm-personas.json
~/.config/llm-personas.json
The supported JSON shape is an array of dictionaries:
In this blog post (notebook) we calibrate the Heterogeneous Salvo Combat Model (HSCM), [MJ1, AAp1, AAp2], to the First World War Battle of Coronel, [Wk1]. Our goal is to exemplify the usage of the functionalities of the package “Math::SalvoCombatModeling”, [AAp1]. We closely follow the Section B of Chapter III of [MJ1]. The calibration data used in [MJ1] is taken from [TB1].
Remark: The implementation of the Raku package “Math::SalvoCombatModeling”, [AAp1], closely follows the implementation of the Wolfram Language (WL) paclet “SalvoCombatModeling”, [AAp2]. Since WL has (i) symbolic builtin computations and (ii) a mature notebook system the salvo models computation, representation, and study with WL is much more convenient.
Setup
Here we load the package:
use Math::SalvoCombatModeling;
use Graph;
The battle
The Battle of Coronel is a First World War naval engagement between three British ships {Good Hope, Monmouth, and Glasgow) and four German ships (Scharnhorst, Gneisenau, Leipzig, and Dresden). The battle happened on 1 November 1914, off the coast of central Chile near the city of Coronel.
The Scharnhorst and Gneisenau are the first ships to open fire at Good Hope and Monmouth; the three British ships soon afterwards return fire. Dresden and Leipzig open fire on Glasgow, driving her out of the engagement. At the end of the battle, both Good Hope and Monmouth are sunk, while Glasgow, Scharnhorst, and Gneisenau were damaged.
Ship
Duration of fire
Good Hope
0
Monmouth
0
Glasgow
15
Scharnhorst
28
Gneisenau
28
Leipzig
2
Dresden
2
The following graph shows which ship shot at which ships and total fire duration (in minutes):
#% html
my @edges =
{ from =>'Scharnhorst', to =>'Good Hope', weight => 28 },
{ from =>'Scharnhorst', to =>'Monmouth', weight => 28 },
{ from =>'Gneisenau', to =>'Good Hope', weight => 28 },
{ from =>'Gneisenau', to =>'Monmouth', weight => 28 },
{ from =>'Leipzig', to =>'Glasgow', weight => 2 },
{ from =>'Glasgow', to =>'Scharnhorst', weight => 2 },
{ from =>'Glasgow', to =>'Gneisenau', weight => 15 },
{ from =>'Glasgow', to =>'Leipzig', weight => 15 },
{ from =>'Glasgow', to =>'Dresden', weight => 15 },
{ from =>'Dresden', to =>'Glasgow', weight => 15 };
my $g = Graph.new(@edges):directed;
$g.dot(
engine => 'neato',
vertex-shape => 'ellipse',
vertex-width => 0.65,
:5size,
:8vertex-font-size,
:weights,
:6edge-font-size,
edge-thickness => 0.8,
arrow-size => 0.6
):svg;
Salvo combat modeling definitions
Before going with building the model here is table that provides definitions of the fundamental notions of salvo combat modeling:
A group of naval ships that operate and fight together.
Unit
A unit is an individual ship in a force.
Salvo
A salvo is the number of shots fired as a unit of force in a discrete period of time.
Combat Potential
Combat Potential is a force’s total stored offensive capability of an element or force measured in number of total shots available.
Combat Power
Also called Striking Power, is the maximum offensive capability of an element or force per salvo, measured in the number of hitting shots that would be achieved in the absence of degrading factors.
Scouting Effectiveness
Scouting Effectiveness is a dimensionless degradation factor applied to a force’s combat power as a result of imperfect information. It is a number between zero and one that describes the difference between the shots delivered based on perfect knowledge of enemy composition and position and shots based on existing information [Ref. 7].
Training Effectiveness
Training effectiveness is a fraction that indicates the degradation in combat power due the lack of training, motivation, or readiness.
Distraction Factor
Also called chaff effectiveness or seduction, is a multiplier that describes the effectiveness of an offensive weapon in the presence of distraction or other soft kill. This multiplier is a fraction, where one indicates no susceptibility/complete effectiveness and zero indicates complete susceptibility/no effectiveness.
Offensive Effectiveness
Offensive effectiveness is a composite term made of the product of scouting effectiveness, training effectiveness, distraction, or any other factor which represents the probability of a single salvo hitting its target. Offensive effectiveness transforms a unit’s combat potential parameter into combat power.
Defensive Potential
Defensive potential is a force’s total defensive capability measured in units of enemy hits eliminated independent of weapon system or operator accuracy or any other multiplicative factor.
Defensive Power
Defensive power is the number of missiles in an enemy salvo that a defending element or force can eliminate.
Defender Alertness
Defender alertness is the extent to which a defender fails to take proper defensive actions against enemy fire. This may be the result of any inattentiveness due to improper emission control procedures, readiness, or other similar factors. This multiplier is a fraction, where one indicates complete alertness and zero indicates no alertness.
Defensive Effectiveness
Defensive effectiveness is a composite term made of the product of training effectiveness and defender alertness. This term also applies to any value that represents the overall degradation of a force’s defensive power.
Staying Power
Staying power is the number of hits that a unit or force can absorb before being placed out of action.
Model
The British ships are in Good Hope, Monmouth, and Glasgow. They correspond to the indices 1, ,2, and 3 respectively.
["Good Hope", "Monmouth", "Glasgow"] Z=> 1..3
# (Good Hope => 1 Monmouth => 2 Glasgow => 3)
The German ships are Scharnhorst, Gneisenau, Leipzig, and Dresden:
Remark: The Battle of Coronel is modeled with a “typical” salvo model — the ships use “continuous fire.” Hence, there are no interceptors and or, in model terms, defense terms or matrices.
