
轻量也能“想”:Youtu-LLM 开源,1.96B 参数模型解锁原生智能体能力!
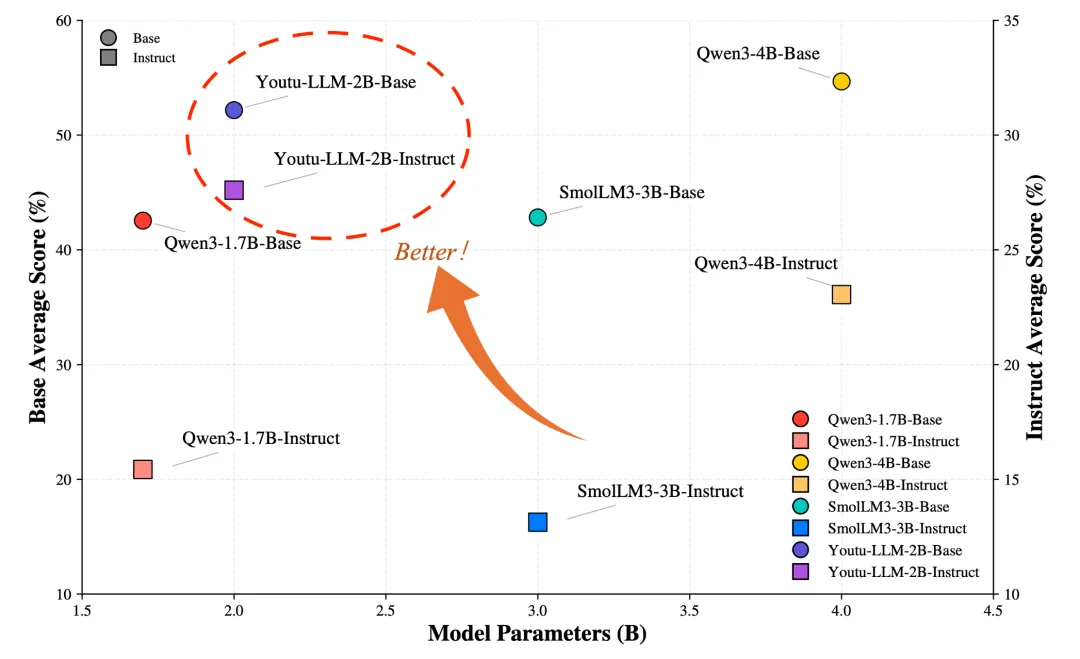
在当前大模型动辄数十亿、数百亿参数的“军备竞赛”中,轻量级模型常被视为“能力有限”的代名词。然而,腾讯 Youtu 团队最新开源的 Youtu-LLM(1.96B)却打破了这一偏见:它在参数不到 2B 的前提下,不仅在通用能力上媲美 4B 级别模型,更在智能体(Agentic)任务中大幅超越同规模甚至更大模型,首次系统验证了轻量模型也能拥有强大的“原生智能体能力”。它不依赖 “蒸馏”(模仿大尺寸模型),而是从零开始预训练,通过创新的训练范式和架构设计,专门培养推理、规划等核心能力,适合资源有限的场景(比如设备端部署)。
Youtu-LLM不仅在通用任务上媲美4B参数的主流模型,更在代码调试、深度研究、数学推理等复杂智能代理(agentic)任务中实现超越。
今天,我们就来深入解读这个“小而强”的新星模型。
研究背景-为什么需要“轻量智能体”?
