gemini-3-pro-preview也出了有几天了,不知道各位体验的如何
不过看起来注意力确实不是很好
之前cli泄漏的时候就测过一次了,当时就在说注意力可能不会很好,只有2.5p的1/3,不过现在看来没有任何变化,曲线甚至都没有变,依旧是2.5p的1/3:
Gemini 3 Pro召回率测评,召回率只有2.5Pro的1/3, 上下文注意力大退步,实际写代码或许堪忧? - 开发调优 - LINUX DO
现在正式上线了,给出一个新的跑分结果:

可以发现是否开思考,思考预算和等级开多少,和注意力没有任何关系,对于gemini系列是这样的,但是对于其他厂商的模型不一定。开思考只会增加gemini系列模型的其他方面能力,但是注意力是不会有任何提示的。甚至对于gemini-3pro-preview系列模型来说会有一些方面的退步,比如爆思考预算:
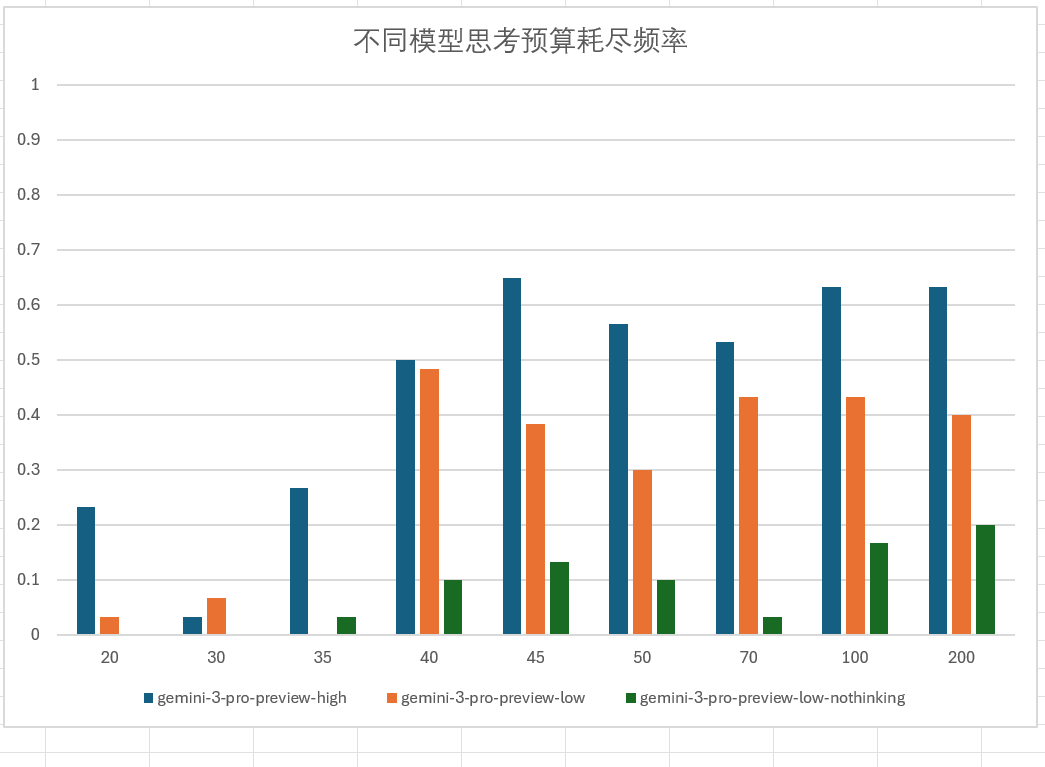
可以发现开高思考反而很容易超过思考预算(32768)导致截断,观察可见,后续一直在重复思考:

甚至思考488秒后截断了:

这个脱靶现象,在捞针测试时很常见,所以在得出思考和注意力无关后,我都是设为low进行测试的。
所以,如果没有必要,思考设为low或许是个很好的选择,既不至于能力下降太多,又不至于让模型思考过多
对于思考过多:其实你仔细观察,会发现模型经常会重复进行思考某些内容,或者进行自我安全审查,开high反而没有用处
如果可以,你可以试着卡掉他的思维链,或者进行覆写。总之原生思维链问题很大,有点太烂了。需要提示词进行发力。
还有一点,设置思考等级和预算,不意外着其只能思考那么多token,超过强行截断。你可以理解为,内置了一个提示词:你的思考等级是high/low,这样
因为我设置low,依旧能思考32k后截断。从这里就能看出来了
另外,我再强调一下,不能说3p注意力只有32k,只能说3p注意力是2.5p的1/3大概,因为影响因素很多,比如改变针的数量:

其实这个图里面是有规律的,每10针注意力加10k大概,但是针多了就不明显了,还有一些其他规律:

以后再开帖细说吧,不过能看见我选的40针只是一个折中的结果而已。所以说本测试的绝对数字其实不具有直接意义,只能用来进行各种比较
本测试仓库链接,存放有原始数据和结果
