Add listpack encoding for list#11303
Conversation
 zuiderkwast
left a comment
zuiderkwast
left a comment
There was a problem hiding this comment.
Looks good! This is a quick review, i.e. I didn't check the correctness of everything. I assume you made sure everything is covered by tests.
…y in serveClientBlockedOnList (#11326) Mainly fix two minor bug 1. When handle BL*POP/BLMOVE commands with blocked clients, we should increment server.dirty. 2. `listPopRangeAndReplyWithKey()` in `serveClientBlockedOnList()` should not repeat calling `signalModifiedKey()` which has been called when an element was pushed on the list. (was skipped in all bpop commands, other than blmpop) Other optimization add `signal` param for `listElementsRemoved` to skip `signalModifiedKey()` to unify all pop operation. Unifying all pop operations also prepares us for #11303, so that we can avoid having to deal with the conversion from quicklist to listpack() in various places when the list shrinks.
…dule in the future
… some tests for module
Since the quicklist iterator decompresses the current node when it is released, we can no longer decompress the quicklist after we convert the list.
a9aa447 to
4db5be0
Compare
 oranagra
left a comment
oranagra
left a comment
There was a problem hiding this comment.
initial round of review (excluding the tests code)
p.s. maybe add an example about the memory saving to the top comment (e.g. plain case of a list of 10 small numeric items)
|
@oranagra @zuiderkwast |
|
Here is what is seen via perf.
|



|
@oranagra I re-benchmarked using memtier_benchmark with pipeline, but note that I still use |
|
redis-server 100% CPU usage is what we want, isn't it? |
yes, we do want the server (CPU) to be the bottle neck, otherwise, it means something else is the bottleneck and we're not measuring the throughput of redis. |
|
@zuiderkwast @oranagra Yes, that's what I did yesterday (100% cpu usage), normally the new code would be slower than the old code, but when I didn't use |
|
prepare dataset : Unstable This PR with commit This PR without commit The performance degradation is mainly caused by the inline of
|
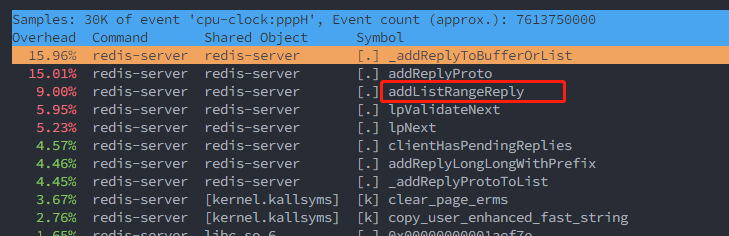
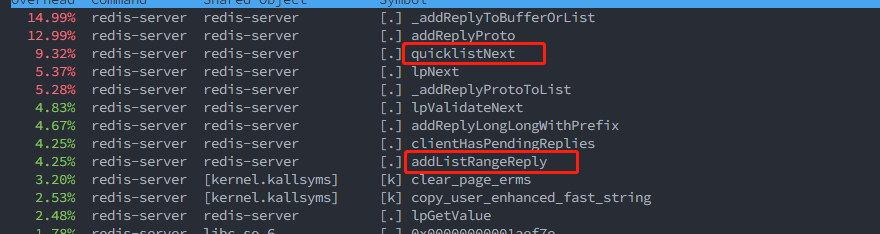
|
@sundb so the difference between your last commit and sundb@9984443 is that you've put each of these in a separate function instead of an if-else in the outer function, and that allowed for a better inlining? i don't think we wanna go deeper in that direction (being one step away from manual inlining of code, or conversion to assembly). bottom line, if what you did was enough to convince the compiler to inline, i'd be ok with that (just ask to write a comment in the code specifying that). |
benchmark: clang 14.0.0
gcc 11.3
|
|
so clang didn't used to do any inlining in that code, and thus unaffected by the change in this PR anyway. |
Yes. |
|
@sundb please update the top comment and let me know when ready to be merged. |
|
@oranagra Updated, mainly the LRANGE part, which seems to bring a huge performance boost when list is listpack encoding, and I verified this boost on my local pc. |
|
@sundb wanted to take a moment thank you again for the time you invested in this project and others! |
…y in serveClientBlockedOnList (redis#11326) Mainly fix two minor bug 1. When handle BL*POP/BLMOVE commands with blocked clients, we should increment server.dirty. 2. `listPopRangeAndReplyWithKey()` in `serveClientBlockedOnList()` should not repeat calling `signalModifiedKey()` which has been called when an element was pushed on the list. (was skipped in all bpop commands, other than blmpop) Other optimization add `signal` param for `listElementsRemoved` to skip `signalModifiedKey()` to unify all pop operation. Unifying all pop operations also prepares us for redis#11303, so that we can avoid having to deal with the conversion from quicklist to listpack() in various places when the list shrinks.