当前主流智能体(Agent)系统多依赖外部框架(如 ReAct、AutoGen)与大模型配合,通过多轮交互“模拟”规划、反思、工具调用等行为。但这种方式存在响应慢、链路长、成本高等问题,尤其不适合端侧部署或高并发场景。
现有轻量级模型(通常指7B参数以下)普遍存在三大痛点:
一是依赖蒸馏或指令微调,仅能模仿大模型的输出行为,缺乏底层认知能力;
二是鲁棒性不足,面对长文本、复杂推理时容易出现逻辑断裂;
三是缺乏真正的智能代理能力,无法自主规划任务、执行操作并根据反馈调整策略。
Youtu-LLM 的核心理念是:让模型自身“具备智能体能力”,而非依赖外部框架。通过从预训练阶段就注入“智能体思维范式”,模型可以内化规划(plan)、执行(action)、反思(reflection)等能力,实现“轻量但原生智能”。
三大关键技术突破
🔧 1. 紧凑架构 + 128K 长上下文
- 采用 Dense MLA(Multi-Latent Attention) 架构,在保持推理效率的同时提升注意力表达能力;

- 支持 128K 上下文窗口,为长程智能体任务(如复杂代码修复、多跳研究)提供强大状态追踪能力;

- 专为 STEM 设计的 128K 词表,在数学、代码等专业领域 token 压缩率提升 10%,显著优化推理效率。
📚 2. “常识 → STEM → 智能体”三阶段预训练课程
Youtu-LLM 并非简单蒸馏而来,而是 从零预训练,并通过精心设计的课程学习路径逐步提升能力:
- 常识阶段:打牢语言与世界知识基础;
- STEM 聚焦阶段:大量注入数学、物理、编程等高质量专业语料;
- 通用训练和长上下文扩展:将上下文长度从8K扩展到128K,并继续融入高质量数据,让模型获得稳定的长文理解和处理能力。
- 智能体中训阶段(Agentic Mid-Training):引入 200B tokens 的智能体轨迹数据,覆盖数学推理、代码修复、深度研究、工具调用等场景。
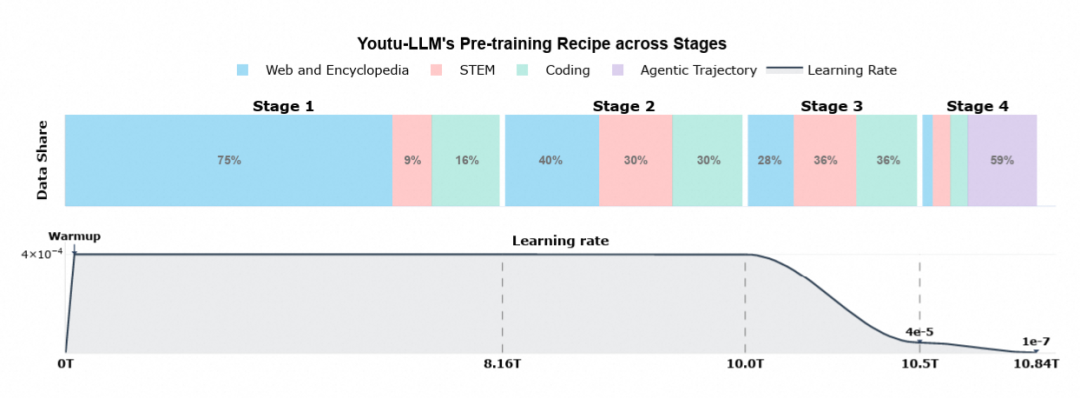
这一路径受教育心理学“螺旋式课程”启发,确保模型不仅“知道答案”,更“知道如何思考”。
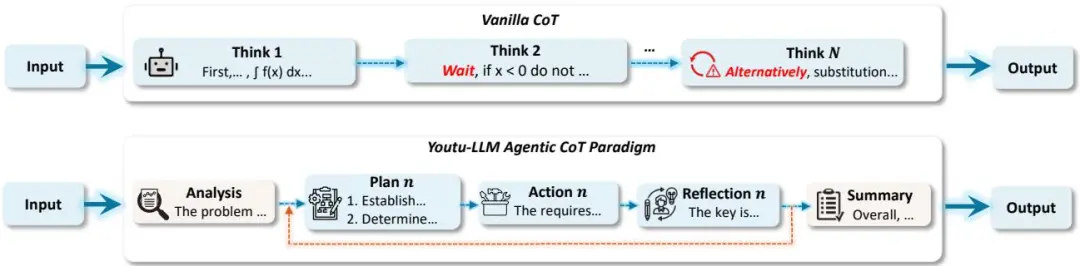
🧠 3. 可扩展的智能体轨迹合成框架
Youtu-LLM 的核心数据资产是一套高质量、结构化、可验证的智能体轨迹数据,包括:
- Agentic-CoT:将传统 CoT 拆解为 分析 → 规划 → 执行 → 反思 → 总结 五阶段,形成“有纪律的思考”;
- 数学轨迹:基于 11 项原子能力(如符号识别、建模转换、自省)构建,覆盖 K12 到竞赛级问题;
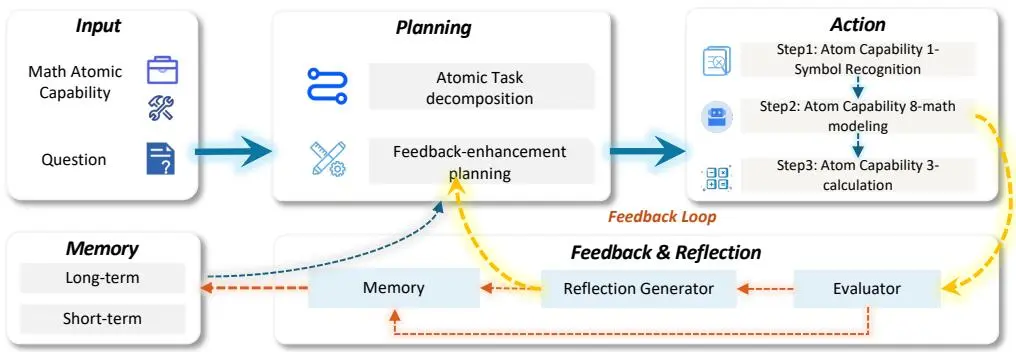
- 代码轨迹:结合成功/失败路径分支策略,有效复用错误轨迹,提升模型容错与修复能力;
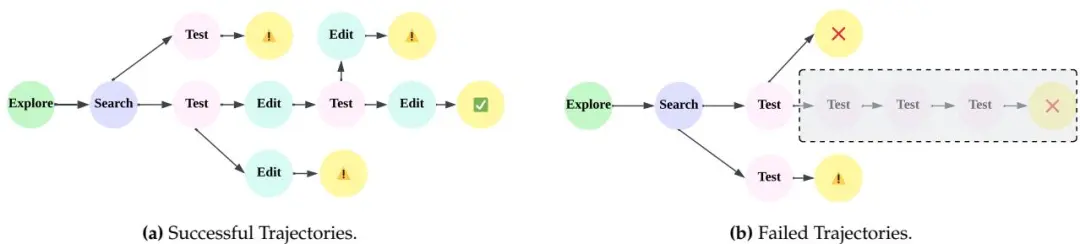