Here is the model (for 3 British ships and 4 German ships):
sink my $m = heterogeneous-salvo-model(['B', 3], ['G', 4]):latex;
Remove the defense matrices (i.e. make them zero):
sink $m<B><defense-matrix> = ((0 xx $m<B><defense-matrix>.head.elems).Array xx $m<B><defense-matrix>.elems).Array;
sink $m<G><defense-matrix> = ((0 xx $m<G><defense-matrix>.head.elems).Array xx $m<G><defense-matrix>.elems).Array;
Converting the obtained model data structure to LaTeX we get:
Concrete parameter values
Setting the parameter values as in [MJ1] defining the sub param (to be passed heterogeneous-salvo-model):
multi sub param(Str:D $name, Str:D $a where * eq 'B', Str:D $b where * eq 'G', UInt:D $i, UInt:D $j) { 0 }
multi sub param(Str:D $name, Str:D $a where * eq 'G', Str:D $b where * eq 'B', UInt:D $i, UInt:D $j) {
given $name {
when 'beta' {
given ($i, $j) {
when (1, 1) { 2.16 }
when (1, 2) { 2.16 }
when (1, 3) { 2.16 }
when (2, 1) { 2.16 }
when (2, 2) { 2.16 }
when (2, 3) { 2.16 }
when (3, 1) { 2.165 }
when (3, 2) { 2.165 }
when (3, 3) { 2.165 }
when (4, 1) { 2.165 }
when (4, 2) { 2.165 }
when (4, 3) { 2.165 }
}
}
when 'curlyepsilon' {
given ($i, $j) {
when (1, 1) { 0.028 }
when (1, 2) { 0.028 }
when (1, 3) { 0.028 }
when (2, 1) { 0.028 }
when (2, 2) { 0.028 }
when (2, 3) { 0.028 }
when (3, 1) { 0.012 }
when (3, 2) { 0.012 }
when (3, 3) { 0.012 }
when (4, 1) { 0.012 }
when (4, 2) { 0.012 }
when (4, 3) { 0.012 }
}
}
when 'capitalpsi' {
given ($i, $j) {
when (1, 1) { 0.5 }
when (1, 2) { 0.5 }
when (2, 1) { 0.5 }
when (2, 2) { 0.5 }
when (3, 1) { 0 }
when (3, 2) { 0 }
when (4, 1) { 0 }
when (4, 2) { 0 }
when (1, 3) { 0 }
when (2, 3) { 0 }
when (3, 3) { 1 }
when (4, 3) { 1 }
}
}
}
}
multi sub param(Str:D $name, Str:D $a where * eq 'G', UInt:D $i) { 1 }
multi sub param(Str:D $name, Str:D $a where * eq 'B', UInt:D $i) {
given $name {
when 'zeta' {
given $i {
when 1 { 1.605 }
when 2 { 1.605 }
when 3 { 1.23 }
}
}
}
}
multi sub param(Str:D $name where $name eq 'units', Str:D $a where * eq 'B', UInt:D $i) { $i }
multi sub param(Str:D $name where $name eq 'units', Str:D $a where * eq 'G', UInt:D $i) { $i }
# ¶m
Damage calculations
my $m = heterogeneous-salvo-model(['B', 3], ['G', 4], :offensive-effectiveness-terms, :¶m)
Every year on February 7th, math enthusiasts worldwide (should) consider celebrating Euler’s Day or E-day. Among Euler’s many gifts to the (currently known) mathematical universe is the ever-popular number e, the natural logarithm base that is basically the rock star of calculus, complex analysis, continuous growth models, compound interest, and (much) more. That irrational number shows up in places we might or might not expect. This blog post (notebook) explores some formulas and plots related to Euler’s number, e.
js-d3-list-line-plot(10.rand xx 40, background => 'none', stroke-width => 2)
my $title-color = 'Silver';
my $background = '#1F1F1F';
Formulas and computation
Raku has the built in mathematical constant (base of the natural logarithm). Both ASCII “e” and Unicode “𝑒” (“MATHEMATICAL ITALIC SMALL E” or U+1D452) can be used:
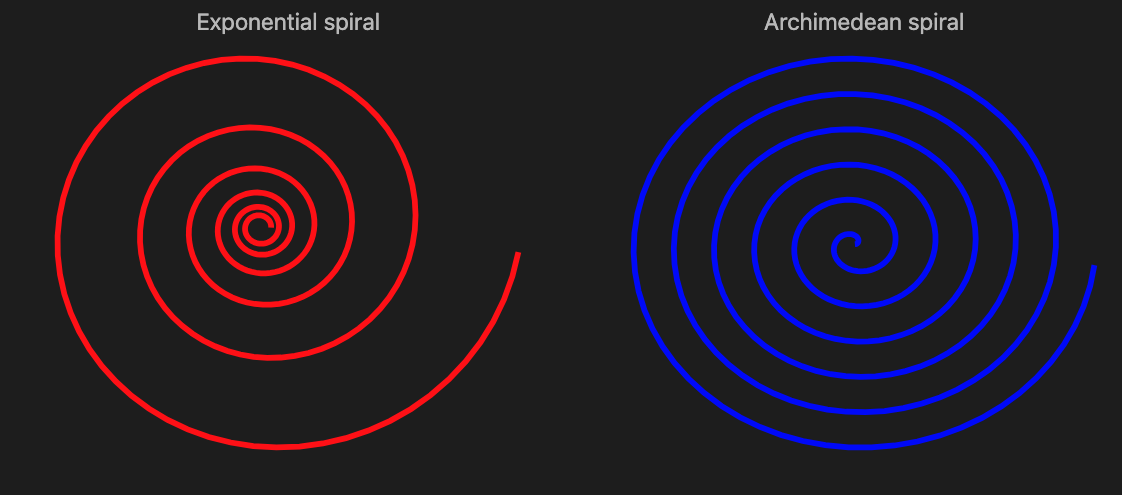
js-d3-list-line-plot(@log-spiral, :$background, color => 'red', title => 'Exponential spiral', |%opts) ~
js-d3-list-line-plot(@arch-spiral, :$background, color => 'blue', title => 'Archimedean spiral', |%opts)
Catenary is the curve a hanging flexible wire or chain assumes when supported at its ends and acted upon by a uniform gravitational force. It is given with the formula:
Here is a corresponding plot:
#% js
js-d3-list-line-plot((-1, -0.99 ... 1).map({ [$_, e ** $_ + e ** (-$_)] }), :$background, stroke-width => 4, :grid-lines, title => 'Catenary curve', :$title-color)
This document (notebook) shows transformation of movie dataset into a form more suitable for making a movie recommender system. (It builds upon Part 1 of the blog posts series.)
Remark: All three notebooks feature the same introduction, setup, and references sections in order to make it easier for readers to browse, access, or reproduce the content.
Remark: The series data files can be found in the folder “Data” of the GitHub repository “RakuForPrediction-blog”, [AAr1].
The notebook series can be used in several ways:
Just reading this introduction and then browsing the notebooks
Reading only this (data transformations) notebook in order to see how data wrangling is done
Evaluating all three notebooks in order to learn and reproduce the computational steps in them
Outline
Here are the transformation, data analysis, and machine learning steps taken in the notebook series, [AAn1, AAn2, AAn3]:
Ingest the data — Part 1
Shape size and summaries
Numerical columns transformation
Renaming columns to have more convenient names
Separating the non-uniform genres column into movie-genre associations
Into long format
Basic data analysis — Part 1
Number of movies per year distribution
Movie-genre distribution
Pareto principle adherence for movie directors
Correlation between number of votes and rating
Association Rules Learning (ARL) — Part 1
Converting long format dataset into “baskets” of genres
Most frequent combinations of genres
Implications between genres
I.e. a biography-movie is also a drama-movie 94% of the time
LLM-derived dictionary of most commonly used ARL measures
Recommender system creation — Part 2
Conversion of numerical data into categorical data
Application of one hot embedding
Experimenting / observing recommendation results
Getting familiar with the movie data by computing profiles for sets of movies
Relationships graphs — Part 3
Find the nearest neighbors for every movie in a certain range of years
Make the corresponding nearest neighbors graph
Using different weights for the different types of movie metadata
Visualize largest components
Make and visualize graphs based on different filtering criteria
Comments & observations
This notebook series started as a demonstration of making a “real life” data Recommender System (RS).
