[inductor] show performance for each autotune config for a kernel#96248
[inductor] show performance for each autotune config for a kernel#96248shunting314 merged 2 commits intogh/shunting314/23/basefrom
Conversation
[ghstack-poisoned]
🔗 Helpful Links🧪 See artifacts and rendered test results at hud.pytorch.org/pr/96248
Note: Links to docs will display an error until the docs builds have been completed. ❌ 1 FailuresAs of commit 9ce6ad5: NEW FAILURES - The following jobs have failed:
This comment was automatically generated by Dr. CI and updates every 15 minutes. |
|
Do we need a step to first output compiled module? Can we output results of all autotuning configs as we are autotuning them for the first time, running the model? |
yea, currently we split the following steps
This way, we can do step 1 once and do step 2 multiple times as we tune hueristics. If we want, we can also make step 2 being done on the fly while we do step 1 as you mentioned. There is one tricky part here though. We have cache for autotuning result. We would want to ignore the cache if we want to show perf for each config. But each model is usually being run multiple times in our scripts (for warm up or for more stable perf number), we need
Do we want to go this route? |
|
|
||
| if ms > 0.012 and gb_per_s < 650: | ||
| print(colorama.Fore.RED + info_str + colorama.Fore.RESET) | ||
| def get_info_str(ms, prefix=""): |
There was a problem hiding this comment.
btw I'm changing this code a bit to put the kernel name at the end: #96170
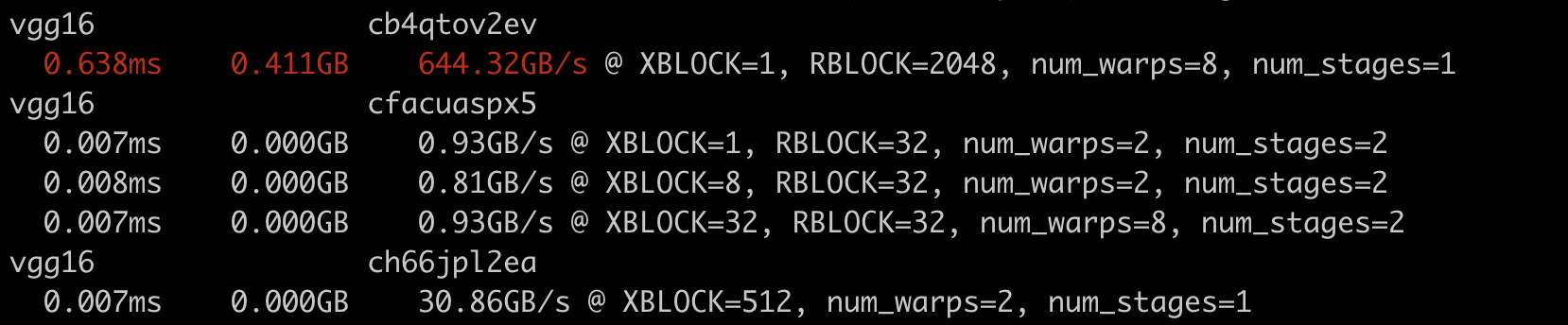
… kernel" Be able to benchmark the perf for each config of each kernel. To use it: 1. run the model with `TORCHINDUCTOR_BENCHMARK_KERNEL` enabled. e.g.: ``` TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only vgg16 --disable-cudagraphs --training ``` Get the path to the compiled module from log, e.g. ``` Compiled module path: /tmp/torchinductor_shunting/mj/cmjv5hyt3uq2v7beqkthcl4ul6fh2luwfzmd4tnrquworcmqz4i3.py ``` 2. run the compiled module directly with the following options: - `-k` to benchmark each kernel - `-c` to benchmark each config for each kernel Example command: ``` TORCHINDUCTOR_BENCHMARK_KERNEL=1 python /tmp/torchinductor_shunting/mj/cmjv5hyt3uq2v7beqkthcl4ul6fh2luwfzmd4tnrquworcmqz4i3.py -kc ``` Sample result: <img width="829" alt="Screenshot 2023-03-06 at 6 05 23 PM" src="https://user-images.githubusercontent.com/52589240/223300934-59a4634b-dfd1-46f5-b964-dc0074535236.png"> cc soumith voznesenskym penguinwu anijain2305 EikanWang jgong5 Guobing-Chen XiaobingSuper zhuhaozhe blzheng Xia-Weiwen wenzhe-nrv jiayisunx peterbell10 desertfire [ghstack-poisoned]
{kind=link}
|
Yeah I think two-step process is fine for now, but for the future the disabling cache for the first run that you described would add nice convenience. |
Make sense. Also you pointed out earlier that there may be some alias between inputs that the randomly generated inputs may not be able to capture. We can improve these for sure if they results into problems. |
|
@pytorch merge -f "the test_tensorboard failure is unrelated" |
|
@pytorchbot merge -f "the test_tensorboard failure is unrelated" |
|
@pytorchbot merge |
|
Can't merge closed PR #96248 |
…r a kernel (#96458) Pull Request resolved: #96458 Approved by: https://github.com/ngimel
Stack from ghstack (oldest at bottom):
Be able to benchmark the perf for each config of each kernel.
To use it:
TORCHINDUCTOR_BENCHMARK_KERNELenabled. e.g.:Get the path to the compiled module from log, e.g.
-kto benchmark each kernel-cto benchmark each config for each kernelExample command:
Sample result:

cc @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire