thoughts on clean code, better testing and team oriented software engineering
Author: Manuel Naujoks
I am a software developer from Karlsruhe. I am holding a Master Of Science In Computer Science degree.
Find me on Twitter at @halllo or visit my website at www.njks.de (German).
A specter haunts the professional world—the fear that artificial intelligence is killing the career ladder. From software development to law, senior professionals worry that companies will stop hiring juniors because AI can now handle the routine tasks that traditionally trained new graduates. The commodity work that once served as a proving ground for fresh talent is increasingly automated, leaving many to wonder: where will the next generation of professionals learn their craft?
This concern, while understandable, misses a fundamental shift in how learning happens in the age of AI. Rather than eliminating the need for junior professionals, AI is transforming what it means to be one—and potentially accelerating their development in ways we’re only beginning to understand.
The Adaptation Advantage
Working closely with software development students has revealed something remarkable: junior professionals aren’t just adapting to AI tools—they’re mastering them faster than many of their senior counterparts. This isn’t surprising when you consider that these students have no legacy habits to unlearn, no muscle memory of “the old way” to overcome.
While senior developers might approach AI with skepticism or struggle to integrate it into established workflows, juniors embrace these tools as natural extensions of their problem-solving toolkit. They’ve grown up in an era where technology evolves rapidly, making them inherently more comfortable with constant change and new paradigms.
Learning Through Better Code
The traditional model of junior development involved writing lots of mediocre code, making mistakes, and gradually improving through trial and error. AI fundamentally changes this equation. Junior developers working with AI tools often produce code that’s structurally better than what they could have written independently. This creates a fascinating learning dynamic: instead of learning from their own mistakes, they’re learning from examples of good practice.
When a junior developer uses AI to generate a function and then needs to integrate it, debug it, or extend it, they’re engaging with code that follows better patterns and practices than their initial attempts might have. This exposure to higher-quality code accelerates their understanding of what good software looks like and how it behaves.
The Debugging Generation
Perhaps most importantly, junior professionals in the AI era are developing a crucial skill from day one: working with legacy code. Every AI-generated piece of code is, in essence, legacy code from the moment it’s created. It wasn’t written by the developer who must now maintain it, its original context might be unclear, and its assumptions might not be documented.
This reality forces junior developers to become skilled at reading, understanding, and debugging code they didn’t write—a skill that traditionally took years to develop. They must learn to trace through logic, understand intent, and identify problems in systems they didn’t architect. These are exactly the skills that separate effective senior developers from those who can only work with their own code.
Beyond the Textbook
The traditional approach to learning legacy code skills involved reading books like Michael Feathers’ “Working Effectively with Legacy Code” after years of experience. But today’s junior developers are developing these skills organically through their daily work with AI-generated code. They’re learning to work with unfamiliar codebases, to understand systems through testing and exploration, and to make changes safely in code they didn’t design.
This hands-on experience with the challenges of legacy code—understanding undocumented assumptions, tracing through complex logic, and safely modifying existing systems—provides practical skills that no textbook can fully convey.
The Efficiency Imperative
Junior professionals working with AI also develop a different relationship with efficiency. They learn to leverage tools effectively, to iterate quickly, and to focus their human intelligence on the problems that matter most. Rather than spending time on routine tasks, they can concentrate on understanding requirements, designing solutions, and solving complex problems.
This shift means junior professionals can contribute meaningfully to projects much earlier in their careers. They’re not just learning to code; they’re learning to think like senior developers while having AI handle much of the routine implementation work.
Rethinking Professional Development
The concern about AI eliminating junior roles stems from a fundamental misunderstanding of what these roles provide. The value of junior professionals was never just in their ability to handle routine tasks—it was in their fresh perspectives, their willingness to question assumptions, and their potential for growth.
In the AI era, these qualities become even more valuable. Junior professionals who can effectively collaborate with AI tools, who understand how to validate and improve AI-generated work, and who can bridge the gap between human intent and machine execution are exactly what organizations need.
The Path Forward
Rather than fearing the impact of AI on junior professional development, we should embrace the opportunities it creates. Organizations that invest in training junior professionals to work effectively with AI tools will develop a workforce that’s more capable, more efficient, and better prepared for the future of work.
The key is recognizing that the skills junior professionals need to develop have evolved, not disappeared. Instead of learning to write code from scratch, they need to learn to direct, evaluate, and improve AI-generated code. Instead of starting with simple, isolated tasks, they can engage with complex, integrated systems from day one.
This evolution doesn’t eliminate the need for junior professionals—it makes their development more crucial than ever. The organizations that understand this will have a significant advantage in building teams that can effectively leverage AI while maintaining the human insight and creativity that drives innovation.
The future belongs not to those who can replace humans with AI, but to those who can help humans and AI work together most effectively. And that future starts with how we train our junior professionals today.
Over the last weekend (14.-15. June 2025) I attended the {Tech: Karlsruhe} AI Hackathon. In general hackathons are great opportunities to learn new concepts, try out new frameworks or APIs, and get to know fellow builders. So I was looking forward to this.
The day before I thought about potential projects to work on. Since the hackathon was structured into three tracks with certain challenges, I needed an idea that was not only exciting and feasible, but also a good fit for the event.
Inspiration
Being inspired by IBM’s Project Debater from a 2019 (the pre-LLM era), I wanted to build something similar. If you have not heard about Project Debater, I can highly recommend this 60min recording.
Ideation
AI democratizes intelligence. With todays LLMs and frameworks we should be able to build a similar solution and even improve upon it in certain areas. Other than Project Debater, I wanted to simulate the entire debate solely between agents, without any human involvement. The outcome of the debate could then be reviewed and its inputs (arguments/prompts) tweaked, before the system runs the debate again. That way the system could be used to simulate different strategies and observe their effectiveness and impact on the outcome: winning or losing the debate. It could even use a reinforcement learning feedback loop to optimize itself autonomously, like AlphaZero, to discover the most effective arguments/strategies.
In real life just knowing the best arguments is not enough to win a debate. The arguments also have to be delivered well. That takes practice. To also support that aspect, the system should have an interactive training mode. Here the human can step into the debate and deliver its argument as part of the simulation.
I don’t think there is any doubt about the usefulness of it. Applications for debate technology are plenty. Debates are everywhere, especially in legal, politics, and the social sciences. I think all industries benefit form comparing multiple perspectives, contrasting arguments, and weighing pros and cons. This philosophical tool would provide a useful and valuable capability for any domain.
Implementation
At the hackathon I pitched the idea and we formed a team of five around it. As a first step we needed to find an appropriate tech stack. It seemed clear to us to have multiple agents interact with each other: one agent per side and a judge to evaluate and declare the winner. What agent framework should we use? We evaluated Agents SDK, Agno, ag2, CrewAI, LangChain, and LangGraph. Eventually we settled for LangGraph as it gave us the most control to shape the flow of information in the system. We used Lovable to generate a React frontend.
Our project competed in the “AI Applications” track of the hackathon. As a requirement we had to use at least three partner/sponsor technologies. That was not difficult for us. We used Mistral AI to generate arguments and evaluations. We used ElevenLabs to generate audio representations of the responses. For the interactive training mode we used Beyond Presence to give the opponent machine a human face. This created an immersive debate experience, almost as real as an online meeting.
Presentation
After two days of intensive work, it was time to presented our project. The first presentation was in front of a panel of partners/sponsors. In our track we made it to the top three finalists. This got us a second chance to present it to the entire audience of all attendees. Before the second presentation we found ourself in a situation where our application did not work anymore. Without our demo we would not stand a chance in the finals. Luckily we managed to get it working again just in time for our big presentation. And we actually won the “AI Applications” track!
Thanks to my team for bringing this idea to life. Thanks to {Tech: Europe} for organizing the hackathon.
I learned a lot and enjoyed the weekend. There is no debate about it.
Am vergangenen Donnerstag, Freitag und Samstag (12.-14. Oktober 2023) habe ich an den AI Labs Days #aild23 teilgenommen. Nach dem Erfolg des #iil22, dem letzten Hackathon der STP, stand dieses Jahr alles im Zeichen von Generative Artificial Intelligence, Large Language Models und Legal Prompt Engineering. Wer schon immer mal ein spezielles Modell oder ein Framework in Verbindung mit einem kleinen Projekt ausprobieren wollte, hat mit den Labs Days jedes Jahr den perfekten Rahmen dafür. Vier Teams haben teilgenommen und an einer ihrer Ideen gearbeitet. Dieses Jahr waren wir nicht im STP Gebäude, sondern im Moxy Hotel in Karlsruhe. Dort hatten wir Vollpension und konnten uns gut auf unsere Projekte konzentrieren.
