从 Gemini 3.1 Pro拿下竞赛数学题,目前唯一答对的 - 搞七捻三 - LINUX DO继续讨论:
我当时测试GPT 5.2 Thinking这道题做不出来(超出思维链长度上限直接截断),有佬友表示5.2 Pro做得出来,遂测试
提示词:3. 设 n 是正整数. 有 n 张红色卡片与 n 张蓝色卡片, 最初每张红色卡片上都写有一个实数 0, 每张蓝色卡片上都写有一个实数 1. 一次操作是指: 选择一张红色卡片与一张蓝色卡片, 满足红色卡片上的实数 x 小于蓝色卡片上的实数 y, 将这两个实数擦去, 并在这两张卡片上都写下实数 \frac{x+y}{2}.
求最小的正整数 n, 使得可以适当地进行有限次操作, 让所有 n 张红色卡片上的实数之和大于 100.
中文回答,公式用$包裹,输出详细解析。这是一道极其困难,极其具有误导性的顶级竞赛题目,你必须最大化思考强度才有可能做出来。禁止联网搜索
以下是5.2Pro的解答:
(注:由于ChatGPT网页端的公式渲染似乎有bug,我又让3Flash帮我格式化了一遍)

检查了一下思维链,期间使用了Python工具,共用时74m18s解出答案
我又新开了个对话,尝试要求它不使用任何工具解出答案,然后苦等了3个小时……然后……

从思维链来看,还是做错了,跟绝大多数模型一样答了101而非正确答案106
错就错了,模之常情(目前还没有遇到第三个做得出来的)
但关键问题在什么地方呢?
Gemini 3.1 Pro做出这道题用了:
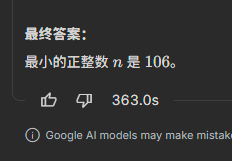
363秒。
恐怖。
当然,GPT做得慢也不是完全没有理由的,我们来看下双方的互评:
Gemini对GPT批评的总结:

所以说Gemini的回答还是有些不严谨的,应该扣分(Gemini自评认为自己应该拿总分的40%,因为过程有跳跃)
Gemini的做法十分巧妙(注意力惊人),而GPT的做法就是纯粹的暴力了:

为什么会得出这样的结论呢?我把GPT的思考过程丢给Gemini分析(这里是最精彩的

好家伙,合着GPT仗着自己超长思维链直接暴力用数值计算摸索出答案符合的规律,然后从结论倒推“假装”自己真的做出过程了啊……
彩蛋:又让Gemini分析了一下GPT禁用Python工具后苦苦思考3小时的那一场,结果更搞笑了,GPT完全没摸到正确路径,笃信正确答案是101:
