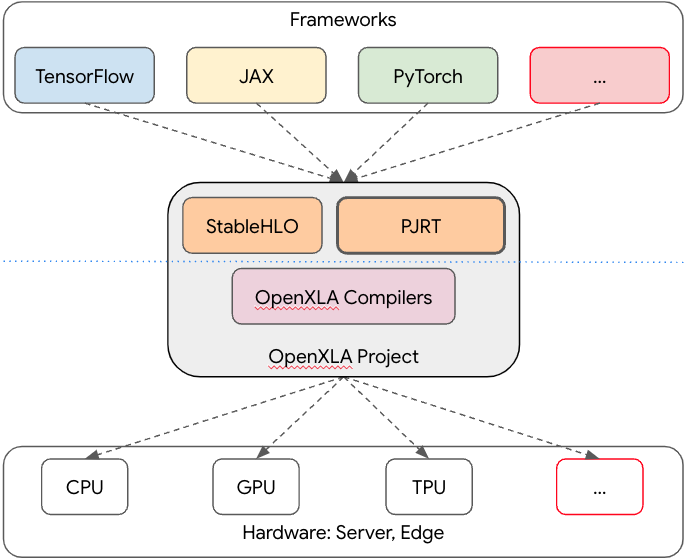
In November 2020, we launched our Open Source MPW Shuttle Program to make it easier for researchers and developers to build custom silicon and to enable a thriving ecosystem around open source hardware. Working with our partner, SkyWater Technology, we released the first foundry-supported open source process design kit (PDK) for their 130nm mixed-signal CMOS technology (SKY130), then welcomed GlobalFoundries as a partner with the release of an open source PDK for their 180nm MCU process (GF180MCU).
Then, to give researchers and developers a way to validate and prove their designs made with the PDKs, we partnered with Efabless to fund a series of no-cost manufacturing shuttles for open source designs. In support of this program, Efabless released an end-to-end RTL to GDS design stack called OpenLane that is open source, freely available, and fully supported by their manufacturing platform. OpenLane is now being maintained as part of the OpenROAD Project. When combined with open source PDKs, a design’s verification results can now be freely shared and easily replicated by other researchers and developers, which has enabled a new collaborative model to evaluate and iterate on ideas.
 |
| Pictures of a full wafer from the first SKY130 shuttle, a tray of bare dies, and a project bring-up from SKY130 MPW-2. |
Results
The Open Source MPW Shuttle Program has been a success and we’re excited by the growth we’ve seen in this ecosystem. Since its inception, the program has launched eight shuttle runs on SKY130 and an initial test run on GF180MCU, the last of which are being packaged now. With 40 slots per shuttle, we’ve manufactured 360 designs out of over 600 submissions from 19 countries around the world.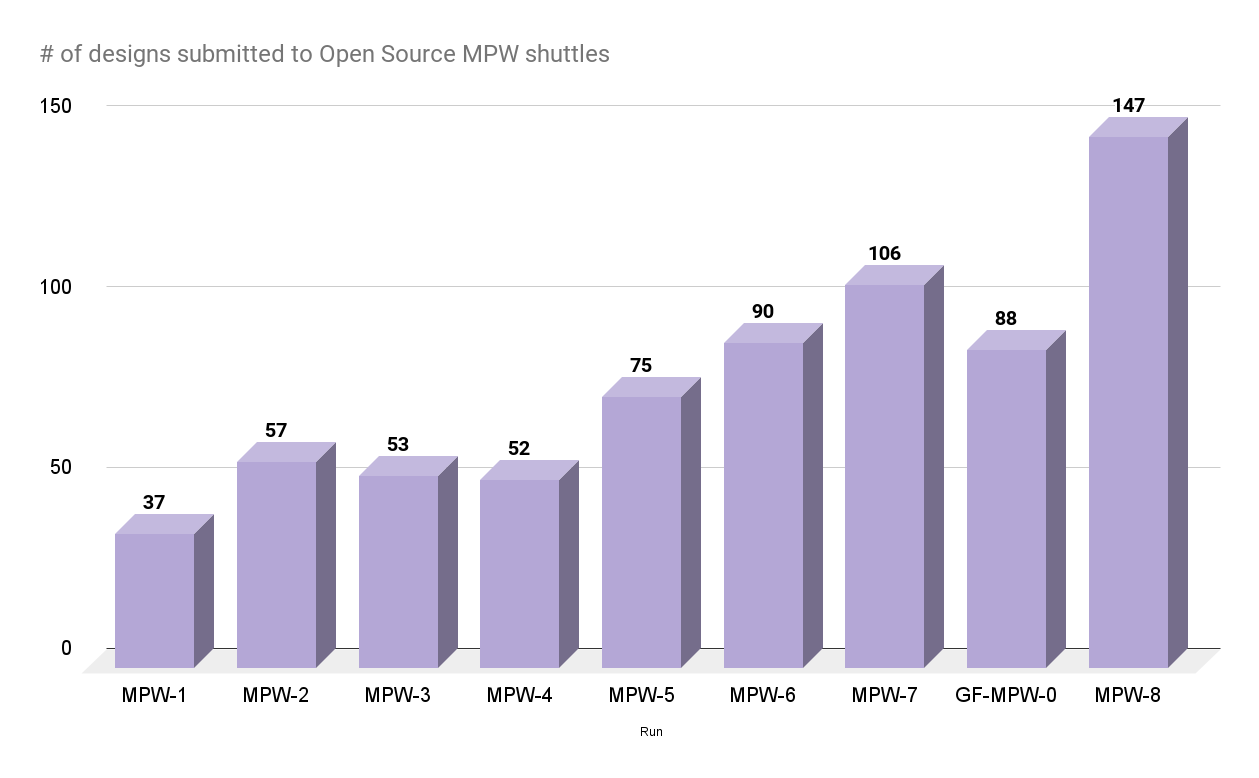
The program has also fostered collaboration between the open source community and Google. We’ve learned valuable lessons from designers who participated in the program giving feedback and filing hundreds of bugs and pull requests. These have helped to improve each successive run and to make the platforms and tools more feature-complete.