- 深度研究(Deep Research)轨迹:包含多跳问答与研究报告生成,支持“向前探索 + 向后重构”双路径合成;

- 工具调用轨迹:覆盖通用 API、MCP 协议等,强化模型与环境的动态交互能力。
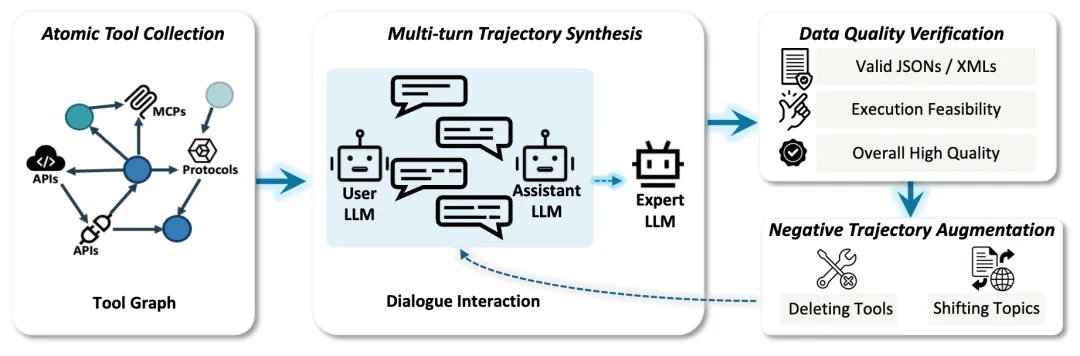
这些轨迹不仅用于训练,更形成了可评估的 APT-Bench 智能体能力基准。
性能表现:小模型,大超越
在多项权威基准上,Youtu-LLM 表现惊艳:
- 通用能力:在 MMLU-Pro、GSM8K、HumanEval 等基准上,全面超越 Qwen3-1.7B、SmolLM3-3B,接近 Qwen3-4B 水平;
- 智能体能力:在 APT-Bench 上,数学子项达 68.0%(vs Qwen3-4B 为 70.5%);在 GAIA、SWE-Bench-Verified 等真实智能体任务中,显著领先同规模模型,甚至超越 8B 蒸馏模型。

例如,在 SWE-Bench-Verified(真实 GitHub 修复任务)上,Youtu-LLM 的解决率达 17.7%,比未经过智能体中训的基线提升 42.7%!
开源信息
Youtu-LLM 已全面开源,欢迎开发者体验与贡献:
GitHub:https://github.com/TencentCloudADP/youtu-tip/blob/master/youtu-llm
ModelScope:https://modelscope.cn/collections/Tencent-YouTu-Research/Youtu-LLM
项目主页:https://youtu-tip.com/#llm
Paper:https://www.modelscope.cn/papers/2512.24618
模型支持 Base 与 Instruct 版本,并提供了GGUF版本,并提供 thinking / non-thinking 双模式,开发者可通过控制 token 切换单步回答与显式推理。
使用 ms-swift 微调
ms-swift支持了对 Youtu-LLM 的微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。ms-swift开源地址:https://github.com/modelscope/ms-swift
在开始微调之前,请确保您的环境已准备妥当。
pip install "transformers>=4.56.0"
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .自定义数据集格式如下,并在命令行中设置`--dataset train.jsonl --val_dataset val.jsonl`,验证集为可选。