The data transformations notebook would not be needed if the data had “nice” tabular form.
Since the data have aggregated values in its “genres” column typical long form transformations have to be done.
On the other hand, the actor names per movie are not aggregated but spread-out in three columns.
Both cases represent a single movie metadata type.
For both long format transformations (or similar) are needed in order to make an RS.
After a corresponding Sparse Matrix Recommender (SMR) is made its sparse matrix can be used to do additional analysis.
Such extensions are: deriving clusters, making and visualizing graphs, making and evaluating suitable classifiers.
In most “real life” data processing most of the data transformation listed steps above are taken.
ARL can be also used for deriving recommendations if the data is large enough.
The SMR object is based on Nearest Neighbors finding over “bags of tags.”
Latent Semantic Indexing (LSI) tag-weighting functions are applied.
The data does not have movie-viewer data, hence only item-item recommenders are created and used.
One hot embedding is a common technique, which in this notebook is done via cross-tabulation.
The categorization of numerical data means putting number into suitable bins or “buckets.”
The bin or bucket boundaries can be on a regular grid or a quantile grid.
For categorized numerical data one-hot embedding matrices can be processed to increase similarity between numeric buckets that are close to each to other.
Nearest-neighbors based recommenders — like SMR — can be used as classifiers.
These are the so called K-Nearest Neighbors (KNN) classifiers.
Although the data is small (both row-wise & column-wise) we can consider making classifiers predicting IMDB ratings or number of votes.
Using the recommender matrix similarities between different movies can be computed and a corresponding graph can be made.
Centrality analysis and simulations of random walks over the graph can be made.
Like Google’s “Page-rank” algorithm.
The relationship graphs can be used to visualize the “structure” of movie dataset.
Alternatively, clustering can be used.
Hierarchical clustering might be of interest.
If the movies had reviews or summaries associated with them, then Latent Semantic Analysis (LSA) could be applied.
SMR can use both LSA-terms-based and LSA-topics-based representations of the movies.
LLMs can be used to derive the LSA representation.
Again, not done in these series of notebooks.
See, the video “Raku RAG demo”, [AAv4], for such demonstration.
Setup
Load packages used in the notebook:
use Math::SparseMatrix;
use ML::SparseMatrixRecommender;
use ML::SparseMatrixRecommender::Utilities;
use Statistics::OutlierIdentifiers;
One way to investigate (browse) the data is to make a recommender system and explore with it different aspects of the movie dataset like movie profiles and nearest neighbors similarities distribution.
Make the recommender
In order to make a more meaningful recommender we put the values of the different numerical variables into “buckets” — i.e. intervals derived corresponding to the values distribution for each variable. The boundaries of the intervals can form a regular grid, correspond to quanitile values, or be specially made. Here we use quantiles:
my @bucketVars = <score votes_count reviews_count>;
my @dsMovieDataLongForm2;
sink for @dsMovieDataLongForm.map(*<TagType>).unique -> $var {
if $var ∈ @bucketVars {
my %bucketizer = ML::SparseMatrixRecommender::Utilities::categorize-to-intervals(@dsMovieDataLongForm.grep(*<TagType> eq $var).map(*<Tag>)».Numeric, probs => (0..6) >>/>> 6, :interval-names):pairs;
@dsMovieDataLongForm2.append(@dsMovieDataLongForm.grep(*<TagType> eq $var).map(*.clone).map({ $_<Tag> = %bucketizer{$_<Tag>}; $_ }))
} else {
@dsMovieDataLongForm2.append(@dsMovieDataLongForm.grep(*<TagType> eq $var))
}
}
Here are the recommender sub-matrices dimensions (rows and columns):
.say for $smrObj.take-matrices.deepmap(*.dimensions).sort(*.key)
# actor => (5043 6256)
# country => (5043 66)
# director => (5043 2399)
# genre => (5043 26)
# language => (5043 48)
# reviews_count => (5043 7)
# score => (5043 7)
# title => (5043 4917)
# votes_count => (5043 7)
# year => (5043 92)
Note that the sub-matrices of “reviews_count”, “score”, and “votes_count” have small number of columns, corresponding to the number probabilities specified when categorizing to intervals.
Enhance with one-hot embedding
my $mat = $smrObj.take-matrices<year>;
my $matUp = Math::SparseMatrix.new(
diagonal => 1/2 xx ($mat.columns-count - 1), k => 1,
row-names => $mat.column-names,
column-names => $mat.column-names
);
my $matDown = $matUp.transpose;
# mat = mat + mat . matDown + mat . matDown
$mat = $mat.add($mat.dot($matUp)).add($mat.dot($matDown));
This document (notebook) demonstrates the functions of “Graph::RandomMaze”, [AAp1], for generating and displaying random mazes. The methodology and implementations of maze creation based on random rectangular and hexagonal grid graphs are described in detail in the blog post “Day 24 – Maze Making Using Graphs”, [AA1], and in the Wolfram notebook “Maze Making Using Graphs”, [AAn1].
This document (notebook) shows transformations of a movie dataset into a format more suitable for data analysis and for making a movie recommender system. It is the first of a three-part series of notebooks that showcase Raku packages for doing Data Science (DS). The notebook series as a whole goes through this general DS loop:
Remark: All three notebooks feature the same introduction, setup, and references sections in order to make it easier for readers to browse, access, or reproduce the content.
Remark: The series data files can be found in the folder “Data” of the GitHub repository “RakuForPrediction-blog”, [AAr1].
The notebook series can be used in several ways:
Just reading this introduction and then browsing the notebooks
Reading only this (data transformations) notebook in order to see how data wrangling is done
Evaluating all three notebooks in order to learn and reproduce the computational steps in them
Outline
Here are the transformation, data analysis, and machine learning steps taken in the notebook series, [AAn1, AAn2, AAn3]:
Ingest the data — Part 1
Shape size and summaries
Numerical columns transformation
Renaming columns to have more convenient names
Separating the non-uniform genres column into movie-genre associations
Into long format
Basic data analysis — Part 1
Number of movies per year distribution
Movie-genre distribution
Pareto principle adherence for movie directors
Correlation between number of votes and rating
Association Rules Learning (ARL) — Part 1
Converting long format dataset into “baskets” of genres
Most frequent combinations of genres
Implications between genres
I.e. a biography-movie is also a drama-movie 94% of the time
LLM-derived dictionary of most commonly used ARL measures
Recommender system creation — Part 2
Conversion of numerical data into categorical data
Application of one hot embedding
Experimenting / observing recommendation results
Getting familiar with the movie data by computing profiles for sets of movies
Relationships graphs — Part 3
Find the nearest neighbors for every movie in a certain range of years
Make the corresponding nearest neighbors graph
Using different weights for the different types of movie metadata
Visualize largest components
Make and visualize graphs based on different filtering criteria
Comments & observations
This notebook series started as a demonstration of making a “real life” data Recommender System (RS).
The data transformations notebook would not be needed if the data had “nice” tabular form.
Since the data have aggregated values in its “genres” column typical long form transformations have to be done.
On the other hand, the actor names per movie are not aggregated but spread-out in three columns.
Both cases represent a single movie metadata type.
For both long format transformations (or similar) are needed in order to make an RS.
After a corresponding Sparse Matrix Recommender (SMR) is made its sparse matrix can be used to do additional analysis.
Such extensions are: deriving clusters, making and visualizing graphs, making and evaluating suitable classifiers.
In most “real life” data processing most of the data transformation listed steps above are taken.
ARL can be also used for deriving recommendations if the data is large enough.
The SMR object is based on Nearest Neighbors finding over “bags of tags.”
Latent Semantic Indexing (LSI) tag-weighting functions are applied.
The data does not have movie-viewer data, hence only item-item recommenders are created and used.
One hot embedding is a common technique, which in this notebook is done via cross-tabulation.
The categorization of numerical data means putting number into suitable bins or “buckets.”
The bin or bucket boundaries can be on a regular grid or a quantile grid.
For categorized numerical data one-hot embedding matrices can be processed to increase similarity between numeric buckets that are close to each to other.
Nearest-neighbors based recommenders — like SMR — can be used as classifiers.
These are the so called K-Nearest Neighbors (KNN) classifiers.
Although the data is small (both row-wise & column-wise) we can consider making classifiers predicting IMDB ratings or number of votes.
Using the recommender matrix similarities between different movies can be computed and a corresponding graph can be made.
Centrality analysis and simulations of random walks over the graph can be made.
Like Google’s “Page-rank” algorithm.
The relationship graphs can be used to visualize the “structure” of movie dataset.
Alternatively, clustering can be used.
Hierarchical clustering might be of interest.
If the movies had reviews or summaries associated with them, then Latent Semantic Analysis (LSA) could be applied.
SMR can use both LSA-terms-based and LSA-topics-based representations of the movies.
LLMs can be used to derive the LSA representation.
Again, not done in these series of notebooks.
See, the video “Raku RAG demo”, [AAv4], for such demonstration.
Setup
Load packages used in the notebook:
use Math::SparseMatrix;
use ML::SparseMatrixRecommender;
use ML::SparseMatrixRecommender::Utilities;
use Statistics::OutlierIdentifiers;
my $title-color = 'Silver';
my $stroke-color = 'SlateGray';
my $tooltip-color = 'LightBlue';
my $tooltip-background-color = 'none';
my $tick-labels-font-size = 10;
my $tick-labels-color = 'Silver';
my $tick-labels-font-family = 'Helvetica';
my $background = 'White'; #'#1F1F1F';
my $color-scheme = 'schemeTableau10';
my $color-palette = 'Inferno';
my $edge-thickness = 3;
my $vertex-size = 6;
my $mmd-theme = q:to/END/;
%%{
init: {
'theme': 'forest',
'themeVariables': {
'lineColor': 'Ivory'
}
}
}%%
END
my %force = collision => {iterations => 0, radius => 10},link => {distance => 180};
my %force2 = charge => {strength => -30, iterations => 4}, collision => {radius => 50, iterations => 4}, link => {distance => 30};
sink my %opts = :$background, :$title-color, :$edge-thickness, :$vertex-size;
Ingest data
Ingest the movie data:
# Download and unzip: https://github.com/antononcube/RakuForPrediction-blog/raw/refs/heads/main/Data/movie_data.csv.zip
my $fileName=$*HOME ~ '/Downloads/movie_data.csv';
my @dsMovieData=data-import($fileName, headers=>'auto');
deduce-type(@dsMovieData)
#% html
@dsMovieGenreLongForm.head(8)
==> to-html(field-names => <Item TagType Tag>)
Item
TagType
Tag
0
genre
Action
0
genre
Adventure
0
genre
Fantasy
0
genre
Sci-Fi
1
genre
Action
1
genre
Adventure
1
genre
Fantasy
2
genre
Action
Statistics
In this section we compute different statistics that should give us better idea what the data is.
Show movie years distribution:
#% js
js-d3-bar-chart(@dsMovieData.map(*<title_year>.Str).&tally.sort(*.head), title => 'Movie years distribution', :$title-color, :1200width, :$background)
~
js-d3-box-whisker-chart(@dsMovieData.map(*<title_year>)».Int.grep(*>1916), :horizontal, :$background)
Show movie genre distribution:
#% js
my %genreCounts = cross-tabulate(@dsMovieGenreLongForm, 'Item', 'Tag', :sparse).column-sums(:p);
js-d3-bar-chart(%genreCounts.sort, title => 'Genre distributions', :$background, :$title-color)
Check Pareto principle adherence for director names:
#% js
pareto-principle-statistic(@dsMovieData.map(*<director_name>))
==> js-d3-list-line-plot(
:$background,
title => 'Pareto principle adherence for movie directors',
y-label => 'probability', x-label => 'index',
:grid-lines, :5stroke-width, :$title-color)
Plot the number of IMDB votes vs IMBDB scores:
#% js
@dsMovieData.map({ %( x => $_<num_voted_users>».Num».log(10), y => $_<imdb_score>».Num ) })
==> js-d3-list-plot(
:$background,
title => 'Number of IMBD votes vs IMDB scores',
x-label => 'Number of votes, lg', y-label => 'score',
:grid-lines, point-size => 4, :$title-color)
Association rules learning
It is interesting to see which genres associated closely with each other. One way to find to those associations is to use Association Rule Learning (ARL).
For each movie make a “basket” of genres:
my @baskets = cross-tabulate(@dsMovieGenreLongForm, 'Item', 'Tag').values».keys».List;
@baskets».elems.&tally
Here is a table showing the formulas for the Association Rules Learning measures (confidence, lift, leverage, conviction), along with their minimum value, maximum value, and value of indifference:
Explanation of terms:
support(X) = P(X), the proportion of transactions containing itemset X.
¬A = complement of A (transactions not containing A).
Value of indifference generally means the value where the measure indicates independence or no association.
For Confidence, the baseline is support(B) (probability of B alone).
For Lift and Conviction, 1 indicates no association.
Leverage’s minimum and maximum depend on the supports of A and B.
LLM prompt
Here is the prompt used to generate the ARL metrics dictionary table above:
Give the formulas for the Association Rules Learning measures: confidence, lift, leverage, and conviction. In a Markdown table for each measure give the min value, max value, value of indifference. Make sure the formulas are in LaTeX code.
Export transformed data
Here we export the transformed data in order to streamline the computations in the other notebooks of the series:
That effort requires to verify that the Monad laws apply to certain constructs of the Raku language. This document (notebook) defines the Monad laws and provides several verifications for different combinations of operators and coding styles.
This document (notebook) focuses on built-in Raku features that can be used in monadic programming. It does not cover Raku packages that enhance Raku’s functionality or syntax for monadic programming. Also, since Raku is a feature-rich language, not all approaches to making monadic pipelines are considered — only the main and obvious ones. (I.e. the ones I consider “main and obvious.”)
The examples in this document are very basic. Useful, more complex (yet, elegant) examples of monadic pipelines usage in Raku are given in the notebook “Monadic programming examples”, [AAn1].
Context
Before going further, let us list the applications of monadic programming we consider:
Graceful failure handling
Rapid specification of computational workflows
Algebraic structure of written code
Remark: Those applications are discussed in [AAv5] (and its future Raku version.)
As a tools maker for Data Science (DS) and Machine Learning (ML), I am very interested in Point 1; but as a “simple data scientist” I am mostly interested in Point 2.
That said, a large part of my Raku programming has been dedicated to rapid and reliable code generation for DS and ML by leveraging the algebraic structure of corresponding software monads — i.e. Point 3. (See [AAv2, AAv3, AAv4].) For me, first and foremost, monadic programming pipelines are just convenient interfaces to computational workflows. Often I make software packages that allow “easy”, linear workflows that can have very involved computational steps and multiple tuning options.
Dictionary
Monadic programming A method for organizing computations as a series of steps, where each step generates a value along with additional information about the computation, such as possible failures, non-determinism, or side effects. See [Wk1].
Monadic pipeline Chaining of operations with a certain syntax. Monad laws apply loosely (or strongly) to that chaining.
Uniform Function Call Syntax (UFCS) A feature that allows both free functions and member functions to be called using the same object.function() method call syntax.
Method-like call Same as UFCS. A Raku example: [3, 4, 5].&f1.$f2.
Verifications overview
Raku — as expected — has multiple built-in mechanisms for doing monadic programming. A few of those mechanisms are “immediate”, other require adherence to certain coding styles or very direct and simple definitions. Not all of the Monad law verifications have to be known (or understood) by a programmer. Here is a table that summarizes them:
Type
Description
Array and ==>
Most immediate, clear-cut
&unit and &bind
Definitions according to the Monad laws; programmable semicolon
Any and andthen
General, built-in monad!
Styled OOP
Standard and straightforward
The verification for each approach is given as an array of hashmaps with keys “name”, “input”, “expected”. The values of “input” are strings which are evaluated with the lines:
use MONKEY-SEE-NO-EVAL;
@tbl .= map({ $_<output> = EVAL($_<input>); $_ });
EVAL is used in order to have easily verifiable “single origin of truth.”
The HTML verification tables are obtained withe function proof-table, which has several formatting options. (Set the section “Setup”.)
What is a monad? (informally)
Many programmers are familiar with monadic pipelines, although, they might know them under different names. This section has monadic pipeline examples from Unix, R, and Raku that should help understanding the more formal definitions in the next section.
Unix examples
Most (old and/or Raku) programmers are familiar with Unix programming. Hence, they are familiar with monadic pipelines.
Pipeline (|)
The Unix pipeline semantics and syntax was invented and introduced soon after the first Unix release. Monadic pipelines (or uniform function call) have very similar motivation and syntax.
Here is an example of Unix pipeline in which the output of one shell program is the input for the next:
# Fri Dec 13 07:59:16 EST 2024
# Tue Dec 24 14:24:20 EST 2024
# Sat Dec 14 07:57:41 EST 2024
That UNIX command:
Finds in the current directory all files with names that finish with “nb”
Picks from the list produces by 1 only the rows that contain the string “chebyshev”
Gives the dates of modification of those files
Reverse-Polish calculator (dc)
One of the oldest surviving Unix language programs is dc (desktop calculator) that uses reverse-Polish notation. Here is an example of the command 3 5 + 4 * p given to dc that prints out 32, i.e. (3 + 5) * 4:
#% bash
echo '3 5 + 4 * p' | dc
# 32
We can see that dc command as a pipeline:
The numbers are functions that place the corresponding values in the context (which is a stack)
The space between the symbols is the pipeline constructor
Data wrangling
Posit‘s constellation of R packages “tidyverse” facilitates pipeline construction of data wrangling workflows. Here is an example in which columns of the data frame dfTitanic are renamed, then its rows are filtered and grouped, and finally, the corresponding group sizes are shown:
dfTitanic %>%
dplyr::rename(age = passengerAge, sex = passengerSex, class = passengerClass) %>%
dplyr::filter(age > 10) %>%
dplyr::group_by(class, sex) %>%
dplyr::count()
Here is a corresponding Raku pipeline andthen style (using subs of “Data::Reshapers”, [AAp5]):
In this document a monad is any set of a symbol $m$ and two operators unit and bind that adhere to the monad laws. (See the next sub-section.) The definition is taken from [Wk1] and [PW1] and phrased in Raku terms. In order to be brief, we deliberately do not consider the equivalent monad definition based on unit, join, and map (also given in [PW1].)
Here are operators for a monad associated with a certain class M:
monad unit function is unit(x) = M.new(x)
monad bind function is a rule like bind(M:D $x, &f) = &f(x) with &f($x) ~~ M:D giving True.
Note that:
the function bind unwraps the content of M and gives it to the function &f;
the functions given as second arguments to bind (see&f) are responsible to return as results instances of the monad class M.
Here is an illustration formula showing a monad pipeline:
From the definition and formula it should be clear that if for the result f(x) of bind the test f(x) ~~ M:D is True then the result is ready to be fed to the next binding operation in monad’s pipeline. Also, it is easy to program the pipeline functionality with reduce:
reduce(&bind, M.new(3), [&f1, &f2, $f3])
The monad laws
The monad laws definitions are taken from [H1] and [H3].In the monad laws given below “⟹” is for monad’s binding operation and x↦expr is for a function in anonymous form.
Here is a table with the laws:
name
LHS
RHS
Left identity
unit m ⟹ f
f m
Right identity
m ⟹ unit
m
Associativity
(m ⟹ f) ⟹ g
m ⟹ (x ⟼ f x ⟹ g)
Setup
Here we load packages for tabulating the verification results:
use Data::Translators;
use Hilite::Simple;
Here is a sub that is used to tabulate the Monad laws proofs:
#| Tabulates Monad laws verification elements.
sink sub proof-table(
@tbl is copy, #= Array of hashmaps with keys <name input expected>
Bool:D :$raku = True, #= Whether .raku be invoked in the columns "output" and "expected"
Bool:D :$html = True, #= Whether to return HTML table
Bool:D :$highlight = True #= Whether to highlight the Raku code in the HTML table
) {
if $raku {
@tbl .= map({ $_<output> = $_<output>.raku; $_});
@tbl .= map({ $_<expected> = $_<expected>.raku; $_});
}
return @tbl unless $html;
my @field-names = <name input output expected>;
my $res = to-html(@tbl, :@field-names, align => 'left');
if $highlight {
$res = reduce( {$^a.subst($^b.trans([ '<', '>', '&' ] => [ '<', '>', '&' ]), $^b.&hilite)}, $res, |@tbl.map(*<input>) );
$res = $res.subst('<pre class="nohighlights">', :g).subst('</pre>', :g)
}
return $res;
}
Array and ==>
The monad laws are satisfied in Raku for:
Every function f that takes an array argument and returns an array
The unit operation being Array
The feed operator (==>) being the binding operation
Name
Input
Output
Left identity
Array($a) ==> &f()
&f($a)
Right identity
$a ==> { Array($_) }()
$a
Associativity LHS
Array($a) ==> &f1() ==> &f2()
&f2(&f1($a))
Associativity RHS
Array($a) ==> { &f($_) ==> &f2() }()
&f2(&f1($a))
Here is an example:
#% html
# Operators in the monad space
my &f = { Array($_) >>~>> '_0' }
my &f1 = { Array($_) >>~>> '_1' }
my &f2 = { Array($_) >>~>> '_2' }
# Some object
my $a = 5; #[3, 4, 'p'];
# Verification table
my @tbl =
{ name => 'Left identity', :input( 'Array($a) ==> &f()' ), :expected( &f($a) )},
{ name => 'Right identity', :input( '$a ==> { Array($_) }()' ), :expected( $a )},
{ name => 'Associativity LHS', :input( 'Array($a) ==> &f1() ==> &f2()' ), :expected( &f2(&f1($a)) )},
{ name => 'Associativity RHS', :input( 'Array($a) ==> { &f1($_) ==> &f2() }()' ), :expected( &f2(&f1($a)) )}
;
use MONKEY-SEE-NO-EVAL;
@tbl .= map({ $_<output> = EVAL($_<input>); $_ });
@tbl ==> proof-table(:html, :raku, :highlight)
name
input
output
expected
Left identity
Array($a) ==>&f()
$[“5_0”]
$[“5_0”]
Right identity
$a==> { Array($_) }()
$[5]
5
Associativity LHS
Array($a) ==>&f1() ==>&f2()
$[“5_1_2”]
$[“5_1_2”]
Associativity RHS
Array($a) ==> { &f1($_) ==>&f2() }()
$[“5_1_2”]
$[“5_1_2”]
Remark: In order to keep the verification simple I did not want to extend it to cover Positional and Seq objects. In some sense, that is also covered by Any and andthen verification. (See below.)
&unit and &bind
From the formal Monad definition we can define the corresponding functions &unit and &bind and verify the Monad laws with them:
#% html
# Monad operators
my &unit = { Array($_) };
my &bind = { $^b($^a) };
# Operators in the monad space
my &f = { Array($_) >>~>> '_0' }
my &f1 = { Array($_) >>~>> '_1' }
my &f2 = { Array($_) >>~>> '_2' }
# Some object
my $a = (3, 4, 'p');
# Verification table
my @tbl =
{ name => 'Left identity', :input( '&bind( &unit($a), &f)' ), :expected( &f($a) )},
{ name => 'Right identity', :input( '&bind( $a, &unit)' ), :expected( $a )},
{ name => 'Associativity LHS', :input( '&bind( &bind( &unit($a), &f1), &f2)' ), :expected( &f2(&f1($a)) )},
{ name => 'Associativity RHS', :input( '&bind( &unit($a), { &bind(&f1($_), &f2) })' ), :expected( &f2(&f1($a)) )}
;
use MONKEY-SEE-NO-EVAL;
@tbl .= map({ $_<output> = EVAL($_<input>); $_ });
@tbl ==> proof-table(:html, :raku, :highlight)
name
input
output
expected
Left identity
&bind( &unit($a),&f)
$[“3_0”, “4_0”, “p_0”]
$[“3_0”, “4_0”, “p_0”]
Right identity
&bind( $a,&unit)
$[3, 4, “p”]
$(3, 4, “p”)
Associativity LHS
&bind( &bind( &unit($a),&f1),&f2)
$[“3_1_2”, “4_1_2”, “p_1_2”]
$[“3_1_2”, “4_1_2”, “p_1_2”]
Associativity RHS
&bind( &unit($a), { &bind(&f1($_),&f2) })
$[“3_1_2”, “4_1_2”, “p_1_2”]
$[“3_1_2”, “4_1_2”, “p_1_2”]
To achieve the “monadic pipeline look and feel” with &unit and &bind, certain infix definitions must be implemented. For example, infix<:»> ($m, &f) { &bind($m, &f) }. Here is a full verification example:
The andthen operator returns Empty if the first argument is undefined, otherwise the last argument. The last argument is returned as-is, without being checked for definedness at all. Short-circuits. The result of the left side is bound to $_ for the right side, or passed as arguments if the right side is a Callable, whose count must be 0 or 1.
A main feature andthen is to return Empty if its first argument is not defined. That is, actually, very “monadic” — graceful handling of errors is one of the main reasons of use Monadic programming. It is also limiting, because the monad failure is “just” Empty. That is mostly a theoretical limitation; in practice Raku has many other elements, like, notandthen and orelse, that can shape the workflows to programmer’s desires.
The Monad laws hold for Any.new as the unit operation and andthen as the binding operation.
#% html
# Operators in the monad space
my &f = { Array($_) >>~>> '_0' }
my &f1 = { Array($_) >>~>> '_1' }
my &f2 = { Array($_) >>~>> '_2' }
# Some object
my $a = (3, 9, 'p');
# Verification table
my @tbl =
{ name => 'Left identity', :input( '$a andthen .&f' ), :expected( &f($a) )},
{ name => 'Right identity', :input( '$a andthen $_' ), :expected( $a )},
{ name => 'Associativity LHS', :input( '$a andthen .&f1 andthen .&f2' ), :expected( &f1(&f2($a)) )},
{ name => 'Associativity RHS', :input( '$a andthen { .&f1 andthen .&f2 }' ), :expected( &f1(&f2($a)) )}
;
use MONKEY-SEE-NO-EVAL;
@tbl .= map({ $_<output> = EVAL($_<input>); $_ });
@tbl ==> proof-table(:html, :raku, :highlight)
name
input
output
expected
Left identity
$aandthen .&f
$[“3_0”, “9_0”, “p_0”]
$[“3_0”, “9_0”, “p_0”]
Right identity
$aandthen$_
$(3, 9, “p”)
$(3, 9, “p”)
Associativity LHS
$aandthen .&f1andthen .&f2
$[“3_1_2”, “9_1_2”, “p_1_2”]
$[“3_2_1”, “9_2_1”, “p_2_1”]
Associativity RHS
$aandthen { .&f1andthen .&f2 }
$[“3_1_2”, “9_1_2”, “p_1_2”]
$[“3_2_1”, “9_2_1”, “p_2_1”]
Monad class and method call
Raku naturally supports method chaining using dot notation (.) for actual methods defined on a class or type. Hence, a more “standard” way for doing Monadic programming is to use a monad class, say M, and method call:
M.new(...) plays the monad unit role — i.e. it uplifts objects into monad’s space
$m.f(...) (where $m ~~ M:D) plays the binding role if all methods of M return M:D objects
The axioms verification needs to be done using a particular class definition format (see the example below):
1. Left identity applies:
M.new($x).f does mean application of M.f to $x.