Improve memory efficiency of list keys
## Description of the feature
The new listpack encoding uses the old `list-max-listpack-size` config
to perform the conversion, which we can think it of as a node inside a
quicklist, but without 80 bytes overhead (internal fragmentation included)
of quicklist and quicklistNode structs.
For example, a list key with 5 items of 10 chars each, now takes 128 bytes
instead of 208 it used to take.
## Conversion rules
* Convert listpack to quicklist
When the listpack length or size reaches the `list-max-listpack-size` limit,
it will be converted to a quicklist.
* Convert quicklist to listpack
When a quicklist has only one node, and its length or size is reduced to half
of the `list-max-listpack-size` limit, it will be converted to a listpack.
This is done to avoid frequent conversions when we add or remove at the bounding size or length.
## Interface changes
1. add list entry param to listTypeSetIteratorDirection
When list encoding is listpack, `listTypeIterator->lpi` points to the next entry of current entry,
so when changing the direction, we need to use the current node (listTypeEntry->p) to
update `listTypeIterator->lpi` to the next node in the reverse direction.
## Benchmark
### Listpack VS Quicklist with one node
* LPUSH - roughly 0.3% improvement
* LRANGE - roughly 13% improvement
### Both are quicklist
* LRANGE - roughly 3% improvement
* LRANGE without pipeline - roughly 3% improvement
From the benchmark, as we can see from the results
1. When list is quicklist encoding, LRANGE improves performance by <5%.
2. When list is listpack encoding, LRANGE improves performance by ~13%,
the main enhancement is brought by `addListListpackRangeReply()`.
## Memory usage
1M lists(key:0~key:1000000) with 5 items of 10 chars ("hellohello") each.
shows memory usage down by 35.49%, from 214MB to 138MB.
## Note
1. Add conversion callback to support doing some work before conversion
Since the quicklist iterator decompresses the current node when it is released, we can
no longer decompress the quicklist after we convert the list.
I'm seeing a few issues here: 1. The internal encoding has changed 1 spot to listpack, which is correct from redis/redis#11303, but is missing in the docs at https://redis.io/commands/object-encoding/ (fixed in tests themselves) 1. The `HackyGetPerf` reliably returns 0 now, regardless of how long has passed (e.g. upping iterations tremendously)...this may legit be bugged. 1. `StreamAutoClaim_IncludesDeletedMessageId` expectations are broken, not sure what to make of this yet but it's an odd change to hit between 7.0 and 7.2 versions.
I'm seeing a few issues here that we need to resolve for the upcoming Redis 7.2 release: - [x] The internal encoding has changed 1 spot to listpack, which is correct from redis/redis#11303, but is missing in the docs at https://redis.io/commands/object-encoding/ (fixed in tests themselves) - [x] The `HackyGetPerf` reliably returns 0 now, regardless of how long has passed (e.g. upping iterations tremendously)...this may legit be bugged. - [x] `StreamAutoClaim_IncludesDeletedMessageId` expectations are broken, not sure what to make of this yet but it's an odd change to hit between 7.0 and 7.2 versions. Note: no release notes because these are all test tweaks. Co-authored-by: slorello89 <[email protected]>
…y in serveClientBlockedOnList (redis#11326) Mainly fix two minor bug 1. When handle BL*POP/BLMOVE commands with blocked clients, we should increment server.dirty. 2. `listPopRangeAndReplyWithKey()` in `serveClientBlockedOnList()` should not repeat calling `signalModifiedKey()` which has been called when an element was pushed on the list. (was skipped in all bpop commands, other than blmpop) Other optimization add `signal` param for `listElementsRemoved` to skip `signalModifiedKey()` to unify all pop operation. Unifying all pop operations also prepares us for redis#11303, so that we can avoid having to deal with the conversion from quicklist to listpack() in various places when the list shrinks.