{"messages": [{"role": "system", "content": "<system>"}, {"role": "user", "content": "<query1>"}, {"role": "assistant", "content": "<response1>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}以下提供可直接运行的微调脚本,显存占用2 * 5GiB:
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 \
swift sft \
--model Tencent-YouTu-Research/Youtu-LLM-2B \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--load_from_cache_file true \
--split_dataset_ratio 0.01 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_checkpointing true \
--gradient_accumulation_steps 1 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataset_num_proc 4 \
--model_author swift \
--model_name swift-robot \
--deepspeed zero3 \
--dataloader_num_workers 4训练结束后,我们使用以下脚本进行推理:
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
CUDA_VISIBLE_DEVICES=0,1 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048推送模型到ModelScope:
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'结语
Youtu-LLM 证明了:智能体能力并非大参数量模型的专利。通过从数据、架构到训练范式的系统性创新,轻量模型同样可以“会思考、能规划、懂工具”。
在成本敏感、部署受限的场景中,Youtu-LLM 为开发者提供了一个 高效、原生、可落地的智能体基座。未来,团队还将探索世界模型、多模态扩展与推理加速,持续推动“小模型大智能”的边界。
轻量,但能“想”——这才是下一代智能体的正确打开方式。
点击即可跳转模型链接
https://modelscope.cn/collections/Tencent-YouTu-Research/Youtu-LLM

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献863条内容
已为社区贡献863条内容

所有评论(0)