2. Right identity applies by using M.new
3. Associativity axiom holds
For RHS, again, method-like call (call as method) is used.
Here is an example:
#% html
# Monad class definition
my class M {
has $.context;
multi method new($context) { self.bless(:$context) }
multi method new(M:D $m) { self.bless(context => $m.context) }
method f() { $!context = $!context >>~>> '_0'; self}
method f1() { $!context = $!context >>~>> '_1'; self}
method f2() { $!context = $!context >>~>> '_2'; self}
}
# Some object
my $a = 5; #[5, 3, 7];
# Verification table
my @tbl =
{ name => 'Left identity', :input( 'M.new($a).f' ), :expected( M.new($a).f )},
{ name => 'Right identity', :input( 'my M:D $x .= new($a)' ), :expected( M.new($a) )},
{ name => 'Associativity LHS', :input( '(M.new($a).f1).f2' ), :expected( (M.new($a).f1).f2 )},
{ name => 'Associativity RHS', :input( 'M.new($a).&{ $_.f1.f2 }' ), :expected( M.new($a).&{ $_.f1.f2 } )}
;
use MONKEY-SEE-NO-EVAL;
@tbl .= map({ $_<output> = EVAL($_<input>); $_ });
@tbl ==> proof-table(:html, :raku, :highlight)
name
input
output
expected
Left identity
M.new($a).f
M.new(context => “5_0”)
M.new(context => “5_0”)
Right identity
my M:D $x.=new($a)
M.new(context => 5)
M.new(context => 5)
Associativity LHS
(M.new($a).f1).f2
M.new(context => “5_1_2”)
M.new(context => “5_1_2”)
Associativity RHS
M.new($a).&{ $_.f1.f2 }
M.new(context => “5_1_2”)
M.new(context => “5_1_2”)
Method-like calls
Instead of M methods f<i>(...) we can have corresponding functions &f<i>(...) and “method-like call” chains:
M.new(3).&f1.&f2.&f3
That is a manifestation of Raku’s principle “everything is an object.” Here is an example:
Remark A simpler version of the code above is: [6, 3, 12].elems.sqrt.&{ $_ ** 3 }.
Conclusion
It is encouraging — both readability-wise and usability-wise — that Raku code can be put into easy to read and understand pipeline-like computational steps. Raku supports that in its Functional Programming (FP) and Object-Oriented Programming (OOP) paradigms. The support can be also seen from these programming-idiomatic and design-architectural points of view:
Any computation via:
andthen and ==>
Method-like calls or UFCS
For special functions and (gradually typed) arguments via:
sub and infix
OOP
Caveats
There are a few caveats to be kept in mind when using andthen and ==> (in Raku’s language version “6.d”.)
does it run?
andthen
==>
no
(^100).pick xx 5 andthen .List andthen { say "max {$_.max}"; $_} andthen $_».&is-prime
(^100).pick xx 5 ==> {.List} ==> { say "max {$_.max}"; $_} ==> { $_».&is-prime }
yes
(^100).pick xx 5 andthen .List andthen { say "max {$_.max}"; $_}($_) andthen $_».&is-prime
(^100).pick xx 5 ==> {.List}() ==> { say "max {$_.max}"; $_}() ==> { $_».&is-prime }()
[SH2] Sheng Liang, Paul Hudak, Mark Jones, “Monad transformers and modular interpreters”, (1995), Proceedings of the 22nd ACM SIGPLAN-SIGACT symposium on Principles of programming languages. New York, NY: ACM. pp. 333–343. doi:10.1145/199448.199528.
[PW1] Philip Wadler, “The essence of functional programming”, (1992), 19’th Annual Symposium on Principles of Programming Languages, Albuquerque, New Mexico, January 1992.
“LLM::Functions” supports high level LLM function calling via llm-synthesize and llm-synthesize-with-tools. (The latter provides more options for the tool invocation process like max-iterations or overriding tool specs.)
At this point “LLM::Functions” supports function calling in the styles of OpenAI’s ChatGPT and Google’s Gemini. If the LLM configuration is not set with the names “ChatGPT” or “Gemini”, then the function calling style used is that of ChatGPT. (Many LLM providers — other than OpenAI and Gemini — tend to adhere to OpenAI’s API.)
Remark: LLM “function calling” is also known as LLM “tools” or “LLM tool invocation.”
In this document, non-trivial Stoichiometry computations are done with the Raku package “Chemistry::Stoichiometry”, [AAp4]. Related plots are done with the Raku package “JavaScript::D3”, [AAp6].
Big picture
Inversion of control is a way to characterize LLM function calling. This means the LLM invokes functions or subroutines that operate on an external system, such as a local computer, rather than within the LLM provider’s environment. See the section “Outline of the overall process” of “LLM function calling workflows (Part 1, OpenAI)”, [AA1].
Remark: The following Software Framework building principles (or mnemonic slogans) apply to LLM function calling:
“Don’t call us, we’ll call you.” (The Hollywood Principle)
“Leave the driving to us.” (Greyhound Lines, Inc.)
The whole series
This document is the fourth of the LLM function calling series, [AA1 ÷ AA4]. The other three show lower-level LLM function calling workflows.
Define package functions as tools Show how to define LLM-tools
Stoichiometry by LLM Invoking LLM requests with LLM tools
“Thoughtful” response Elaborated LLM answer based in LLM tools results
Adding plot tools Enhancing the LLM answers with D3.js plots
Setup
Load packages:
use JSON::Fast;
use LLM::Functions;
use LLM::Tooling;
use Chemistry::Stoichiometry;
use JavaScript::D3;
Define LLM access configurations:
sink my $conf41-mini = llm-configuration('ChatGPT', model => 'gpt-4.1-mini', :8192max-tokens, temperature => 0.4);
sink my $conf-gemini-flash = llm-configuration('Gemini', model => 'gemini-2.0-flash', :8192max-tokens, temperature => 0.4);
The package “Chemistry::Stoichiometry”, [AAp4], provides element data, a grammar (or parser) for chemical formulas, and subs for computing molecular masses and balancing equations. Here is an example of calling molecular-mass:
molecular-mass("SO2")
# 64.058
Balance chemical equation:
'Al + O2 -> Al2O3'
==> balance-chemical-equation
# [4*Al + 3*O2 -> 2*Al2O3]
Define package functions as tools
Define a few tools based in chemistry computations subs:
sink my @tools =
LLM::Tool.new(&molecular-mass),
LLM::Tool.new(&balance-chemical-equation)
;
Undefined type of parameter ⎡$spec⎦; continue assuming it is a string.
Make an LLM configuration with the LLM-tools:
sink my $conf = llm-configuration($conf41-mini, :@tools);
Remark: When llm-synthesize is given LLM configurations with LLM tools, it hands over the process to llm-synthesize-with-tools. This function then begins the LLM-tool interaction loop.
Stoichiometry by LLM
Here is a prompt requesting to compute molecular masses and to balance a certain chemical equation:
sink my $input = "What are the masses of SO2, O3, and C2H5OH? Also balance: C2H5OH + O2 = H2O + CO2."