Improve memory efficiency of list keys
## Description of the feature
The new listpack encoding uses the old `list-max-listpack-size` config
to perform the conversion, which we can think it of as a node inside a
quicklist, but without 80 bytes overhead (internal fragmentation included)
of quicklist and quicklistNode structs.
For example, a list key with 5 items of 10 chars each, now takes 128 bytes
instead of 208 it used to take.
## Conversion rules
* Convert listpack to quicklist
When the listpack length or size reaches the `list-max-listpack-size` limit,
it will be converted to a quicklist.
* Convert quicklist to listpack
When a quicklist has only one node, and its length or size is reduced to half
of the `list-max-listpack-size` limit, it will be converted to a listpack.
This is done to avoid frequent conversions when we add or remove at the bounding size or length.
## Interface changes
1. add list entry param to listTypeSetIteratorDirection
When list encoding is listpack, `listTypeIterator->lpi` points to the next entry of current entry,
so when changing the direction, we need to use the current node (listTypeEntry->p) to
update `listTypeIterator->lpi` to the next node in the reverse direction.
## Benchmark
### Listpack VS Quicklist with one node
* LPUSH - roughly 0.3% improvement
* LRANGE - roughly 13% improvement
### Both are quicklist
* LRANGE - roughly 3% improvement
* LRANGE without pipeline - roughly 3% improvement
From the benchmark, as we can see from the results
1. When list is quicklist encoding, LRANGE improves performance by <5%.
2. When list is listpack encoding, LRANGE improves performance by ~13%,
the main enhancement is brought by `addListListpackRangeReply()`.
## Memory usage
1M lists(key:0~key:1000000) with 5 items of 10 chars ("hellohello") each.
shows memory usage down by 35.49%, from 214MB to 138MB.
## Note
1. Add conversion callback to support doing some work before conversion
Since the quicklist iterator decompresses the current node when it is released, we can
no longer decompress the quicklist after we convert the list.
After redis#11303, list will exit with listpack when the number of quicklist nodes are less than 1, cause some list related tests to be always run in listpack encoding. Now let them being run in both encoding.
Implement #11156
Description of the feature
The new listpack encoding uses the old
list-max-listpack-sizeconfig to perform the conversion, which we can think it of as a node inside a quicklist, but without 80 bytes overhead (internal fragmentation included) of quicklist and quicklistNode structs.For example, a list key with 5 items of 10 chars each, now takes 128 bytes instead of 208 it used to take.
Conversion rules
When the listpack length or size reaches the
list-max-listpack-sizelimit, it will be converted to a quicklist.When a quicklist has only one node, and its length or size is reduced to half of the
list-max-listpack-sizelimit, it will be converted to a listpack.This is done to avoid frequent conversions when we add or remove at the bounding size or length.
Interface changes
When list encoding is listpack,
listTypeIterator->lpipoints to the next entry of current entry,so when changing the direction, we need to use the current node (listTypeEntry->p) to
update
listTypeIterator->lpito the next node in the reverse direction.Benchmark
HW: Cloud server, Intel Xeon Cooper Lake, 8cores, 16G mem, Ubuntu 22, GCC 11.3
Listpack VS Quicklist with one node
Use
redis-benchmark -n 1000000 -r 10000000 -q eval 'for i=1,N,1 do redis.call("rpush", "lst:"..ARGV[1], "hellohello") end' 0 __rand_int__to create 1M lists with N entries of 10 chars.Dataset Preparation: Use
redis-benchmark -n 600 -q RPUSH mylist helloto create a list with 600 entries of 10 chars.memtier_benchmark --hide-histogram -n 50000 --pipeline=10 --command=<COMMAND>Both are quicklist
Dataset Preparation: Use
redis-benchmark -q -n 1000000 RPUSH mylist helloto create a list with 1M entries.Without pipeline
memtier_benchmark --hide-histogram -n 50000 --command=<COMMAND>With pipeline
memtier_benchmark --hide-histogram -n 50000 --pipeline=10 --command=<COMMAND>redis-benchmark -q -n 1000000 -t LRANGE COMMANDFrom the benchmark, as we can see from the results
addListListpackRangeReply().Memory usage
Quote from @zuiderkwast
Use a modified version of
debug populateto create 1M lists(key:0~key:1000000) with 5 items of 10 chars ("hellohello") each.Checked using
./redis-cli info memory | grep ^used_memory_humanshows memory usage down by 35.49%.Note
Since the quicklist iterator decompresses the current node when it is released, we can
no longer decompress the quicklist after we convert the list.