



Measuring the popularity of different Vector Databases.
By Ben Lorica and Leo Meyerovich.
Introduction
Vector databases and vector search are on the radar of a growing number of technical teams. A key driver is that advances in neural networks have made dense vector representations of data more common. Interest has also grown due to the decision of technology companies to open source their core systems for vector search (Yahoo Vespa, Facebook Faiss). Additionally, a collection of vector database startups have raised close to $200M in funding, resulting in new enterprise solution providers and proponents.
While vector databases are used for recommendation, anomaly detection, and Q&A systems, they primarily target search and information retrieval applications. Vector databases are designed specifically to deal with vector embeddings. An example of a vector embedding is a low-resolution picture generated from a high-resolution 3D model. Embeddings are low-dimensional spaces into which higher-dimensional vectors can be mapped into. Embeddings can represent many kinds of data, whether a sentence of text, audio snippet, or a logged event. The key is that embeddings capture some of the semantics of the input and place semantically similar inputs close together in the embedding space. The result is that, by using embeddings, AI applications work much faster and cheaper without losing quality.


The general primitive is identifying nearest neighbors (“vector search”). Since embeddings capture underlying semantics, they provide great building blocks for pipelines that power search applications. Some high profile users of vector search include Facebook (similarity search), Gong and Clubhouse (semantic search), e-commerce sites (eBay, Tencent, Walmart, Ikea) and search engines like Google and Bing.


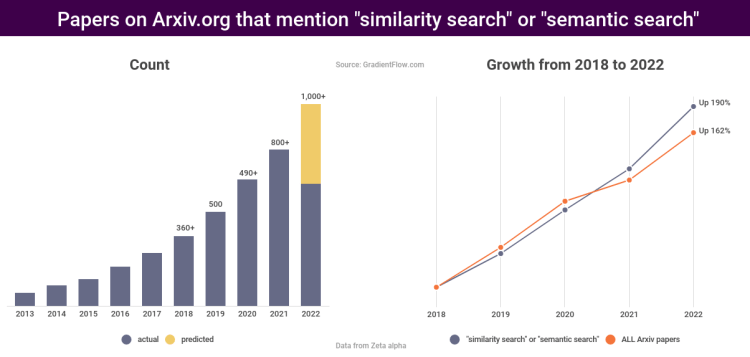
The growing interest in embeddings has been accompanied by increased focus on scaling and speeding up vector search techniques such as KNN, ANN, and HNSW, as well as investments in related tools like hardware acceleration. The chart below shows the growth in the number of research papers that mention “similarity search” or “semantic search”:

Vector Database Index
The purpose of this post is to compare vector databases and libraries using an index that measures popularity. For this inaugural edition, we focus on specialized systems and include only one general search engine – Elasticsearch, which incorporated vector search through Apache Lucene’s new ANN capabilities. As with our previous post on Experiment Tracking and Management tools, we use an index that relies on public data and is modeled after TIOBE’s programming language index. Our index is comprised of the following components:
- Search: We used a subset from TIOBE’s list (Google, Wikipedia, Amazon) and added Reddit, Twitter, and Stack Overflow into the mix.
- Supply (of talent): This component is based on the number of people who have listed a specific vector database as a skill on their LinkedIn profiles.
- Demand (for talent): We examine the number of U.S. job postings from Linkedin and Indeed that mention a specific vector database.


As noted in a prior index calculation, these scores reflect relative popularity rather than overall utility or operational complexity. Search is the driving force behind the overall score. Vector databases are still quite specialized and advanced, so data on both demand and supply of talent remain quite sparse. Due to the sparsity of data on talent (supply and demand), we segmented our index into tiers since resulting rankings can still be volatile for this new category. For example, the most popular tools based on our index are Elasticsearch and Faiss, an open source library developed mainly by Facebook AI Research. Technical teams frequently cite Faiss when discussing vector databases. There are three well-funded startups in the second tier of our popularity ranking: Weaviate, Pinecone, Milvus.
As you can see from the descriptions provided by creators of these tools (see Figure 1), these systems are focused on scalability. Vector databases traditionally index a few million vectors per server (e.g., see Pinecone, Faiss, Weaviate). Techniques such as hashing and sharding facilitate scaling to larger datasets, but that can be prohibitively expensive. Recently a few systems have been highlighting their ability to scale in a cost-effective manner to a billion vectors, such as by supporting bigger-than-memory datasets through indexes optimized for SSD storage (see Vespa, Milvus) or by leveraging hardware acceleration (see GSI Technology). We expect more systems to follow suit in the near future.
Closing Observations
- Embeddings are the lingua franca of modern AI – what is your organization’s strategy for AI embeddings? If your organization is using neural networks, chances are you have embeddings. In some sense, vector databases are about what you get when you embed your entire database. Vector databases are therefore a family of database-managed architectures for bringing AI to your data management system. As organizations evolve how they leverage AI on their critical data, that process includes deciding the right approach to managing data embeddings, such as at the compute-tier (Faiss) or inside a database.
- Other aspects of managing embeddings at scale are worth considering. (1) Support for streaming such as high-throughput for continuous data ingestion, continuous model updates, and high queries-per-second; (2) Vectorization and the broader process of feature engineering (turning raw data into high-quality embeddings) are computationally intensive and often requires compute frameworks like Ray ; (3) Versioning capabilities are an area that new feature stores specialize on.
Vector databases are what you get when you embed your entire database
- Vector search and vector databases aren’t the only new systems being used for unstructured data. Other startups are building tools to address quality, performance, and management issues that get in the way of building and scaling specific BI, analytic, or machine learning applications. A few examples include data management systems that target data labeling and those that store data in formats that can be rapidly streamed to train deep learning models. Likewise, knowledge graph databases are adding native vector capabilities, and graph database vendors recommend representing correlations as correlation nodes or correlation edges in order to reuse their more scalable and mature capabilities.
- Do specialized databases and even hardware for vectors make sense in the long run? As we alluded to above, modern multi-modal databases like Elasticsearch have added vector search capabilities. However, the emergence of specialized systems indicates that AI teams have needs that go beyond what general search engines and databases currently provide. In the long run, will standalone vector databases be a component that most AI teams opt to add? Or will most just use an optimized vector index inside systems like Elasticsearch, data warehouses (BigQuery), and lakehouses, especially considering that underlying (open-source) engines are being used and maintained by large and well-funded AI organizations. Even if AI teams adopt general databases, will the remaining niche use cases be better served by compute-tier solutions, and if so, what does that mean for the growing venture-funded ecosystem of vector databases? The answers depend most on how quickly and how well existing systems improve their vector search capabilities.
Suggestion Form
Use this form to suggest systems to include in future editions of the Vector database Index.
Ben Lorica is a Principal at Gradient Flow. He is an advisor to Graphistry and other startups.
Leo Meyerovich is founder and CEO of Graphistry, the first visual platform for graph AI. Vector search is part of how Graphistry helps security, fraud, social, supply chain, and other data-intensive teams turn graph neural networks and manifold learning into insights and actions.
Related Content:
- Hacker News Discussion
- Previous technology indices can be found here.
- What is Graph Intelligence?
- Large Image Datasets Today Are a Mess
- New open source tools to unlock speech and audio data
If you enjoyed this post please support our work by encouraging your friends and colleagues to subscribe to our newsletter:

Featured Image: Key Phrases found in recent Job Postings that mention: “vector database” or vector|semantic|similarity|neural search.
{kind=link}