This article was discussed on Hacker News, and was cited in The Mathematical Gazette.
Introduction
This is a follow-up to a post from earlier this year discussing the likelihood of encountering two identical packs of Skittles, that is, two packs having exactly the same number of candies of each flavor. Under some reasonable assumptions, it was estimated that we should expect to have to inspect “only about 400-500 packs” on average until encountering a first duplicate. This is interesting, because as described in that earlier post, there are millions of different possible packs– or even if we discount those that are much less likely to occur (like, say, a pack of nothing but red Skittles), then there are still hundreds of thousands of different “likely” packs that we might expect to encounter.
So, on 12 January of this year, I started buying boxes of packs of Skittles. This past week, “only” 82 days, 13 boxes, 468 packs, and 27,740 individual Skittles later, I found the following identical 2.17-ounce packs:

Test procedure
I purchased all of the 2.17-ounce packs of Skittles for this experiment from Amazon in boxes of 36 packs each. From 12 January through 4 April, I worked my way through 13 boxes, for a total of 468 packs, at the approximate rate of six packs per day. This was enough to feel like I was making progress each day, but not enough to become annoying or risk clerical errors. For each six-pack recording session, I did the following:
- Take a pack from the box, open it, and empty and sort the contents onto a blank sheet of paper.
- Take a photo of the contents of the pack.
- Record, with pen and paper, the number of Skittles of each color in the pack (more on this later).
- Empty the Skittles into a bowl.
- Repeat steps 1-4; after six packs, save and review the photos, recording the color counts to file, verifying against the paper record from step 3, and checking for duplication of a previously recorded pack.
The photos captured all of the contents of each pack, including any small flakes and chips of flavored coating that were easy to disregard… but also larger “chunks” of misshapen paste that were often only partially coated or not at all, that required some criteria up front to determine whether or how to count. For this experiment, my threshold for counting a chunk was answering “Yes” to all three of (a) is it greater than half the size of a “normal” Skittle, (b) is it completely coated with a single clearly identifiable flavor color, and (c) is it not gross, that is, would I be willing to eat it? Any “No” answer resulted in recording that pack as containing “uncounted” material, such as the pack shown below.

Example of a Skittles pack recorded with 15 green candies and an “uncounted” chunk.
The entire data set is available here as well as on GitHub. The following figure shows the photos of all 468 packs (the originals are 1024×768 pixels each), with the found pair of identical packs circled in red.

All 468 packs of Skittles, arranged top to bottom, in columns left to right. Each pair of columns corresponds to a box of 36 packs. The two identical packs are circled in red.
But… why?
So, what’s the point? Why bother with nearly three months of effort to collect this data? One easy answer is that I simply found it interesting. But I think a better answer is that this seemed like a great opportunity to demonstrate the predictive power of mathematics. A few months ago, we did some calculations on a cocktail napkin, so to speak, predicting that we should be able to find a pair of identical packs of Skittles with a reasonably– and perhaps surprisingly– small amount of effort. Actually seeing that effort through to the finish line can be a vivid demonstration for students of this predictive power of what might otherwise be viewed as “merely abstract” and not concretely useful mathematics.
(As an aside, I think the fact that this particular concrete application happens to be recreational, or even downright frivolous, is beside the point. For one thing, recreational mathematics is fun. But perhaps more importantly, there are useful, non-recreational, “real-world” applications of the same underlying mathematics. Cryptography is one such example application; this experiment is really just a birthday attack in slightly more complicated form.)
Assumptions and predictions
For completeness, let’s review the approach discussed in the previous post for estimating the number of packs we need to inspect to find a duplicate. We assume that the color of each individual Skittle is independently and uniformly distributed among the  possible flavors (strawberry, orange, lemon, green apple, and grape). We further assume that the total number
possible flavors (strawberry, orange, lemon, green apple, and grape). We further assume that the total number  of Skittles in a pack is independently distributed with density
of Skittles in a pack is independently distributed with density  , where we guessed at based on similar past studies.
, where we guessed at based on similar past studies.
We use generating functions to compute the probability  that two particular randomly selected packs of Skittles would be identical, where
that two particular randomly selected packs of Skittles would be identical, where

^2)^d](https://s0.wp.com/latex.php?latex=p%28n%2Cd%29+%3D+%5Cfrac%7B1%7D%7Bd%5E%7B2n%7D%7D%5B%5Cfrac%7Bx%5E%7B2n%7D%7D%7B%28n%21%29%5E2%7D%5D%28%5Csum%5Climits_%7Bk%3D0%7D%5En+%28%5Cfrac%7Bx%5Ek%7D%7Bk%21%7D%29%5E2%29%5Ed+&bg=ffffff&fg=333333&s=2&c=20201002)
Given this, a reasonable approximation of the expected number of packs we need to inspect until encountering a first duplicate is  , or about 400-500 packs depending on our assumption for the pack size density .
, or about 400-500 packs depending on our assumption for the pack size density .
Observations
The most common and controversial question asked about Skittles seems to be whether all five flavors are indeed uniformly distributed, or whether some flavors are more common than others. The following figure shows the distribution observed in this sample of 468 packs.
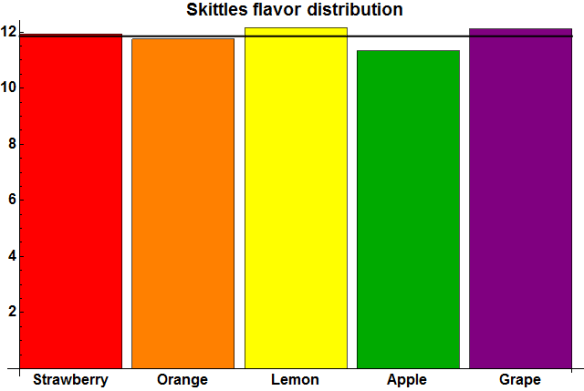
Average number of Skittles of each flavor in a pack. The assumed uniform average of 11.8547 Skittles of each color is shown by the black line.
Somewhat unfortunately, this data set potentially adds fuel to the frequent accusation that the yellow Skittles dominate. However, I leave it to an interested reader to consider and analyze whether this departure from uniformity is significant.
How accurate was our prior assumed distribution for the total number of Skittles in each pack? The following figure shows the observed distribution from this sample of 468 packs, with the mean of 59.2735 Skittles per pack shown in red.

Histogram of total number of Skittles in each pack. The mean of 59.2735 is shown in red.
Although our prior assumed average of 60 Skittles per pack was reasonable, there is strong evidence against our assumption of independence from one pack to the next, as shown in the following figure. The x-axis indicates the pack number from 1 to 468, and the y-axis indicates the number of Skittles in the pack, either total (in black) or of each individual color. The vertical grid lines show the grouping of 36 packs per box.
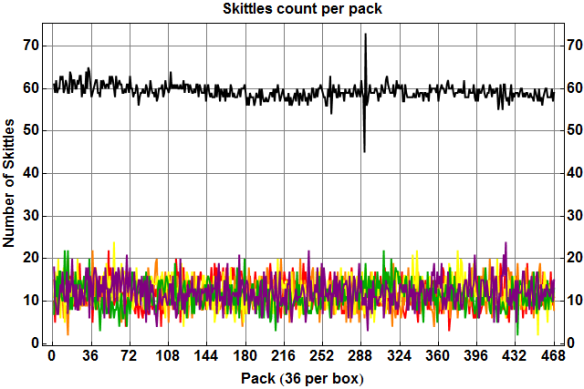
Number of Skittles per pack (total and of each color) vs. pack number.
The colored curves at bottom really just indicate the frequency and extent of outliers for the individual flavors; for example, we can see that every color appeared on at least 2 and at most 24 Skittles in every pack. The most interesting aspect of this figure, though, is the consecutive spikes in total number of Skittles shown by the black curve, with the minimum of 45 Skittles in pack #291 immediately followed by the maximum of 73 Skittles in pack #292. (See this past analysis of a single box of 36 packs that shows similar behavior.) This suggests that the dispenser that fills each pack targets an amortized rate of weight or perhaps volume, got jammed somehow resulting in an underfilled pack, and in getting “unjammed” overfilled the subsequent pack.
This is admittedly just speculation; note, for example, that the 36 packs in each box are relatively free to shift around, and I made only a modest effort to pull packs from each box in a consistent “top to bottom, front to back” order as I recorded them. So although each group of 36 packs in this data set definitely come from the same box, the order of packs within each group of 36 does not necessarily correspond to the order in which the packs were filled at the factory.
At any rate, if the objective of this experiment were to obtain a representative “truly random” sample of packs of Skittles, then the above behavior suggests that buying these 36-pack boxes in bulk is probably not recommended.
Stopping rule
Finally, one additional caveat: fortunately the primary objective of this experiment was not to obtain a “truly random” sample, but only to confirm the predicted “ease” with which we could find a pair of identical packs of Skittles. However, suppose that we did want to use this data set as a “truly random” sample… and further suppose that we could eliminate the practical imperfections suggested above, so that each pack was indeed a theoretically perfect, independent random sample.
Then even in this clean room thought experiment, we still have a problem: by stopping our sampling procedure upon encountering a duplicate, we have biased the distribution of possible resulting sample data sets! This can perhaps be most clearly seen with a simpler setup that allows an analytical solution: suppose that each pack contains just  Skittles, and each individual Skittle is independently equally likely to be one of just
Skittles, and each individual Skittle is independently equally likely to be one of just  possible colors, red or green. If we collect any fixed number of sample packs, then we should expect to observe an “all-red” pack with two red Skittles exactly 1/4 of the time. But if we instead collect sample packs until we observe a first duplicate, and then count the fraction that are all red, the expected value of this fraction is slightly less than 1/4 (181/768, to be exact). That is, by stopping with a duplicate, we are less likely to even get a chance to observe the more rare all-red (or all-green) packs.
possible colors, red or green. If we collect any fixed number of sample packs, then we should expect to observe an “all-red” pack with two red Skittles exactly 1/4 of the time. But if we instead collect sample packs until we observe a first duplicate, and then count the fraction that are all red, the expected value of this fraction is slightly less than 1/4 (181/768, to be exact). That is, by stopping with a duplicate, we are less likely to even get a chance to observe the more rare all-red (or all-green) packs.
It’s an interesting problem to quantify the extent of this effect (which I suspect is vanishingly small) with actual packs of Skittles, where the numbers of candies are larger, and the probabilities of those “extreme” compositions such as all reds is so small as to be effectively zero.




 .
. with the high 26 bits of
with the high 26 bits of  .
. , yielding a value in the range
, yielding a value in the range ![[0, 1-2^{-53}]](https://s0.wp.com/latex.php?latex=%5B0%2C+1-2%5E%7B-53%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. random draws from any of the sequences indexed by the
random draws from any of the sequences indexed by the  possible single-word seeds.
possible single-word seeds. .
. sides, the number
sides, the number  of equally likely ways to roll a score
of equally likely ways to roll a score 


 .
. of the dice, then we can group the
of the dice, then we can group the  desired outcomes with score
desired outcomes with score  among the
among the  largest dice that we keep,
largest dice that we keep, of kept dice that are strictly greater than
of kept dice that are strictly greater than  of discarded dice that are strictly less than
of discarded dice that are strictly less than 

 , or about 0.367879.
, or about 0.367879. ranks and
ranks and ![\frac{1}{(r s)!} \sum\limits_{j=0}^n (-1)^j {n \choose j} j!(r s-2j)! [x^j]g(x)^r](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%28r+s%29%21%7D+%5Csum%5Climits_%7Bj%3D0%7D%5En+%28-1%29%5Ej+%7Bn+%5Cchoose+j%7D+j%21%28r+s-2j%29%21+%5Bx%5Ej%5Dg%28x%29%5Er+&bg=ffffff&fg=333333&s=2&c=20201002)


 ; or for the probability of either player winning all of the tricks, divide by
; or for the probability of either player winning all of the tricks, divide by  .)
.) ranks and
ranks and 

 possible five-card poker hands, what hand ranks higher than exactly half of them?
possible five-card poker hands, what hand ranks higher than exactly half of them? ties with hand
ties with hand  ” on the set of possible hands?
” on the set of possible hands? and the leap second count
and the leap second count  in the almanac, the suggested formula for the “absolute” number of weeks
in the almanac, the suggested formula for the “absolute” number of weeks  since GPS epoch is given by
since GPS epoch is given by

 is essentially an estimate of the week number obtained by a linear fit against the historical rate of introduction of leap seconds.
is essentially an estimate of the week number obtained by a linear fit against the historical rate of introduction of leap seconds.

 be the number of bottles in each pack, where each bottle has a label chosen independently and uniformly from
be the number of bottles in each pack, where each bottle has a label chosen independently and uniformly from  possible states, and let
possible states, and let  be the random variable indicating the number of packs we must buy until we first collect at least one of every state label. What is the distribution of
be the random variable indicating the number of packs we must buy until we first collect at least one of every state label. What is the distribution of 
![E[X_1] = -\sum\limits_{k=1}^s (-1)^k {s \choose k} \frac{1}{1-(1-k/s)^m}](https://s0.wp.com/latex.php?latex=E%5BX_1%5D+%3D+-%5Csum%5Climits_%7Bk%3D1%7D%5Es+%28-1%29%5Ek+%7Bs+%5Cchoose+k%7D+%5Cfrac%7B1%7D%7B1-%281-k%2Fs%29%5Em%7D+&bg=ffffff&fg=333333&s=2&c=20201002)
 to indicate the number of packs that we must buy to collect
to indicate the number of packs that we must buy to collect ![P(X_d \leq n) = \frac{1}{s^{mn}} [\frac{x^{mn}}{{mn}!}][(e^x - \sum\limits_{k=0}^{d-1} \frac{x^k}{k!})^s]](https://s0.wp.com/latex.php?latex=P%28X_d+%5Cleq+n%29+%3D+%5Cfrac%7B1%7D%7Bs%5E%7Bmn%7D%7D+%5B%5Cfrac%7Bx%5E%7Bmn%7D%7D%7B%7Bmn%7D%21%7D%5D%5B%28e%5Ex+-+%5Csum%5Climits_%7Bk%3D0%7D%5E%7Bd-1%7D+%5Cfrac%7Bx%5Ek%7D%7Bk%21%7D%29%5Es%5D+&bg=ffffff&fg=333333&s=2&c=20201002)
 yields a probability of less than 0.008 that we will lose money in our search for five complete sets of labels. We can bound the possible amount lost by stopping at 144 six-packs, no matter what, and collecting $100 gift cards for however many complete sets of bottle labels we have managed to collect at that point. The figure below shows the resulting distribution of possible net returns, with the expected return of $167.53 shown in red.
yields a probability of less than 0.008 that we will lose money in our search for five complete sets of labels. We can bound the possible amount lost by stopping at 144 six-packs, no matter what, and collecting $100 gift cards for however many complete sets of bottle labels we have managed to collect at that point. The figure below shows the resulting distribution of possible net returns, with the expected return of $167.53 shown in red.
