
The Ford circles, introduced by L. R. Ford in his 1938 paper (Reference 1), are a family of circles that are all tangent to the 


![C[p,q]](https://s0.wp.com/latex.php?latex=C%5Bp%2Cq%5D&bg=ffffff&fg=333333&s=0&c=20201002)


Plotting these circles reveals how special they are:

No two of the circles intersect at each other at two distinct points. More interestingly, we can characterize which circles are tangent to each other!
Theorem (Section 1 of Ford (1938)). Two Ford circles
are tangent to each other if and only if
.
The Ford circles are related to many different ideas in mathematics; I’ll just mention some of the properties I found interesting.
Theorem (Theorem 3 & 4 of Ford (1938)). If
, where
takes on all integral values. In particular, across all possible values of
, exactly two have denominators numerically smaller than
, and these correspond to the two tangent circles that are larger than
.
Consider the inequality

Dirichlet showed that:
- If
is irrational, then the inequality is satisfied by infinitely many fractions
, and
- If
is.
Ford used Ford circles to improve the result for irrational
Theorem (Theorem 5 of Ford (1938)). If
, then for each irrational
. However, if
, then there are irrationals
Ford circles are intimately connected with the Farey sequence: see References 1 & 3 for example.

Finally, the sum of the areas of the Ford circles involves the Riemann zeta function 
Theorem (Wikipedia). Let
be the total area of the Ford circles
. Then
.
References:
- L. R. Ford (1938). Fractions.
- Wikipedia. Ford circle.
- ThatsMaths. Ford Circles & Farey Series.

 gets increasingly fine as
gets increasingly fine as  , and
, and  is a standard Wiener process (Brownian motion).
is a standard Wiener process (Brownian motion). that satisfy the following two assumptions (let’s call them the “Itô integral assumptions”):
that satisfy the following two assumptions (let’s call them the “Itô integral assumptions”): with probability 1 for every
with probability 1 for every  , and
, and![\displaystyle\int_0^t \mathbb{E}[X_s^2] ds < \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cint_0%5Et+%5Cmathbb%7BE%7D%5BX_s%5E2%5D+ds+%3C+%5Cinfty&bg=ffffff&fg=333333&s=0&c=20201002) . Then
. Then![\begin{aligned} \mathbb{E}\left[ \int_0^t X_s dW_s \right] = 0. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5Cleft%5B+%5Cint_0%5Et+X_s+dW_s+%5Cright%5D+%3D+0.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 is differentiable in
is differentiable in  and twice differentiable in
and twice differentiable in 
 of the form
of the form
 and
and  are non-anticipating processes satisfying the Itô integral assumptions and
are non-anticipating processes satisfying the Itô integral assumptions and  is a constant.
is a constant. be as above and let
be as above and let  be a non-anticipating process. Then
be a non-anticipating process. Then

 and
and  satisfy the appropriate properties so the integrals exist.
satisfy the appropriate properties so the integrals exist.
 . Then
. Then![\begin{aligned} \mathbb{E} \left[ \left( \int_0^t Z_s dW_s \right)^2 \right] = \mathbb{E} \left[ \int_0^t Z_s^2 ds \right]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D+%5Cleft%5B+%5Cleft%28+%5Cint_0%5Et+Z_s+dW_s+%5Cright%29%5E2+%5Cright%5D%C2%A0+%3D+%5Cmathbb%7BE%7D+%5Cleft%5B+%5Cint_0%5Et+Z_s%5E2+ds+%5Cright%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 and
and  be independent random draws from the uniform distribution on
be independent random draws from the uniform distribution on ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. to the nearest integer. What is the probability that this integer is even?
to the nearest integer. What is the probability that this integer is even? while the answer to part (b) involves
while the answer to part (b) involves  ! More precisely, the answers are
! More precisely, the answers are  and
and  (natural log).
(natural log). pairs as points on the
pairs as points on the ![[0,1] \times [0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+%5Ctimes+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) square. Let’s solve (a) first. We want to find the areas of this square which correspond to
square. Let’s solve (a) first. We want to find the areas of this square which correspond to  lead to
lead to 


 and
and  , which corresponds to the second red triangle below:
, which corresponds to the second red triangle below: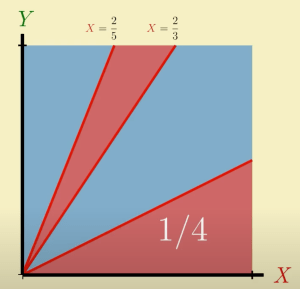
 , and so has area
, and so has area  .
.





 (several proofs, one
(several proofs, one  .
. be a function such that both
be a function such that both  are continuous in
are continuous in  -plane, including
-plane, including  ,
,  . Also suppose that the functions
. Also suppose that the functions  and
and  are both continuous and both have continuous derivatives for
are both continuous and both have continuous derivatives for 
 and
and  are constants, we have
are constants, we have
 . What is the maximum number of points
. What is the maximum number of points  you can have such that they are equidistant, i.e.
you can have such that they are equidistant, i.e.  for all
for all  , where
, where  is some fixed constant?
is some fixed constant? . Turns out it was pretty difficult to find a reference that proved this in an easy-to-understand presentation (for me), so I’m writing my own version (largely based on Reference 1).
. Turns out it was pretty difficult to find a reference that proved this in an easy-to-understand presentation (for me), so I’m writing my own version (largely based on Reference 1). in two parts:
in two parts: , let
, let  be the vector with all zeros except for a 1 in the
be the vector with all zeros except for a 1 in the  th position. For any
th position. For any 
 , where
, where 
 , then
, then
 are all equidistant from each other.
are all equidistant from each other. are all equidistant, then the set of differences
are all equidistant, then the set of differences  is a set of
is a set of  linearly independent vectors.
linearly independent vectors. and
and  . Assume that
. Assume that  . Assume we have coefficients
. Assume we have coefficients  such that
such that
 and take a dot product of both sides above with
and take a dot product of both sides above with  :
:


 applies for any
applies for any  with
with  , we must have
, we must have
 are equal. But plugging this back into
are equal. But plugging this back into  , or
, or  .
.
 be as above, and define the sequences
be as above, and define the sequences
 generates the complete sequence of primes
generates the complete sequence of primes  .
. is defined as an infinite sum involving all the primes themselves… if
is defined as an infinite sum involving all the primes themselves… if  denotes the
denotes the  ), the Buenos Aires constant is defined as
), the Buenos Aires constant is defined as
 for all
for all  be a sequence of positive integers satisfying
be a sequence of positive integers satisfying  ). Define the sequences
). Define the sequences
 for all
for all  be a function so that
be a function so that  is continuous on
is continuous on ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) and satisfies
and satisfies  . Let
. Let  be a polynomial of degree
be a polynomial of degree  that interpolates
that interpolates 
 on the interval
on the interval ![[0, \pi]](https://s0.wp.com/latex.php?latex=%5B0%2C+%5Cpi%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and let
, and let  , which means we are looking at a quadratic approximation.
, which means we are looking at a quadratic approximation. , so we can set
, so we can set  . The interpolating quadratic function needs to go through
. The interpolating quadratic function needs to go through  ,
,  and
and  , which by
, which by 

 . As you can see from the y-axis on the right plot, the bound is pretty loose for this example.
. As you can see from the y-axis on the right plot, the bound is pretty loose for this example.
 as well (cubic approximation). The 4th derivative of
as well (cubic approximation). The 4th derivative of  , so we can set
, so we can set  ,
,  and
and 


 be a standard normal random variable. Then for any
be a standard normal random variable. Then for any  , defining
, defining

 from the perspective of numerical integration.
from the perspective of numerical integration. in the original formula is replaced with a
in the original formula is replaced with a  ):
):


 .
.



 be
be  , define the
, define the 
 for “sum” and
for “sum” and  for “mean”. For
for “mean”. For  , define
, define  .
.
 ,
,
 ,
,
 , which is simply the
, which is simply the  . We need to show that it is also true for
. We need to show that it is also true for  . Fix the value of
. Fix the value of  (
( resp.) denote the symmetric mean (sum resp.) for
resp.) denote the symmetric mean (sum resp.) for  and let
and let  (
( resp.) denote the symmetric mean (sum resp.) for
resp.) denote the symmetric mean (sum resp.) for  . Then, by considering whether
. Then, by considering whether  is in the term or not,
is in the term or not,![\begin{aligned} S_k &= \sum_{1 \leq i_1 < \dots < i_k \leq m} x_{i_1} x_{i_2} \dots x_{i_k} \\ &= \sum_{1 \leq i_1 < \dots < i_k \leq m-1} x_{i_1} x_{i_2} \dots x_{i_k} + x_m \sum_{1 \leq i_1 < \dots < i_{k-1} \leq m-1} x_{i_1} x_{i_2} \dots x_{i_{k-1}} \\ &= S_k' + x_m S_{k-1}', \\ M_k &= \dfrac{1}{\binom{m}{k}} \left[ \binom{m-1}{k} M_k' + \binom{m-1}{k-1} x_m M_{k-1}' \right] \\ &= \dfrac{m-k}{m} M_k' + \dfrac{k}{m} x_m M_{k-1}'. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+S_k+%26%3D%C2%A0+%5Csum_%7B1+%5Cleq+i_1+%3C+%5Cdots+%3C+i_k+%5Cleq+m%7D+x_%7Bi_1%7D+x_%7Bi_2%7D+%5Cdots+x_%7Bi_k%7D+%5C%5C++%26%3D+%5Csum_%7B1+%5Cleq+i_1+%3C+%5Cdots+%3C+i_k+%5Cleq+m-1%7D+x_%7Bi_1%7D+x_%7Bi_2%7D+%5Cdots+x_%7Bi_k%7D+%2B+x_m+%5Csum_%7B1+%5Cleq+i_1+%3C+%5Cdots+%3C+i_%7Bk-1%7D+%5Cleq+m-1%7D+x_%7Bi_1%7D+x_%7Bi_2%7D+%5Cdots+x_%7Bi_%7Bk-1%7D%7D+%5C%5C++%26%3D+S_k%27+%2B+x_m+S_%7Bk-1%7D%27%2C+%5C%5C++M_k+%26%3D+%5Cdfrac%7B1%7D%7B%5Cbinom%7Bm%7D%7Bk%7D%7D+%5Cleft%5B+%5Cbinom%7Bm-1%7D%7Bk%7D+M_k%27+%2B+%5Cbinom%7Bm-1%7D%7Bk-1%7D+x_m+M_%7Bk-1%7D%27+%5Cright%5D+%5C%5C++%26%3D+%5Cdfrac%7Bm-k%7D%7Bm%7D+M_k%27+%2B+%5Cdfrac%7Bk%7D%7Bm%7D+x_m+M_%7Bk-1%7D%27.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 . To do that, apply the identity above to each term of
. To do that, apply the identity above to each term of  , then apply the induction assumption and do some algebraic manipulation to get it to be
, then apply the induction assumption and do some algebraic manipulation to get it to be  . (Details in Reference 1.)
. (Details in Reference 1.)