In einer Kanzlei spielen Dokumente eine zentrale Rolle. Mandanten beschreiben ihre Probleme, Indizien werden gesammelt, Schriftstücke werden erstellt oder beantwortet. In allen diesen Dokumenten finden sich rechtliche Sachverhalte, die ein Anwalt bewertet und zum Nutzen der Mandanten verarbeitet.
Meine Idee setzt beim Dokument an und fasst den Sachverhalt zunächst zusammen. Der zusammengefasste Sachverhalt wird anschließend analysiert und die einzelnen Aspekte den betroffenen Rechtsgebieten zugeordnet. Mit diesen Informationen können dann weitergehende und Rechtsgebiet-spezifische Analysen durchgeführt werden. Am Ende geht es darum die Arbeit mit rechtlichen Sachverhalten mehr zu automatisieren und damit zu vereinfachen. Simplify legal work!
Made with Microsoft Bing Image Creator powered by DALL·E 3
Nach dem Vorstellen der unterschiedlichsten Ideen fand meine Idee 4 Mitstreiter. Wir haben uns also zunächst auf die Suche nach einer Liste aller Rechtsgebiete gemacht. Dabei haben wir gelernt, dass es keine offizielle Liste gibt, sondern nur Annäherungen. Also haben wir uns aus verschiedenen Quellen eine eigene in Form eines hierarchischen JSON-Dokuments zusammengestellt.
Dann ging es ans Legal Prompt Engineering. OpenAI GPT-4 ChatCompletion hat sich schnell als produktivste API herausgestellt. In unserem System Prompt haben wir für das nötige Priming gesorgt und auch unsere Rechtsgebiete.json platziert. GPT-4 versteht JSON und Code so gut, dass wir sogar SudoLang verwenden konnten. Den tatsächlichen Sachverhalt haben wir dem Modell dann als User Prompt mitgegeben. Mit einem Python-Programm haben wir diese Prompts dann kodifiziert und automatisierbar gemacht. Das hat uns bereits am ersten Tag sehr gute Ergebnisse gebracht. Wir hatten auch einen echten Rechtsanwalt dabei, der uns dabei unterstützte, die Plausibilität der klassifizierten Rechtsgebiete zu bewerten. Das hat uns dann auf die Idee gebracht, einen Multi-Agent-Ansatz auszuprobieren, in dem ein erster Agent klassifiziert und ein weiterer Agent die Qualität sichert.
Am zweiten Tag haben wir unsere Python-Anwendung containerisiert und im Kubernetes unserer Development-Umgebung gehostet. Natürlich mit CI. Dadurch konnten wir unseren Rechtsgebiet-Klassifizierungsdienst jederzeit mit einem Sachverhalt über HTTP aufrufen und haben die klassifizierten Rechtsgebiete als JSON-Array zurück bekommen. Wir konnten also einfacher und mit mehr Sachverhalten testen. Bei größeren Sachverhalten hatten wir Probleme, weil diese nicht in die 8k-Tokengrenze passten. Daher mussten wir unseren ersten Verarbeitungsschritt optimieren. Statt einer SudoLang-Funktion, die den Sachverhalt im LLM zusammenfasst, mussten wir die Zusammenfassung in unserem Python-Code steuern. Wir haben den Sachverhalt also zunächst in gleichgroße Chunks gesplittet und diese dann rekursiv zusammengefasst. Für n Chunks muss also n-1 mal zusammengefasst werden. Jetzt konnten wir auch große Sachverhalte verarbeiten. Allerdings hat die Latenz so stark zugenommen, dass wir für große Sachverhalte ständig Timeouts erhielten. Den Ingress-Timeout von 1 auf 10 Minuten anzuheben hat zwar das Timeout-Symptom gelindert, aber nicht das Laufzeitproblem gelöst. Für die Zusammenfassung haben wir dann GPT-3.5 Turbo verwendet. Das ist wesentlich schneller und konnte unsere Latenz auf ein akzeptables Maß reduzieren. Am Ende des zweiten Tages hatten wir dann einen guten Agenten der zusammenfasst und klassifiziert und einen zweiten Agenten, der die Qualität sichert.
Am dritten Tag haben wir den Multi-Agent-Ansatz weiterverfolgt. Wir wollten pro Rechtsgebiet einen Agenten betreiben, der für das jeweilige Rechtsgebiet ausführlich mit einem System Prompt vorbereitet wurde. Die Rechtsgebiet-Agents sollten also die für ihr Rechtsgebiet klassifizierten Inhalte bewerten und feststellen, ob es sich hierbei wirklich um Dinge handelt, die in dem jeweiligen Rechtsgebiet geregelt sind. Diese Agents könnten dann auch weitergehende und Rechtsgebiet-spezifische Analysen durchführen. Hierfür haben wir AutoGen verwendet. Wir haben uns aber zunächst auf drei Rechtsgebiet-Agents limitiert um das Prinzip zu implementieren. Am Ende konnten wir die Diskussion der Agents beobachten. Uns fehlte aber noch ein Mechanismus, um aus den Bewertungen der einzelen Agents wieder eine ganzheitliche Antwort für die Anwendenden zu erzeugen. Dazu sind wir leider nicht mehr gekommen. Parallel dazu haben wir unseren Rechtsgebiet-Klassifizierungsdienst prototypisch in unser Dokumentenmanagementsystem eingebaut. Wenn ein Dokument ausgewählt wird, steht in der Detailansicht, direkt neben der Dokumentvorschau, die Zusammenfassung und die Zuordnung zu den Rechtsgebieten zur Verfügung.
Am Samstag um 14 Uhr war es dann soweit. Wir durften unser Projekt als zweites Team vorstellen. Wir haben die von uns klassifizierten Sachverhalte gezeigt, sind auf unsere neugemachten Erfahrungen eingegangen und haben unseren Dienst auch live gezeigt (zunächst per Postman und abschließend direkt in der Oberfläche unseres Dokumentenmanagementsystems).
Für unser Projekt haben wir dann sogar noch den Vorstandspreis erhalten, über den wir uns sehr gefreut haben. Der just-awesome-Preis ging an ein Projekt, welches mit Legal Prompt Engineering jede Menge andere interessante Daten und Fakten aus Dokumenten und Akten extrahieren konnte.
Glücklich und erschöpft gingen wir dann um 15:30 Uhr in das wohlverdiente (aber kurze) Wochenende. Wir blicken auf drei lehrreiche, inspirierende und motivierende Tage zurück. Ich freue mich schon auf nächstes Jahr. Ein tolles Event!
Am vergangenen Donnerstag und Freitag (13.-14. Oktober 2022) habe ich am STP International Innovation Labs #iil22 teilgenommen. Nachdem der letzte #iil(21) 100% remote war, war es dieses Jahr wieder 100% im Büro. Fünf Teams haben an dem 24-stündigen Hackathon wieder an einer ihrer Ideen gearbeitet. Wer schon immer mal einen speziellen Cloud-Dienst oder ein Framework in Verbindung mit einem kleinen Projekt ausprobieren wollte, hat mit dem #iil jedes Jahr den perfekten Rahmen dafür. STP hat während des Hackathons auch wieder die komplette Verpflegung übernommen. Dadurch haben wir jedesmal viel Spaß und lernen auch immer eine große Menge dazu.
Mein Kollege und ich bildeten eins der fünf Teams. Unser Thema war die “Automatisierung von grundlegenden Operationen”, die häufig in Verbindung mit Dokumenten durchgeführt werden und von Anwendern oft als zeitraubend, umständlich und frustrierend wahrgenommen werden.
Wir alle kennen die Begeisterung und Erwartungen wenn ein neues Projekt startet. Im Falle einer Kanzlei wäre die Akquisition eines neuen Mandanten vielleicht eine vergleichbare Situation. Alle Beteiligten sind voller Elan, freuen sich über die neue Herausforderung und wissen, dass sie am Ende auch bezahlt werden. Doch kurze Zeit später setzt die Ernüchterung ein. Es gibt neben den spannenden Tätigkeiten auch jede Menge langweilige Aufgaben. Zeitaufwendige, fehleranfällige und frustrierende Arbeitsschritte demotivieren die ausführenden Beteiligten. Auf Dokumente bezogen können dies zum Beispiel das Korrigieren von Rechtschreibfehlern oder das Anpassen von Sätzen oder ganzen Paragraphen sein. Die Konvertierung in andere Formate, sowie das Unterschreiben und Verschicken an verschiedene Parteien gehören ebenfalls dazu.
Die Dinge müssen natürlich erledigt werden. Aber warum manuell? Wie viel effizienter würden wir arbeiten können, wenn solche anspruchslosen Aufgaben automatisiert werden könnten? Diese beiden Fragen haben uns dazu bewogen, ein experimentelles Programm zu entwickeln, welches genau die oben erwähnten Tätigkeiten übernehmen kann: Der LEXOLUTION B.O.T. ist ein Basic Operations Team-member, der Projektteams grundlegende Arbeitsschritte abnehmen kann. Dadurch haben Teams wieder mehr Zeit für die wesentlichen und wirklich anspruchsvollen Dinge, die maßgeblich zum Erfolg des Projekts beitragen.
Der LEXOLUTION B.O.T. kommuniziert mit den Teammitgliedern über die API von LEXolution.DMS, dem für Juristen optimierten Dokumentenmanagementsystem von STP. Aufgaben und Aufgabenlisten können jetzt also nicht mehr nur Kollegen sondern auch dem Bot direkt zugewiesen werden. Damit integriert er sich nahtlos in die Arbeitsabläufe des Projektteams und kann von sämtlichen Oberflächen des DMS verwendet werden. Egal ob Anwender im Standard DESK, Outlook DESK, Mobile DESK oder in einer der zahlreichen Integrationen in andere Fachanwendungen arbeiten, sie können von überall Aktivitäten an den Bot delegieren. Workflows in Form von strikten Aufgabenlisten (also Aufgabenlisten mit einer vorgegebenen Abarbeitungsreihenfolge) können entweder vom Bot vollständig übernommen, oder in Zusammenarbeit mit Anwendern erledigt werden. Ein Beispiel für dieses Zusammenspiel ist ein Kontrollschritt, über den menschliches Feedback einfließen kann, bevor der Bot ein Dokument automatisiert an den Mandanten verschickt.
Im Rahmen das Hackathons haben wir dem LEXOLUTION B.O.T. vier verschiedene dokumentbezogene Operationen beigebracht:
Suchen und Ersetzen
Einfache Textersetzungen können stichpunktartig an den Bot delegiert werden. Dazu braucht lediglich eine Aufgabe angelegt werden.
Der Bot wartet im Hintergrund auf Aufgaben, die ihm zugewiesen werden und arbeitet diese anschließend ab. Über die DMS API lässt sich ein solches Verhalten, welches auf Aufgaben reagiert, recht einfach mit dotnet und C# implementieren.
using (dms.Impersonate(user.Xid))
{
var activeTaskIds = await this.dms.TasksAndNotices.LoadTaskIds(STP.Ecm.ApiCore.Impl.LoadTasksModus.Mine);
var activeTasks = await dms.TasksAndNotices.LoadTasksByIds(activeTaskIds.TaskIds, new string[0])
foreach (var task in activeTasks)
{
//Dokument herunterladen, bearbeiten und wieder hochladen
var documentData = await dms.Document.LoadDocumentData(task.DocumentId!.Value);
var document = await Download(documentData.Id);
…
await Upload(documentData, document, taskResolvedComment);
//Aufgabe abschließen.
var taskManager = await dms.TasksAndNotices.GetTaskManager(task);
await taskManager.FinishTask();
}
}
private async Task Download(Guid documentId)
{
var tmpFile = Path.GetTempFileName();
await dms.Document.DownloadContent(documentId, tmpFile, new DocumentDownloadConfig { Format = DocumentDownloadFormat.Original });
var documentStream = StreamExtensions.ReadFromSelfDeletingFileStreamAsync(tmpFile);
return documentStream;
}
private async Task Upload(DocumentData documentData, Stream documentStream, string comment)
{
var filename = documentData.Versions.Last().Filename;
var tmpFile = await documentStream.AsTempFile(filename);
try
{
var checkout = await dms.Document.Checkout(documentData, null);
checkout.Comment = comment;
checkout.FinishWithNewVersionAndNewContent(tmpFile.FullName);
}
finally
{
tmpFile.Delete();
}
}
Für die eigentliche Bearbeitung von Word-Dokumenten und die Ersetzung von Texten haben wir Aspose.Words for .NET verwendet.
Konvertierung zu PDF/A
Das gleiche Prinzip haben wir auch bei der Konvertierung von Word-Dokumenten in das Format PDF/A verwendet. PDF/A ist besonders zur Langzeitarchivierung digitaler Dokumente geeignet.
var doc = new Aspose.Words.Document(Path.Combine(folder, docFilename));
doc.Save(Path.Combine(folder, docFilename + ".pdf"));
var pdf = new Aspose.Pdf.Document(Path.Combine(folder, docFilename + ".pdf"));
pdf.Convert(new MemoryStream(), PdfFormat.PDF_A_3B, ConvertErrorAction.Delete);
pdf.Save(Path.Combine(folder, docFilename + "_pdfa.pdf"));
Unterschreiben mit einfacher elektronischer Signatur
Das Highlight unserer Automatisierung war die automatisierte elektronische Signatur. Bevor Dokumente verschickt werden können, müssen sie unterschrieben werden. Hierzu haben wir zunächst eine K.I. trainiert, welche Unterschriftfelder in Dokumenten automatisiert lokalisiert. Dafür haben wir Object Detection mit Azure Custom Vision verwendet. Das trainierte Model haben wir SILO (Signature Location) getauft und in unseren Bot eingebunden. Obwohl SILO sehr gute Erkennungsraten hat, hatten wir insbesondere bei PDFs mit mehreren Unterschriftfeldern Schwierigkeiten das korrekte herauszufinden. In unserem Prototypen haben wir es dann so programmiert, dass der Bot einfach an der ersten gefundenen Stelle unterschreibt.
Das Einfügen der Bilddatei mit der Signatur stellte sich als besonders schwierig heraus. Zumindest bis wir das Koordinatensystem von Aspose.PDF verstanden hatten. SILO liefert uns Positionen in Form von prozentualen Bounding Boxes, die für die Verwendung in PDFs umgerechnet werden müssen. Hieran habe ich den ganzen Donnerstag Abend gearbeitet. Am Ende war die Lösung, die Werte des Rect-Objekts zu verwenden und nicht die Werte des PageInfo-Objekts.
private static void DrawOn(Aspose.Pdf.Page page, SiLoResponse.BoundingBox boundingBox)
{
page.PageInfo.Margin = new Aspose.Pdf.MarginInfo(0, 0, 0, 0);
var graph = new Aspose.Pdf.Drawing.Graph((float)page.Rect.Width, (float)page.Rect.Height);
graph.Margin = new Aspose.Pdf.MarginInfo(0, 0, 0, 0);
var bbleft = boundingBox.Left;
var bbtop = boundingBox.Top;
var bbwidth = boundingBox.Width;
var bbheight = boundingBox.Height;
//calculate bounding box
var rectangle = new Aspose.Pdf.Drawing.Rectangle(
left: (float)(bbleft * page.Rect.Width),
bottom: (float)(((1 - bbtop) * page.Rect.Height) - (bbheight * page.Rect.Height)),
width: (float)(bbwidth * page.Rect.Width),
height: (float)(bbheight * page.Rect.Height));
rectangle.GraphInfo.Color = Color.Red;
graph.Shapes.Add(rectangle);
//page.Paragraphs.Add(graph); put visible bounding box on page
//draw image
using var imageStream = new FileStream("signature_manuel_naujoks.png", FileMode.Open);
page.Resources.Images.Add(imageStream);
page.Contents.Add(new Aspose.Pdf.Operators.GSave());
var imageRectangle = new Aspose.Pdf.Rectangle(rectangle.Left, rectangle.Bottom, rectangle.Left + rectangle.Width, rectangle.Bottom + rectangle.Height);
var matrix = new Aspose.Pdf.Matrix(new double[] { imageRectangle.URX - imageRectangle.LLX, 0, 0, imageRectangle.URY - imageRectangle.LLY, imageRectangle.LLX, imageRectangle.LLY });
page.Contents.Add(new Aspose.Pdf.Operators.ConcatenateMatrix(matrix));
var ximage = page.Resources.Images[page.Resources.Images.Count];
page.Contents.Add(new Aspose.Pdf.Operators.Do(ximage.Name));
page.Contents.Add(new Aspose.Pdf.Operators.GRestore());
}
Die Erleichterung und Begeisterung war groß, als die Unterschrift schließlich wie von Geisterhand an der richtigen Stelle im PDF erschien.
Es handelt sich hierbei um eine einfache elektronische Signatur nach eIDAS-Verordnung. Eine qualifizierte elektronische Unterschrift, die nach eIDAS-Verordnung zur händischen Unterschrift gleichwertig ist, konnten wir in der begrenzten Zeit leider nicht automatisiert ohne Benutzerinteraktion erstellen. Hier könnten wir eventuell in einer nächsten Iteration mit einer Stapelsignatur einen Kompromiss implementieren.
Verschicken per E-Mail
Nachdem das Dokument nun konvertiert und unterschrieben war, sollte es automatisiert an den Mandanten verschickt werden. Dazu hatten wir verschiedene Möglichkeiten ausprobiert. Zunächst wollten wir einfach einen Microsoft Power Automate Flow verwenden. Schließlich hatten wir hier schon Erfahrung in unserem letzten #iil21-Projekt gesammelt. Leider stand uns der Premium HTTP-Trigger nicht zur Verfügung. Also haben wir im nächsten Experiment SMTP direkt verwendet. Leider war dieser Ansatz ebenfalls nicht von Erfolg gekrönt, sodass wir letztendlich Amazon Simple E-Mail Service (SES) verwendet haben. Nachdem wir die beteiligten Identitäten in AWS verifiziert hatten, gingen die E-Mails durch.
using (var client = new AmazonSimpleEmailServiceClient())
{
var bodyBuilder = new BodyBuilder();
bodyBuilder.TextBody = mailText;
using (FileStream fileStream = new FileStream(tempDocPath + ".pdf", FileMode.Open, FileAccess.Read))
{
bodyBuilder.Attachments.Add($"{documentData.Title}.pdf", fileStream);
}
var mimeMessage = new MimeMessage();
mimeMessage.From.Add(new MailboxAddress(sender));
mimeMessage.To.Add(new MailboxAddress(recipient));
mimeMessage.Subject = subject;
mimeMessage.Body = bodyBuilder.ToMessageBody();
using (var messageStream = new MemoryStream())
{
await mimeMessage.WriteToAsync(messageStream);
var sendRequest = new SendRawEmailRequest { RawMessage = new RawMessage(messageStream) };
await client.SendRawEmailAsync(sendRequest);
}
}
Damit hatten wir jetzt eine kombinierte Lösung, die sowohl Azure, AWS und auch unsere eigene Cloud-Plattform, die STP Cloud, verwendet. Der LEXOLUTION B.O.T. war also startbereit.
Präsentation
Diese vier Operationen haben wir während der Ergebnispräsentation mit einer Einzelaufgabe und einer Aufgabenliste mit drei Schritten automatisiert durchführen lassen. Unsere Demo hat hervorragend funktioniert. Mein Kollege hat dem Bot alle Tätigkeiten bequem über den Mobile DESK vom Handy delegiert. Leider konnten wir die Delegation nicht per Sprache diktieren, da das Smartphone-Mikrofon von der Zoom-Sitzung exklusiv verwendet wurde, über die wir den Smartphone-Bildschirm für die Zuschauer übertragen hatten. Es wurde deutlich, wie stark LEXOLUTION B.O.T. Arbeitsabläufe unterstützen und Projektteams effizienter machen kann. Und je effizienter Kanzleien arbeiten, desto schneller kommen Mandanten zu ihrem Recht. In diesem Sinne war unser Prototyp ein voller Erfolg.
Als Produktmanager hatte ich mir auch gleich überlegt, wie wir unseren Bot weiterentwickeln und vertreiben könnten. Neue Operationen lassen sich einfach in den Bot integrieren, sodass er mit der Zeit immer mehr Funktionen ausführen könnte. Folgende weiterführende Funktionen könnten wir als nächstes einbauen:
Synchronisieren von Dokumenten an verschiedenen Speicherorten
Dokumente automatisiert von gemeinschaftlicher Bearbeitung zurückholen
Kollegen über Änderungen am Inhalt benachrichtigen
Ähnliche Dokumente finden
Mehrere ähnliche Dokumente gleichzeitig bearbeiten
…
Obwohl wir mit unserem Projekt einen guten Eindruck bei den Zuhörern hinterlassen haben, hat es leider nicht für einen Preis gereicht. Der Vorstandspreis ging dieses Jahr an ein Projekt, das handschriftliche Notizen auf Papier direkt in digitale Kanzlei-Abläufe integrieren kann. Der just-awesome-Preis ging an ein Projekt, das eine Datenschutz- und Berufsgeheimnisträger-konforme Alternative zu großen Video-Konferenzsystemen mit WebRTC entwickelt hat. Es ist wirklich erstaunlich, was alles in 24 Stunden programmiert werden kann.
Auch wenn nicht alle Teams einen Preis gewonnen haben, haben wir alle viel dazugelernt. Alle Projekte haben uns motiviert und inspiriert. Um 17 Uhr hatten wir uns das Wochenende dann auch redlich verdient. Ich freue mich jetzt schon auf nächstes Jahr. Ein großartiges Event!
Wir sollten es so und so machen, damit es einheitlich ist.
Softwareentwickler
Diesen Satz schon mal gehört? In Diskussionen und Debatten zur Softwareentwicklung müssen oft verschiedene Ansätze gegeneinander abgewogen werden. Die Wahrscheinlichkeit ist hoch, dass dabei irgendwann das Argument der Einheitlichkeit angeführt wird. Die Vorteile der Einheitlichkeit sind unter anderem folgende:
Alle diese Punkte sind sehr wertvoll. Unbestritten. Doch es gibt Situationen, in denen Einheitlichkeit nicht die beste Wahl ist. Leider wird sie dann oft trotzdem als Totschlagargument benutzt. Hiermit möchte ich meine Kritik an der Einheitlichkeit erläutern.
Was ist besser?
Einheitlichkeit ist nur dann positiv, wenn der Status quo positiv ist. Dann ist alles einheitlich gut. Bei einem schlechten/verbesserungsfähigen Status quo steht Einheitlichkeit im Konflikt mit Verbesserung.
Deswegen sollte Einheitlichkeit bei der Lösungsfindung kein relevantes Kriterium sein. Genauso wenig wie das Kriterium der persönlichen Präferenz oder das Kriterium der Wenigkeit (Weniger-ist-besser) bzw. Mehr-ist-besser.
Eine Lösung ist besser als eine andere, wenn sie nach einer gemeinschaftlichen Bewertung aller relevanten Kriterien (Funktionalität, Performanz, Aufwand, etc.) als besser erkannt wird. Das Team muss sich dazu einig sein, welches die für sie relevanten Kriterien sind.
Ich halte Einheitlichkeit als selbst gesetztes Kriterium nicht nur für irrelevant (Dinge sind gut oder schlecht, unabhängig davon ob sie alle gleich sind oder unterschiedlich) sondern sogar für gefährlich, weil es die Verbesserung behindert.
(Gesetze und regulatorische Anforderung können Verbesserung manchmal ebenfalls behindern, allerdings können wir die leider nicht ändern. Sie sind relevant für die Regierung, aber nicht damit alles einheitlich ist, sondern damit es Standards erfüllt. Es geht nicht um Einheitlichkeit sondern um Interoperabilität. Lasst uns deswegen darüber reden. Aber je mehr Verbesserung-behindernde Kriterien wir dazunehmen, desto schwieriger wird Verbesserung.)
Jede Lösung A verliert ihren Anspruch auf Einheitlichkeit, sobald es eine Lösung B gibt, die objektiv besser ist als A.
Abandon a standard when it is demonstrably harmful to productivity or user satisfaction.
Jef Raskin, The Human Interface
Einheitlichkeit kann in Verbindung mit schlechten Lösungen nicht der Anspruch sein. Es wäre fatal eine schlechte Lösung zu nehmen, nur weil es einheitlich wäre. Der Anspruch muss sein, die beste Lösung zu finden, zu verstehen und diese dann einheitlich umzusetzen.
Das geht natürlich nicht sofort. Aber der Weg ist nicht, bessere Lösungen zu verhindern, sondern auszuprobieren, Erfahrungen zu sammeln und iterativ & inkrementell umzustellen.
Conformity is the jailer of freedom and the enemy of growth.
John Fitzgerald Kennedy
Das Kriterium der Einheitlichkeit ist nicht mehr- oder gar gleichwertig mit technischen Kriterien. Sobald eine Lösung nach den anderen Kriterien besser ist, ließe sich das Kriterium der Einheitlichkeit umformulieren als “gleich schlecht ist besser”. “Gleich schlecht” ist besser als “ungleich schlecht”, aber “ungleich gut” ist besser als “gleich schlecht”.
Die Nachteile der Einheitlichkeit bei einem negativen Status quo können also folgendermaßen zusammengefasst werden:
alles ist gleich schlecht
Behinderung der Verbesserung
Behinderung von an das jeweilige Problem angepasste Lösungen
Echte Verbesserung ist kein Nullsummenspiel, sondern der Status quo wird besser. Dazu müssen am Ende des Tages die besten Lösungen gewinnen. Und deswegen haben wir alle die Verantwortung diese Lösungen zu erkennen. Je objektiver und sachlicher desto besser.
Kompromissbereit oder stur?
Die heilige Einheitlichkeit anzuzweifeln, wird in Softwareentwicklungsteams oft nicht gerne gesehen und nachvollziehbar als Bedrohung des Status quo empfunden. Sogar bei festgestelltem und zugegeben negativem Status quo, wird mangelnde Kompromissbereitschaft und Sturheit vorgeworfen. Unabhängig davon, dass dies auch in die andere Richtung vorgeworfen werden kann, möchte ich anhand von zwei Beispielen zeigen, dass Sturheit auch positiv sein kann. Genau wie die auf den ersten Blick positiv scheinende Einheitlichkeit negativ sein kann, kann nämlich auch die negativ scheinende Sturheit positiv sein. Sturheit in Bezug auf Unwilligkeit gegenüber einer schlechten Sache, z.B. Diebstahl, ist positiv.
Essen-Metapher
Stellen wir uns vor, ich will Salat und Gemüse essen, weil ich mich vegan und gesund ernähren will. Und jetzt kommt mein Freund und sagt, “Hier, du musst Schnitzel mit Pommes essen”. Ich schaue es mir an und denke an all das Fett und die fehlenden Nährstoffe und lehne ab. Mein Freund sagt, “Doch, das ist viel besser, wir essen das hier alle (Einheitlichkeit), deswegen musst du das auch essen. Sei doch kompromissbereit. Wir müssen sonst immer dein Essen mit vorbereiten.” Ich sage jeder kümmert sich um sein Essen selber. Er, “Aber wenn du keine Zeit hast” Ich sage, “Dann kann mich hoffentlich jemand vertreten, der Salat machen kann, oder ich kaufe (lasse machen) irgendwo”. Stellen wir uns vor, ich würde den Salat aufgeben und esse tatsächlich jeden Tag Schnitzel. Nach ein paar Jahren ist der ganze Freundeskreis, inklusive mir, krank. Wir haben Diabetes und Übergewicht. Und dann fragt mich der Arzt, “Warum haben Sie denn nicht Salat und Gemüse gegessen? Das ist doch viel gesünder.” Was sage ich dann? “Die anderen haben das auch gegessen und Hauptsache es wahr einheitlich“?
Scheren-Metapher
Stellen wir uns vor, es ist Basteltag im Kindegarten. Alle Scheren sind stumpf, weil sie schon so lange benutzt wurden. Deswegen bringe ich am nächsten Tag meine eigene, neue und scharfe (Kinder-)Schere von Zuhause mit. Mein bester Freund sieht das und bekommt sofort Angst vor Veränderung und zu verlieren was er gewöhnt ist (alle haben die gleichen bekannten Probleme und keiner ist schneller als der andere). Er versucht die Verbesserung zu verhindern und den Ausreißer wieder in die Mittelmäßigkeit zu ziehen: “Der hat eine andere Schere, das darf er nicht, es muss hier alles einheitlich sein”. Was wäre das bessere Vorgehen? Dem einen das Gute wegzunehmen, sodass alle wieder mit dem Schlechten arbeiten? Oder lieber allen das Gute zu ermöglichen?
Am vergangenen Donnerstag und Freitag (20.-21. Mai 2021) habe ich am STP International Innovation Labs #iil21 teilgenommen. Es war die erste STP LabyDay-Veranstaltung in Zeiten von COVID19. Im Gegensatz zu früheren LabsDays war es diesmal 100% remote. Zusätzlich war der Teilnehmerkreis und der Zeitrahmen größer. Sieben Teams haben in sieben Wochen in ihrer Freizeit an sieben Projekten gearbeitet. Der 24-stündige Hackathon war diesmal nur das Finale. Die Idee der ehemaligen LabsDays und des diesjährigen #iil21 ist es, in kleinen Gruppen an einer eigenen Idee zu arbeiten. Wer schon immer mal ein spezielles Framework oder eine Bibliothek in Verbindung mit einem kleinen Projekts ausprobieren wollte, hat mit dem #iil21 jedes Jahr den perfekten Rahmen dafür. STP übernimmt nicht nur die Verpflegung während des Hackathons, sondern bietet auch Workshops mit externen Trainern und Keynotes mit internen Sprechern an. Dadurch haben wir jedesmal viel Spaß und lernen auch immer eine große Menge dazu.
Mein Kollege und ich bildeten eins der sieben Teams. Unser Thema war “Elektronische Signaturen für Dokumente”. Keiner druckt mehr Dokumente aus und unterschreibt sie manuell, nur um sie anschließend wieder einzuscannen und zu verschicken. Erst recht nicht mehr in Zeiten von Digitalisierung und Home Office. Wir haben uns daher überlegt, wie wir elektronische Signaturen möglichst automatisiert in bestehende Prozesse integrieren können. Es sollten bestenfalls alle manuellen Schritte entfallen. Dadurch würden nicht nur die Unterschreibenden Zeit sparen, sondern auch die Empfänger der unterschriebenen Dokumente.
Um unsere vollautomatisierten Prozesse zu realisieren wollten wir keine eigene App oder Platform bauen. Das hätten wir in der zur Verfügung stehenden Zeit wahrscheinlich nur halb geschafft. Schließlich ist nach einem intensiven Arbeitstag Abends dann doch nicht mehr so viel Energie übrig. Wir haben uns auch überlegt, ob wir unsere Lösung vielleicht auf LEXolution.FLOW, STPs no-code-Platform für Legal Apps, bauen sollten. Wichtig war uns eine Lösung, die uns die größtmögliche Flexibilität bietet. Nach Gartner werden vor allem Rechtsabteilungen zunehmend die Business Application Platforms nutzen wollen, die ihre Unternehmen bereits schon im Einsatz haben.
Specialist #legaltech vendors will increasingly build legal applications on top of business application platforms from Microsoft, SAP, Salesforce and ServiceNow, among others. These will appeal to big enterprises looking to leverage existing investments, and ensure easier integration.
KPMG betont die Notwendigkeit der offenen Systeme und Lösungen, die sich aus unterschiedlichen Komponenten des breiteren technologischen Ökosystems zusammensetzen lassen.
Enterprise technology continues to broaden out into legal functions, blurring the line between legal tech providers and just tech. As 2025 gets closer and digitalization of legal functions continues, organizations may increasingly eschew high-cost, stand-alone technologies that serve specific legal niches. Instead, they’ll look to larger providers for solutions that mesh holistically with their broader technology ecosystem. Like medical tech and fintech providers, legal tech providers will likely either cease to exist or be subsumed by bigger players with broader offerings.
Der Gedanke ein System aus einzelnen Bausteinen zusammenzusetzen, statt auf einer Platform eine proprietäre Lösung zu bauen, gefiel uns und schien auch ganz dem Microservices-Trend zu entsprechen. Das erinnerte uns auch an Rube Goldberg. Herr Goldberg war ein Experte darin aus kleinen und einfachen Komponenten einen umfangreichen Prozess zu bauen.
Rube Goldberg – Illustration History
Statt ein neues System zu bauen, wollten wir also bestehende Komponenten verwenden und diese geschickt und gewinnbringend kombinieren. Zur Orchestrierung der einzelnen Prozessschritte wählten wir Microsoft PowerAutomate, da Kanzleien und Rechtsabteilungen Office 365 einsetzen werden wollen, so Gartner. Die beste Signaturkomponente erschien uns Adobe Sign, da Microsoft sie aktiv präferiert.
Adobe Sign, the market-leading e-signature service in Adobe Document Cloud, is now Microsoft’s preferred e-signature solution.
In Verbindung mit LEXolution.DMS pro, der besten Dokumentenverwaltung für Kanzleien, hatten wir nun alle wichtigen Komponenten indentifiziert um den besten automatisierten Dokument-Signierungs-Prozess bauen zu können. Adobe Sign hat bereits PowerAutomate-Konnektoren, sodass wir nur einen neuen Connector für LEXolution.DMS pro bauen brauchten. PowerAutomate Connectors sind im Wesentlichen Web APIs und ihre Funktionen unterscheiden sich in Actions (“mach das”) und Triggers (“wenn das passiert, dann…”). Die DMS API konnten wir über eine Azure Relay Hybrid Connection in der Cloud erreichbar machen. Dadurch hatten wir eine direkte und Cloud-fähige HTTP API zu LEXolution.DMS pro. Diese HTTP API konnten wir anschließend zu einem PowerAutomate Connector definieren, der uns die folgenden drei Operationen bereitstellt:
Trigger: Document imported
Action: Get Document
Action: Store Document (a new one or merely a new version of an existing document)
Damit konnten wir dann folgenden automatisierten Prozess bauen.
1. Der Klient fordert über ein öffentliches Formular ein Dokument an und erhält eine bereits ausgefüllte Dokument-Vorlage, die er nur noch unterschreiben braucht.
Der erste Ablauf erzeugt ein neues Dokument aus der Vorlage mit den Benutzereingaben und legt es in LEXolution.DMS pro ab.Der zweite Ablauf wird gestartet sobald ein neues Dokumnet dieser Art in LEXolution.DMS pro abgelegt wurde und sendet es mithilfe von Adobe Sign zur Unterschrift an den Klienten.Der Klient unterschreibt das Dokument mit Adobe Sign.
2. Das ausgefüllte und unterschriebene Dokument wir automatisch in LEXolution.DMS pro zum Klienten abgelegt und der Anwalt benachrichtigt.
3. Der Anwalt kann auf seinem Handy entscheiden, ob er das ausgefüllte und unterschriebene Dokument akzeptieren oder ablehnen möchte.
Der Anwalt sieht die Anfrage auf seinem Handy in der Microsoft Teams App.Je nach Entscheidung des Anwalts werden unterschiedliche weitere Abläufe durchgeführt. Im Falle der Ablehnung leiten wir das Dokument zu einer von uns gehosteten Azure Function “Stamp”, die mithilfe von Aspose.PDF ein einfaches Overlay in das PDF einbettet und zurückgibt, bevor wir die neue Version wieder in LEXolution.DMS pro ablegen.Das abgelehnte Dokument erscheint gestempelt in LEXolution.DMS pro. Prozessende.
Natürlich könnte dieser Prozess noch um mehr Schritte erweitert und verbessert werden. Für unseren Proof-of-Value reicht der Prozess in diesem Umfang allerdings bereits aus.
Nach unserer Ergebnispräsentation wurden wir gefragt, ob die Adobe Sign Signaturen tatsächlich rechtlich bindend sind und in Deutschland den händischen Unterschriften gleichstehen. Die kurze Antwort ist “Ja”. In Europa gibt es seit einigen Jahren die Verordnung Nr. 910/2014 des Europäischen Parlaments und des Rates über elektronische Identifizierung und Vertrauensdienste für elektronische Transaktionen im Binnenmarkt, kurz eIDAS (electronic IDentification, Authentication and trust Services). Innerhalb dieser Verordnung werden drei Stufen der elektronischen Signatur unterschieden:
Einfache elektronische Signaturen sind nur Unterschriften in digitaler Form, zum Beispiel in Form eines Bildes der händischen Unterschrift.
Fortgeschrittene elektronische Signaturen müssen dem Unterzeichner eindeutig zugeordnet sein und nicht gefälscht werden können. Hier kommen digitale Signaturen und Public-Key Cryptography zum Einsatz.
Qualifizierte elektronische Signaturen erfordern eine durch einen akkreditierten EU-Vertrauensdienst (beispielsweise D-Trust und Deutsche Post) herausgegebene zertifikatbasierte digitale ID (Public-Key Cryptography). Dadurch haben sie denselben rechtlichen Status hat wie händische Unterschriften.
[Adobe Sign] unterstützt als einzige [Lösung für elektronische Unterschriften] alle akkreditierten EU-Vertrauensdienste und lässt euch die freie Wahl zwischen fortgeschrittenen und qualifizierten elektronischen Signaturen.
Meine Mission bei STP ist es, unseren Partnern, Kunden und Kollegen die Technologien und Bausteine zur Verfügung zu stellen, damit sie in ihren Umfeldern (Kanzleien, Büros, on-the-go) erfolgreich die besten Prozesse etablieren können.
No more old school signatures.
Am Ende war unser Projekt ein ganzer Erfolg. Unser Prozess hat sehr gut funktioniert und unsere Präsentation hat einen guten Eindruck hinterlassen. Wir haben für unseren Proof-of-Value den Kundenpreis gewonnen. Der Vorstandspreis ging dieses Jahr an ein Projekt, dass konkrete Möglichkeiten zur Verwendung von GAIA-X erarbeitet hat.
Auch wenn nicht alle Teams einen Preis gewonnen haben, haben wir alle viel dazugelernt. Alle Projekte haben uns merklich motiviert und inspiriert. Wie jedes Jahr war der #iil21 ein echtes Highlight. Um 17 Uhr hatten wir uns das Wochenende dann auch redlich verdient. Ich freue mich jetzt schon auf nächstes Jahr. Ein großartiges Event!
Vor einigen Monaten habe ich bereits erklärt, warum dienstspezifische Artefakte bei dem jeweiligen Dienst abgelegt werden sollten (Zentrale Service-Einstellungen?) und in welchem Verhältnis Dienst- und Umgebung zueinander stehen (Dienst- oder Umgebung-Orientierung?).
Dabei geht die Frage nach dem Fokus der Gruppierung weit über die beschrieben Einstellungen, Geheimnisse und vergleichbaren Artefakte einer Microservices-Architektur hinaus. Das Thema der Gruppierung betrifft alle Ebenen und beginnt bereits im Quelltext, innerhalb einer Methode.
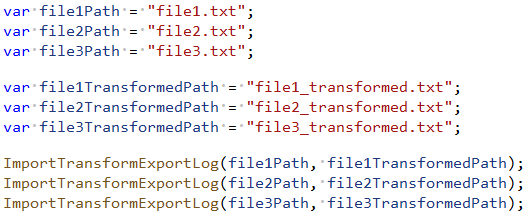
Schauen wir uns einmal einen einfachen Programmcode an.
Es wird eine Datei eingelesen, verarbeitet, gespeichert und abschließend protokolliert. So einfach so gut. Jetzt soll der gleiche Vorgang mit zwei anderen Dateien ebenfalls durchgeführt werden. Und jetzt wird es spannend. Gruppieren wir den Quelltext so?
Gruppierungsalternative A
Oder so?
Gruppierungsalternative B
Jemand könnte anmerken, dass beide Varianten schlecht sind und für die Gemeinsamkeit eine eigene Methode extrahiert werden sollte.
Gruppierungsalternative A’
Das ist auf jeden Fall besser, da von konkreten Implementierungsdetails abstrahiert wurde und es nur noch eine Stelle gibt um beispielsweise die Protokollierung weiterzuentwickeln. Allerdings hat dieses kleine Refactoring nur das Abstraktionslevel erhöht, aber nicht unser Gruppierungsproblem gelöst. Tatsächlich entspricht es weiterhin der Gruppierungsalternative A. Die alternative Gruppierung würde folgendermaßen aussehen.
Gruppierungsalternative B’
Jetzt stellt sich die Frage, wie der Quelltext denn jetzt gruppiert werden sollte. Und vorallem warum so, denn schließlich haben beide Alternativen Vor- und Nachteile.
Aristoteles’ vier Gründe
Zunächst müssen die Unterschiede beider Alternativen beschrieben werden. Dazu können wir den Grund analysieren, warum der Code überhaupt in einer der beiden Alternativen geschrieben wurde. Es treffen hier nämlich mehrere Gründe aufeinander. Nach Aristoteles können Gründe in vier Kategorien eingeteilt werden (Four Causes). Auf die Frage nach dem WARUM gibt es also vier Arten von Antworten. Im Folgenden will ich die vier Gründe vorstellen und direkt auf Quelltext anwenden.
Matter. Die materielle Art, aus der das Objekt besteht. Für die Frage nach dem WARUM eines Stuhls, wäre die Antwort “weil die Holz-Atome und -Moleküle in ihrer Art existieren”. Auf den Programmcode bezogen wären es Daten, Variablen, Operatoren, Anweisungen, Einstellungen, etc.
Form. Die Darstellung und Struktur des Objekts. Für den Stuhl wären das die vier Beine, der Sitz und die Lehne. Auf den Programmcode bezogen wäre es die Syntax und das Design der Klassen und Methoden in Entwurfsmustern.
Agent. Die Entität, die für die Existenz des Objekts verantwortlich ist. Der Stuhl existiert, weil der Tischler ihn gefertigt hat. Auf den Programmcode bezogen wäre das die Person, die ihn programmiert hat.
Purpose. Der Sinn oder das Ziel, dass das Objekt erreichen soll. Der Stuhl existiert, weil sich der Tischler darauf setzen will. Auf den Programmcode bezogen wäre das der Zweck, die fachliche Komponente, das Feature, der Use Case, die Anforderung.
Durch diese Unterscheidung wird deutlich, das Gruppierungsalternative A/A’ den Purpose-Grund in den Vordergrund stellt. Die Anforderung ist “Verarbeite Datei X”, also wird der Quellcode demenstrechend gruppiert.
Gruppierungsalternative B/B’ stellt den Matter-Grund in den Vordergrund. Es geht um Dateien, Variablen, Verarbeitungen und Protokollierungen. Also wird primär nach diesen ‘Atomen’ gruppiert.
Eine Gruppierung nach syntaktischer Darstellung und Entwurfsmustern (Form) ist dem sehr ähnlich und würde JSON-Dateien, Visitors und Adapters in den Vordergrund stellen. Das könnte als Gruppierungsalternative C bezeichnet werden.
Auch die Gruppierungsalternative D ist vorstellbar, die primär nach Agent, also Entwickler gruppiert. Jeder Kollege programmiert seinen Quelltext in seiner Klasse oder Assembly. Schwierig wird es dann allerdings mit der Interoperabilität.
Matter oder Purpose?
Mit dem Wissen über die verschiedenen Gründe der Gruppierung ergeben sich nun neue Argumente für und gegen die oben beschriebenen Alternativen. Sollten wir nach Purpose (Gruppierungsalternative A/A’) oder nach Matter (Gruppierungsalternative B/B’) gruppieren?
Es macht Sinn, ein Softwaresystem primär anhand seiner Features, UseCases und Anforderungen in Dienste und Komponenten aufzuteilen, weil dies die primären Einheiten/Verantwortlichkeiten sind, die ein Team gemeinsam bearbeitet und die sich zusammen ändern. Es macht keinen Sinn, ein System anhand seiner Entitäten oder ‘Atome’ (Startup.cs-Dateien, Controller, DBs, Configs, Secrets, ID-Configs, Dokus, …) aufzuteilen, weil das Details eines Features und damit sekundär sind. Eine solche Aufteilung würde es erschweren Funktionen weiterzuentwickeln und neue hinzuzufügen. Außerdem widerspricht es sämtlichen Design-Prinzipien wie zum Beispiel Kohäsion, SRP, SOC und OCP (siehe oben referenzierte vorherige Blogposts zum Thema).
Es würde auch keiner Menschen eines Unternehmens so aufteilen, dass alle Köpfe hier, alle Hände dort, alle Füße wieder hier und alle Herzen wieder dort zusammengefasst werden. Stattdessen macht es Sinn ein Unternehmen anhand der Produkte aufzuteilen, an denen gearbeitet wird.
Es würde auch keiner das Inventar eines Unternehmens so aufteilen, dass alle Menschen in den ersten Raum, alle Tische in den zweiten Raum und alle Computer in den dritten Raum zusammengefasst werden. Stattdessen macht es Sinn, in jedem Raum eine Person mit Tisch und Computer auszustatten.
Es macht nur eine teleologische Aufteilung (gemeinsamer Sinn) Sinn, keine ontologische (gemeinsame Art). Zumindest solange wir kein Ersatzteillager, sondern einen lebenden und funktionsfähigen Organismus erreichen wollen.
Zentralität oder Dezentralität?
Das Diskussion von Zentralität und Dezentralität von Einstellungen ging am eigentlichen Thema vorbei. Da es bei Einstellungen, zum Beispiel K8S-ConfigMaps und -Secrets, von vornherein um ‘Atome’ (Matter) geht, macht eine dementsprechende primäre Gruppierung oder Zentralisierung keinen Sinn. Die erstrebenswerte Alternative ist aber nicht die Dezentralisierung von Matter, sondern die Zentralisierung von Purpose. Es gibt einen zentralen Bereich für jede fachliche Anforderung, jeden Use Case und jedes Feature. Und nur innerhalb dieses Bereichs können sämtliche Objekte, die einen gemeinsamen Sinn haben, erneut hierarchisch rekursiv gruppiert werden.
Vor einigen Monaten habe ich bereits erklärt, warum dienstspezifische Artefakte, wie beispielsweise Einstellungen, nicht zentral, sondern bei dem jeweiligen Dienst abgelegt werden sollten (Zentrale Service-Einstellungen?). Solange unsere Teams nach Diensten und nicht nach Umgebungen aufgeteilt sind, sollten auch unsere Artefakte nach Diensten partitioniert werden. Dienst-Orientierung ist die einzig sinnvolle Struktur für Microservices.
Personen die primär an der Infrastruktur arbeiten, sehen das eventuell anders. Aus ihrer Sicht ist die Umgebung das primäre Produkt. Das schnelle und automatisierte Erstellen neuer und sogar kurzlebiger Umgebungen ist ein Feature, das ihnen wichtig erscheint. Es stellt sich diesemal also ganz allgemein die Frage, welche Rollen Service Ownership und Environment Ownership einnehmen sollten.
Service Ownership oder Environment Ownership?
Alle Aspekte, die einen Dienst betreffen, fallen primär in den Bereich der Service Ownership. DevOps passiert hier aus dem Team heraus, welches für diesen Dienst verantwortlich zeichnet. Andernfalls würden wir eine neue künstliche und zusätzliche Barriere einführen, die zwischen den Personen, die wissen wie der Dienst läuft, und den Personen, die ihn lauffähig machen müssen, trennen würde. Diese neue Barriere müssten wir dann erstmal wieder mit viel Schnittstellen, Kommunikation und organisatorischer Kopplung überbrücken.
Natürlich muss es auch Environment Owner geben, aber nur für Dienst-übergreifende und Dienst-unabhängige Infrastruktur-Aspekte. Die Dienste bestimmen wie die Infrastruktur aussehen muss. Die Infrastruktur muss sich nach den Diensten richten, nicht andersrum.
Services are King, Infrastructures are Servers.
Damit sind die Rollen definiert. Es bleibt noch eine Frage zu beantworten.
Wie kann ich technisch eine neue Umgebung ausrollen?
Das System besteht aus vielen autarken Diensten, die alle durch ihr eigenes Team entwickelt und betrieben werden. Wenn jetzt eine neue Umgebug in einem anderen Land oder in einer speziellen Teststellung entstehen soll, stellt sich die Frage nach der technischen Umsetzung.
Zunächst müssen zwei Arten von Umgebungen unterschieden werden. Es gibt die permanenten Umgebungen und die kurzlebigen Umgebungen. Permanente Umgebungen sind meist prominent, selten und müssen betreut und auf dem aktuellen Stand gehalten werden. Kurzlebige Umgebungen sind häufig, weniger wichtig und müssen daher einfach nur erstellt werden können.
Beide Arten von Umgebungen müssen mit dem selben Mechanismus erstellt werden können. Eine Automatisierung würde also folgendermaßen vorgehen:
Die Umgebung und allgemeine Dinge werden eingerichtet (zentral).
Alle Services werden aufgefordert, ihre Einrichtung vorzunehmen, indem der richtige Branch (master) ausgecheckt und ein beim Service liegendes Script aufgerufen wird (dezentral).
Die automatisierte Erstellung der Umgebung (zentral) gibt also für die Einrichtung des Dienstes in dieser neuen Umgebung die Kontrolle an den Dienst weiter (dezentral), weil dieser die Hoheit und Verantwortung über die Subdomäne hat.
Ein Dienst richtet sich in einer neuen Umgebung zunächst Default-Einstellungen ein, die er definiert und dafür vorgesehen hat. Wenn es sich bei der neuen Umgebung um eine permanente Umgebung handelt, müssen die Dienste noch zusätzliche Dinge einrichten. Damit der Dienst in der neuen Umgebung auch auf dem akteuellen Stand bleibt, müssen neue Deployment Targets und Release Pipelines erstellt werden. Zusätzlich werden die Dienst-Einstellungen für die neue Umgebung angepasst und separat archiviert.
Auf diese Art und Weise bleiben die Dienste autark und autonom. Sie bilden technische und organisatorische Bounded Contexts und können ihre Einstellungen, Interna und Implementierungsdetails eigenständig und unabhängig voneinander weiterentwickeln und verwalten. Services are King. 👑
Geistige und körperliche Arbeit ist anstrengend. Wenn wir über einen Erschöpfungszustand hinaus weiter arbeiten, nimmt die Qualität unserer Arbeit und damit auch die Qualität der Arbeitsergebnisse ab. Je länger wir arbeiten, desto unkonzentrierter, fehleranfälliger und langsamer werden wir.
Wenn wir also 8 Stunden konzentriert arbeiten und danach noch weitere 4 Überstunden arbeiten, arbeiten wir in diesen 4 Überstunden nicht nur langsamer, sondern machen auch mehr Fehler. Diese Fehler müssen wir wieder korrigieren und das macht uns nochmal langsamer. Das vergleichbare Arbeitsergebnis dieser 4 Überstunden kann sehr wahrscheinlich am nächsten Tag, nach einer nächtlichen Erholung mit viel Schlaf, innerhalb von 1 Stunde erreicht werden. Das bedeutet, dass das gleiche Ergebnis entweder in 12 Stunden (8h + 4h Überstunden) oder in 9 Stunden (8h + 1h vom Folgetag) erreicht werden kann.
Natürlich ist es aus Sicht des Leistungserbringers besser 12 Arbeitsstunden in Rechnung zu stellen als nur 9 Stunden. Aber ist das nicht Betrug? Stellen Sie sich vor Sie fahren mit dem Zug in eine fremde Stadt. Dort steigen Sie in ein Taxi und sagen dem Taxifahrer, dass Sie zum Theater wollen. Der Taxifahrer weiß, dass es auf dem schnellsten Weg zum Theater 10 Minuten dauert. Da er aber ahnt, dass Sie sich nicht auskennen, fährt er Sie einen Umweg von 20 Minuten. Würden Sie sagen der Taxifahrer hat Sie betrogen?
Um eine Deadline einhalten zu können, ist es manchmal notwendig Überstunden zu machen. In diesen Fällen können wir eine ausreichende Erholungsphase nicht abwarten, sondern müssen die Zeit aus der Zukunft vorziehen. Das hat natürlich die oben erwähnten negativen Konsequenzen. Das Ergebnis wird früher erreicht, aber mit mehr Stunden. Ein solches Vorgehen ist nicht nur ineffizient, nicht nachhaltig und ungesund, sondern kostet den Leistungsempfänger unnötig Geld, das er sparen oder in neue Features hätte investieren können. Das sollte uns stets bewusst sein, wenn wir wieder Überstunden machen wollen.
“Wenn jemand zehn Minuten deines Lebens verschwendet, dann sind acht davon deine Schuld.” Markus Frank
Dienstspezifische Einstellungen sollten bei dem jeweiligen Dienst abgelegt werden.
Kohäsion
Es ist eine Frage der Kohäsion. Dinge, die fachlich zusammengehören, sollten auch zusammen und in enger Nähe platziert werden. Es gibt wenig schlimmeres als ein Feature so aufzuteilen, dass es im ganzen System verteilt ist (hier ein bisschen Code, hier ein bisschen Config, hier wieder ein bisschen Code, da ein bisschen Doku, usw.). Dienste sollten möglichst autark sein und bestenfalls eigenständig existieren können. Je mehr Kopplung im System besteht, desto schwieriger wird die Weiterentwicklung. Deswegen sind zentrale Aspekte besonders gefährlich. Manche Funktionen müssen zentral realisiert werden, wie zum Beispiel Authentifizierung, weil es nicht anders geht. Alle Dinge, die nicht zwingend zentralisiert werden müssen, sollten es auch nicht. Für den Anwenderkomfort können zentrale Darstellung mit Hilfe von konsolidierenden Oberflächen und Backends For Frontends geschaffen werden.
Im weiteren zeige ich zusätzlich noch drei eindeutige Vorteile der dezentralen Konfiguration.
Atomare Änderungen
Änderungen und Weiterentwicklungen eines Dienstes müssen nicht mehr an zwei entfernten Stellen (Code und Config) nachgezogen werden und in zwei Phasen committed werden. Diese zwei Stellen haben in der Regel eine zeitliche Kopplung, die zu einer fest vorgegebenen Reihenfolge der Aktualisierung führt, die eingehalten werden muss.
Wenn Code und Config an der gleichen Stelle liegen, kann der Code weiterentwickelt und neue Einstellungen direkt mit angepasst werden. Beides kann mit einem einzigen Commit in der richtigen Reihenfolge atomar deployt werden.
Prepare and Forget
Eine Einstellung kann dann auch nicht fälschlicherweise zu früh deployt werden, was zu Fehlern in der aktuellen Version führen kann, sondern wird erst unmittelbar mit dem Code deployt. Ein Entwickler muss nach seinem Commit nicht erst darauf warten, dass sein Code in Test und schließlich nach Production deployt wird, damit er endlich die Einstellung für die jeweilige Umgebung einstellen kann. Die Einstellung wird automatisch angewendet, wenn der Code in die jeweilige Umgebung freigegeben und deployt wird. Der Entwickler brauch sich nicht mehr kümmern (wenn alles nach Plan läuft). Natürlich muss er die Einstellung für Test, Production und alle anderen Umgebungen kontrolliert vorbereiten, aber das tatsächliche Anwenden passiert transparent im Hintergrund, zur richtigen Zeit automatisiert.
Eventuelle Geheimnisse, die der Entwickler nicht kennen darf, müssen ihm verschlüsselt von der jeweils zuständigen Person mitgeteilt oder in Kooperation vorbereitet werden.
Auch das Wiederherstellen einer früheren Version ist aus der Perspektive der Einstellungen problemlos möglich, da die Einstellungen mit dem selben Commit assoziiert sind.
Verantwortung des Service beim Team
Solange das Team, das den Service entwickelt, auch die Verantwortung für den Betrieb des Services übernehmen soll, müssen alle relevanten Artefakte mit dem Service verwaltet werden. Das Repository repräsentiert auch eine organisatorische Klammer. Durch das Klonen des Repositories bekommen Entwickler nicht nur vollständigen Zugriff auf den Quelltext, sondern auch auf tatsächliche Einstellungen, Build Skripte und Deployment Ressourcen. Ein Entwickler kann sich also jederzeit eine funktionsfähige und sinnvoll konfigurierte Umgebung auf seinem Computer erstellen und für Test- und Entwicklungszwecke betreiben. Isolierte Weiterentwicklungen können dabei sogar problemlos in eigenen Branches erfolgen. Ein Entwickler hat jederzeit alle nötigen Ressourcen zur Verfügung, um die Anwendung eigenständig weiterzuentwickeln.
Einwände
Und wenn sich nur die Einstellung ändert?
Wenn Einstellung und Service in der selben Pipeline deployt werden, ist das erstmal nicht schlimm. Nachteilig ist lediglich, dass es vielleicht etwas länger dauert, bis die Einstellung aktiv wird. Soll die Änderungen sofort gelten, kann sie manuell oder über das K8S Dashboard vorgenommen werden, und wenn sie endgültig sein soll, kann diese Änderung durch commit dokumentiert werden. Durch das anschließende Deployment wird der Wert dann nicht nochmal geändert, weil er bereits auf dem Zielwert steht.
Und wenn sich eine Einstellung auf viele Dienste bezieht?
Einstellungen, die keinem Dienst zugeordnet werden können (Logging, Message Bus,…), können in der Regel der Umgebung zugeordnet werden. Daher sollten sie an einem dafür vorgesehehen Ort für Infrastruktur Konfiguration abgelegt werden.
Einstellungen, die von einem Dienst für andere Dienste bereitgestellt werden, sollten bei dem bereitstellenden Dienst abgelegt werden. Eine Änderung dieser Einstellungen sollte einen automatisierten Neustart der Konsumeten verursachen.
Und wenn sich alle Einstellungen ändern?
Generell sollten Einstellungen so platziert werden, dass wahrscheinliche und häufige Änderungen mit wenig Aufwand vorgenommen werden können, während für unwahrscheinliche und seltene Änderungen höhere Aufwände akzeptiert werden können. Es macht mehr Sinn für Weiterentwicklung einzelner Dienste zu optimieren als für das Umziehen des ganzen Systems in neue Umgebungen. Sollten sich dienstübergreifende Dinge, wie zum Beispiel die Domain, ändern, dann müssen im schlimmsten Fall viele Commits vorgenommen werden. Auch hier kann eine sofortige Änderung manuell oder im K8S Dashboard erfolgen, die dann anschließend noch committed werden muss. Sollten sich dienstübergreifende Dinge häufig ändern, sollten diese hoffentlich wenigen Einstellungen besser an dem Ort für Infrastruktur Konfiguration abgelegt werden.






















You must be logged in to post a comment.