The LLM invocation and result:
llm-synthesize(
[$input, llm-prompt('NothingElse')('JSON')],
e => $conf,
form => sub-parser('JSON'):drop)
Remark: It order to see the LLM-tool interaction use the Boolean option (adverb) :echo of llm-synthesize.
“Thoughtful” response
Here is a very informative, “thoughtful” response for a quantitative Chemistry question:
#% markdown
my $input = "How many molecules a kilogram of water has? Use LaTeX for the formulas. (If any.)";
llm-synthesize($input, e => $conf)
==> { .subst(/'\[' | '\]'/, '$$', :g).subst(/'\(' | '\)'/, '$', :g) }() # Make sure LaTeX code has proper fences
Adding plot tools
It would be interesting (or fancy) to add a plotting tool. We can use text-list-plot of “Text::Plot”, [AAp5], or js-d3-list-plot of “JavaScript::D3”, [AAp6]. For both, the automatically derived tool specs — via the sub llm-tool-definition used by LLM::Tool — are somewhat incomplete. Here is the auto-result for js-d3-list-plot:
{
"function": {
"strict": true,
"parameters": {
"additionalProperties": false,
"required": [
"$data",
""
],
"type": "object",
"properties": {
"$data": {
"description": "",
"type": "string"
},
"": {
"description": "",
"type": "string"
}
}
},
"type": "function",
"name": "js-d3-list-plot",
"description": "Makes a list plot (scatter plot) for a list of numbers or a list of x-y coordinates."
},
"type": "function"
}
The automatic tool-spec for js-d3-list-plot can be replaced with this spec:
my $spec = q:to/END/;
{
"type": "function",
"function": {
"name": "jd-d3-list-plot",
"description": "Creates D3.js code for a list-plot of the given arguments.",
"parameters": {
"type": "object",
"properties": {
"$x": {
"type": "array",
"description": "A list of a list of x-coordinates or x-labels",
"items": {
"anyOf": [
{ "type": "string" },
{ "type": "number" }
]
}
}
"$y": {
"type": "array",
"description": "A list of y-coordinates",
"items": {
"type": "number"
}
}
},
"required": ["$x", "$y"]
}
}
}
END
my $t = LLM::Tool.new(&text-list-plot);
$t.json-spec = $spec;
Though, it is easier and more robust to define a new function that delegates to js-d3-list-plot — or other plotting function — and does some additional input processing that anticipates LLM derived argument values:
#| Make a string that represents a list-plot of the given arguments.
my sub data-plot(
Str:D $x, #= A list of comma separated x-coordinates or x-labels
Str:D $y, #= A list of comma separated y-coordinates
Str:D :$x-label = '', #= Label of the x-axis
Str:D :$y-label = '', #= Label of the y-axis
Str:D :$title = '', #= Plot title
) {
my @x = $x.split(/<[\[\],"]>/, :skip-empty)».trim.grep(*.chars);
my @y = $y.split(/<[\[\],"]>/, :skip-empty)».trim».Num;
my @points = (@x Z @y).map({ %( variable => $_.head, value => $_.tail ) });
js-d3-bar-chart(@points, :$x-label, :$y-label, title-color => 'Gray', background => '#1F1F1F', :grid-lines)
}
Here we add the new tool to the tool list above:
sink my @tool-objects =
LLM::Tool.new(&molecular-mass),
LLM::Tool.new(&balance-chemical-equation),
LLM::Tool.new(&data-plot);
Here we make an LLM request for chemical molecules masses calculation and corresponding plotting — note that require to obtain a dictionary of the masses and plot:
my $input = q:to/END/;
What are the masses of SO2, O3, Mg2, and C2H5OH?
Make a plot the obtained quantities: x-axes for the molecules, y-axis for the masses.
The plot has to have appropriate title and axes labels.
Return a JSON dictionary with keys "masses" and "plot".
END
# LLM configuration with tools
my $conf = llm-configuration($conf41-mini, tools => @tool-objects);
# LLM invocation
my $res = llm-synthesize([
$input,
llm-prompt('NothingElse')('JSON')
],
e => $conf,
form => sub-parser('JSON'):drop
);
# Type/structure of the result
deduce-type($res)
sink my %rules =
poet1 => "Write a short poem about summer.",
poet2 => "Write a haiku about winter.",
poet3 => sub ($topic, $style) {
"Write a poem about $topic in the $style style."
},
poet4 => {
llm-function => {llm-synthesize('You are a famous Russian poet. Write a short poem about playing bears.')},
test-function => -> $with-russian { $with-russian ~~ Bool:D && $with-russian || $with-russian.Str.lc ∈ <true yes> }
},
judge => sub ($poet1, $poet2, $poet3, $poet4) {
[
"Choose the composition you think is best among these:\n\n",
"1) Poem1: $poet1",
"2) Poem2: $poet2",
"3) Poem3: {$poet4.defined && $poet4 ?? $poet4 !! $poet3}",
"and copy it:"
].join("\n\n")
},
report => {
eval-function => sub ($poet1, $poet2, $poet3, $poet4, $judge) {
[
'# Best poem',
'Three poems were submitted. Here are the statistics:',
to-html( ['poet1', 'poet2', $poet4.defined && $poet4 ?? 'poet4' !! 'poet3'].map({ [ name => $_, |text-stats(::('$' ~ $_))] })».Hash.Array, field-names => <name chars words lines> ),
'## Judgement',
$judge
].join("\n\n")
}
}
;
Remark: This is a documentation example — I want to be seen that $poet4 can be undefined. That hints that the corresponding sub is not always evaluated. (Because of the result of the corresponding test function.)
Make the graph:
my $gBestPoem = LLM::Graph.new(%rules)
Now. to make the execution quicker, we assign the poems (instead of LLM generating them):
# Poet 1
my $poet1 = q:to/END/;
Golden rays through skies so blue,
Whispers warm in morning dew.
Laughter dances on the breeze,
Summer sings through rustling trees.
Fields of green and oceans wide,
Endless days where dreams abide.
Sunset paints the world anew,
Summer’s heart in every hue.
END
# Poet 2
my $poet2 = q:to/END/;
Silent snowflakes fall,
Blanketing the earth in white,
Winter’s breath is still.
END
# Poet 3
my $poet3 = q:to/END/;
There once was a game on the ice,
Where players would skate fast and slice,
With sticks in their hands,
They’d score on the stands,
Making hockey fans cheer twice as nice!
END
# Poet 4
sink my $poet4 = q:to/END/;
В лесу играют медведи —
Смех разносится в тиши,
Тяжело шагают твердо,
Но в душе — мальчишки.
Плюшевые лапы сильны,
Игривы глаза блестят,
В мире грёз, как в сказке дивной,
Детство сердце охраняет.
END
sink my $judge = q:to/END/;
The 3rd one.
END
Graph evaluation
Evaluate the LLM graph with input arguments and intermediate nodes results: