My implementation of a DCT (Discrete Cosine Transform) early stopping technique in FAST (Frequency-Space Action Sequence Tokenization) to decrease observation-to-action latency. The idea is to decode only the first few DCT coefficients from the PaLi-Gemma VLM rather than waiting for a full action chunk inference to complete. This can cut down inference to action time by a little under half since around the first 3-4 frequency coefficients of the DCT are typically enough for a coarse action sequence reconstruction.
Note: Action reconstruction accuracy is reduced but predictions can be improved/smoothed by implementing temporal action-chunk ensembling, introduced here.
This is a modified repo for the FAST action tokenizer.
The necessary changes to the pi0-fast model implementation can be found in a forked repo commit
The action tokenizer maps any sequence of robot actions into a sequence of dense, discrete action tokens for training autoregressive VLA models.
The Discrete Cosine Transform (DCT) is a frequency-domain transformation technique that expresses a time-series sequence of data points as a weighted sum of cosine functions at different frequencies. In the context of robot action trajectories, we can leverage DCT's energy compaction property to represent complex action sequences with just a few coefficients.
Robot action trajectories often contain smooth, continuous movements across multiple dimensions. When transformed into the frequency domain using DCT most of the signal's energy gets concentrated in the lower frequency components and the DCT naturally captures the temporal correlation of action sequences at high control frequencies.
The key insight for early stopping is that we don't need to wait for all DCT coefficients to be generated by the model before beginning robot execution. Since the lower frequency components contain most of the action information, we can:
- Generate only the first few DCT coefficients
- Reconstruct a coarse but usable approximation of the action prediction
- Begin executing the action, and optionally, let the model continue generating tokens to resolve higher-frequency details
This approach cuts down inference-to-action time by roughly half, enabling more responsive robot control using pi0-fast.
| Full DCT Action Sequence Reconstruction | 0-4th DCT Harmonics Reconstruction |
|---|---|
 |
 |
This shows a side by side comparison of reconstructions from full DCT coefficients (left) compared to DCT early stopping (right).
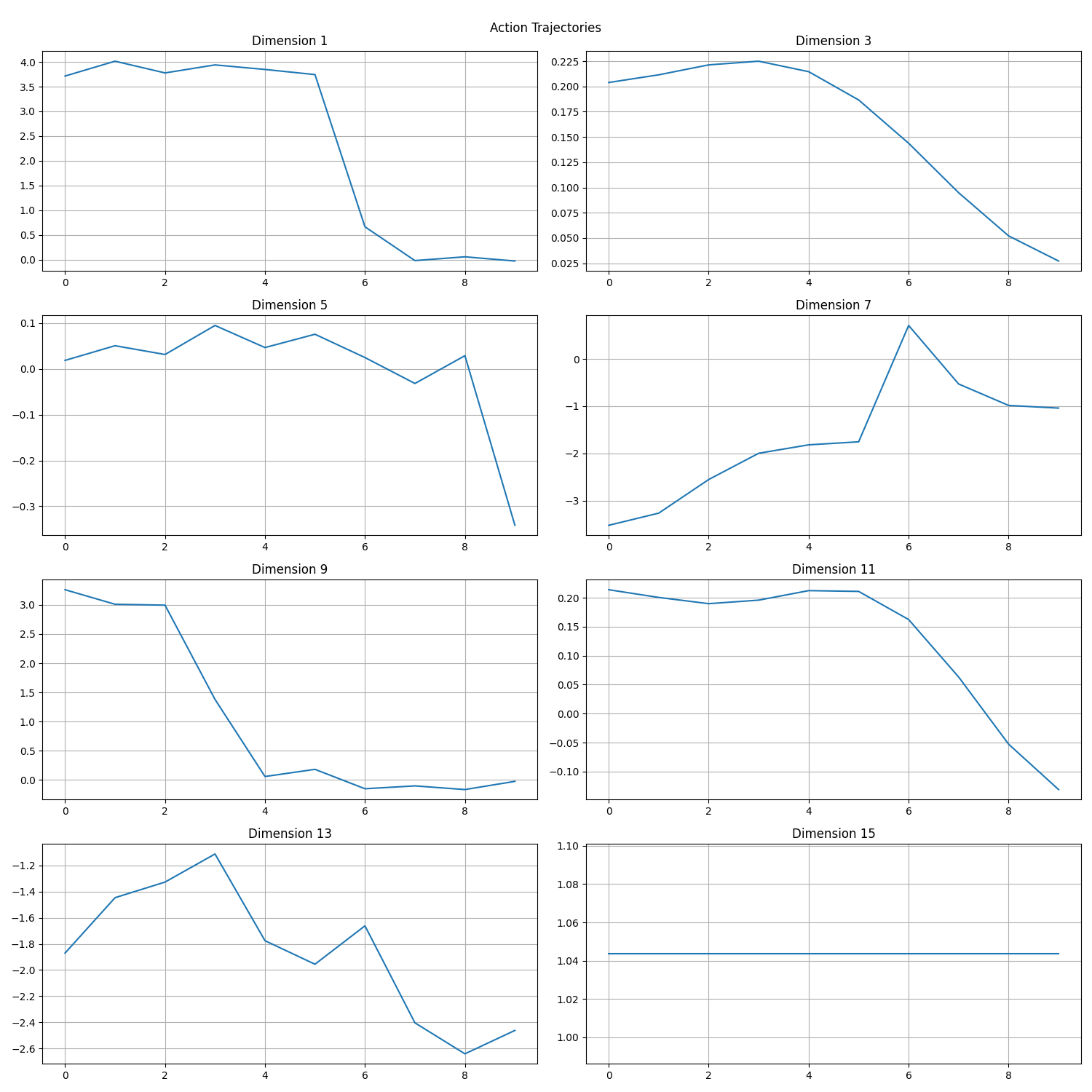
Figure 1: Full DCT Reconstruction This shows action trajectories across multiple dimensions reconstructed using all DCT coefficients (decoded from real tokens generated by a finetuned PI0-FAST model as an example). These are complete, detailed action sequences with all fine-grained movements preserved.

Figure 2: 0th Harmonic Only (DC Signal) This shows reconstructions using only the 0th DCT coefficient (DC component). This essentially captures the mean value of each action dimension - which is why we see flat lines. While this provides the general position for each dimension, it lacks any temporal dynamics.
Figure 3: Early Stopping (0th through 4th Harmonics) This demonstrates reconstruction using the 0th through 4th harmonics. Notice how it approximates the overall shape and critical movements from Figure 1, despite using less than half of the coefficients. The major action components - like the significant drops in Dimensions 1, 3, 5, and 9 - are clearly captured.
Caveat: Fewer DCT harmonics translates to a slightly larger action-sequence reconstruction error. Action accuracy is ever-so-slightly reduced.