DOC Rework Importance of Feature Scaling example #25012
Conversation
|
Weird that the CIs did not start. I merged |
…arn into scaling_importance
Co-authored-by: Christian Lorentzen <[email protected]>
…arn into scaling_importance
Co-authored-by: Guillaume Lemaitre <[email protected]>
…arn into scaling_importance
|
I think all of your comments have been addressed, @glemaitre and @lorentzenchr. |
|
I will have to check the rendering but I think that the proposal is already an improvement. |
| X, y, test_size=0.30, random_state=42 | ||
| ) | ||
| scaled_X_train = scaler.fit_transform(X_train) | ||
|
|
There was a problem hiding this comment.
Optional: We could show the mean value of each feature, or min and max.
|
|
||
| # %% | ||
| # The need for regularization is higher (lower values of `C`) for the data | ||
| # that was not scaled before applying PCA. From the plot we can confirm that |
There was a problem hiding this comment.
Which plot? Is it over- or underfitting?
There was a problem hiding this comment.
By plotting the validation curves I realized that the training and test accuracy overlap too much to make a proper statement about over- or underfitting for the scenario with no standardization.

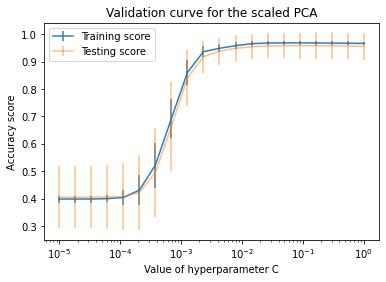
I think that it is better to avoid mentioning over-/underfitting to keep the example as simple as possible.
Co-authored-by: Christian Lorentzen <[email protected]>
 glemaitre
left a comment
glemaitre
left a comment
There was a problem hiding this comment.
Only nitpicks. Otherwise LGTM.
Co-authored-by: Guillaume Lemaitre <[email protected]>
|
I certainly broke the linter with my suggestion. Sorry @ArturoAmorQ |
Co-authored-by: Guillaume Lemaitre <[email protected]>
Co-authored-by: Guillaume Lemaitre <[email protected]> Co-authored-by: Christian Lorentzen <[email protected]>
Co-authored-by: Guillaume Lemaitre <[email protected]> Co-authored-by: Christian Lorentzen <[email protected]>
Co-authored-by: Guillaume Lemaitre <[email protected]> Co-authored-by: Christian Lorentzen <[email protected]>
Co-authored-by: Guillaume Lemaitre <[email protected]> Co-authored-by: Christian Lorentzen <[email protected]>
Reference Issues/PRs
Fixes #12282.
What does this implement/fix? Explain your changes.
This example can benefit from a "tutorialization". In particular, this PR adds a section regarding how nearest neighbors is sensitive to scaling.
Any other comments?
Side effect: Implements notebook style as intended in #22406.