Elsewhere in the ecosystem, we’re excited by the release of new open source PDKs from foundries like the 130nm BiCMOS process from IHP, the SOI-CMOS PDK from Minimal Fab, and also by the publication of new semiconductor research using open source PDKs. Multiple universities have incorporated open source PDKs into their curriculum, and last year, NIST adopted the SKY130 PDK to migrate their existing planarized wafer designs for nanotechnology research.
Announcing GF180MCU MPW-1
We’ve just launched a new MPW-1 shuttle for GF180MCU in our partnership with Efabless. Submissions will be accepted until December 11th, targeting delivery in early 2024.

Next Steps
The open source silicon ecosystem is continuing to grow and evolve. After GF180 MPW-1 concludes, the open source SKY130 and GF180MCU PDKs will be joining the Linux Foundation’s CHIPS Alliance under a new working group to foster continued open source PDK development, and we expect future PDK releases will join as well. This will help with the transition to a broader governance model that enables more participation by industry, academia and the community, opening the possibility for larger shuttle programs with multiple sponsors as the ecosystem continues to grow.
Low-cost manufacturing options will continue to be available through this transition, both through commercial shuttle offerings like Efabless’ ChipIgnite program and also through educational efforts like TinyTapeout.
Thank you
Lastly, we’d like to thank the open source community. Your feedback has been invaluable to the success so far, and has helped to improve the tools and documentation to be more user-friendly. We have also seen contributions from the community in the form of hundreds of new and fully manufacturable designs, which have helped to expand the range and capabilities of open source hardware available to the community. We look forward to continuing partnerships to build a thriving ecosystem around open source silicon.
By Aaron Cunningham – Technical Program Manager, Core Hardware Tools