[Onnx] Add constant folding to ONNX graph during export (Resubmission) #18698
Conversation
|
I see a failing test in one of the runs, but it does not seem related to this change. Also, I cannot repro it locally. @suo - Could you please help take a quick look? |
 houseroad
left a comment
houseroad
left a comment
There was a problem hiding this comment.
briefly scanned the pr. This is really useful. It makes the onnx graph much simpler (and maybe much faster). Thanks!
Will do a thorough pass tomorrow or weekend.
There was a problem hiding this comment.
I am wondering if we enable the flag, how many tests will pass?
@spandantiwari do you want to give it a try?
There was a problem hiding this comment.
i mean locally first, i am wondering how stable it is :-)
|
btw, the failing test should be unrelaed, i have restarted it |
There was a problem hiding this comment.
Looks like a great start! I have only reviewed the constant folding pass so far (not yet at the runTorchBackendForOnnx() or testing stuff).
The pass looks generally correct, so my comments are mostly about making things more robust/idiomatic with the rest of the JIT code. I am going to put some general themes here and refer to them inline.
- On
uniqueName(): we should avoid usinguniqueName()to identify a value. This is fragile because if you ever call setUniqueName("foo"), any value that previously had the name "foo" will get renamed something else (like "foo.1". So values can get arbitrarily renamed by graph transformations, making the name an unreliable way to reference any given value.
We typically use the direct Value* to reference a value. It's guaranteed to be a unique and stable identifier.
- On paramDict: This uses
uniqueName(), which is generally an anti-pattern. However, because the onnx export pass manually assigns names to the parameter values, we can be sure that at the beginning of the pass at least, the names refer to the right values in the graph.
So in keeping with using Value* to reference values (as mentioned in [1]), I think the first thing the pass should do is map that input Value* to its corresponding (name, tensor), and use that mapping as a source of truth. So isParam becomes isParam(Value* v), which just checks whether v is in the std::unordered_map<Value*, std::pair<std::string, at::Tensor>> (feel free to make that data structure whatever you prefer).
At the end of the pass, you can use that same mapping to fix up paramDict to erase the folded parameters.
- It seems like the fact that constants could be
onnx::constantor a parameter value is adding a lot of complexity to the pass. We're doing a lot of tracking for which input is which constant kind.
If you had the data structure I mentioned in [2], isParam() is an easy map lookup and thus you don't have to "save" that info when checking node inputs for constants, which eliminates the need for kindOfLeafNode and its cousin, ConstantLeafNodeKind.
There was a problem hiding this comment.
I think Block::param_node() is what you want here. Confusingly, it is called param_node, which overloads the word "parameter" in this pass 😢
There was a problem hiding this comment.
That's useful. Thanks for pointing to it.
There was a problem hiding this comment.
as mentioned below, blocks have direct accessors for their param nodes: b.param_node()
There was a problem hiding this comment.
you could AT_ASSERT this instead of returning; it should be an invariant that every block has a param node.
There was a problem hiding this comment.
this does not appear to be used anywhere. In general, we discourage converting a Symbol (basically an integer) to its display string unless for printing purposes.
There was a problem hiding this comment.
I think it's clearer to do inputNode->kindOf(attr::value) == AttributeKind::t
There was a problem hiding this comment.
I think instead of adding more outputs to the block's source node (which will add inputs to the graph), you should just insert a new onnx::constant node. Unless you want to expose them as parameters later instead of embedding them in the graph?
There was a problem hiding this comment.
As we discussed, the use of initializers is preferred from ONNX point of view (to distinguish between learnable parameters and real constants.), hence keeping it.
There was a problem hiding this comment.
yeah this is fine. Or you can run an EliminateDeadCode() pass after this and it should clean up the nodes for you
There was a problem hiding this comment.
We are using names/indices a lot here when it's more idiomatic to use Value* directly. (see [1])
There was a problem hiding this comment.
If you have the data structure described in [2] this check would just be:
for input in node:
if isParam(input):
toRemove.push_back(input)
There was a problem hiding this comment.
Similarly, if you had the data structure described in [2], this would be
for v in toRemove:
if !v->hasUses():
name = data_structure[v].first
paramsDict.erase(name)
b2af37f to
31d73d7
Compare
|
@suo - thanks for your thoughtful review. I have revised the PR extensively based on your feedback. Could you please take a look and see if it looks good. |
31d73d7 to
6501c49
Compare
|
@houseroad, @suo - a lot of the failures, maybe most of them, are unrelated. |
|
Doing another run. |
|
@spandantiwari circle ci is down now, let's wait a bit and restart all the tests. |
|
@houseroad - OK. Thanks for letting me know. |
 suo
left a comment
suo
left a comment
There was a problem hiding this comment.
Looks pretty good from my side! Not sure about the onnx->aten implementations, so I've asked @houseroad to eyeball those.
There was a problem hiding this comment.
These changes look good! My one remaining nit is that we shouldn't operate on an entity called sourceNode, since it more clearly expresses your intent to operate on block inputs (as a reminder, block->inputs() is equivalent to param_node()->outputs()).
There was a problem hiding this comment.
@houseroad, can you take a look at these cases? I'm not familiar with the onnx->aten semantics
There was a problem hiding this comment.
Yes, that will be great. Just fyi - I have tested this part on multiple large production models, including BERT, to make sure that these computations are correct, and the numbers match exactly.
There was a problem hiding this comment.
Updated based on @houseroad 's feedback on this section.
There was a problem hiding this comment.
I think it would be clearer for you to return a c10::optionalat::Tensor from this function, and return c10::nullopt in the case that node is not a supported op for constant folding.
There was a problem hiding this comment.
same as above; returning c10::nullopt instead of an empty tensor will express your intent more clearly.
 facebook-github-bot
left a comment
facebook-github-bot
left a comment
There was a problem hiding this comment.
@houseroad has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
Import to check whether it breaks anything internal :-) |
houseroad
left a comment
There was a problem hiding this comment.
Great work. This is very helpful. For testing, we should create test cases to cover 1) Slice, 2) Concat, 3) Transpose, 4) Unsqueeze, 5) No optimization.
It can be added here: https://github.com/pytorch/pytorch/blob/master/test/onnx/test_utility_funs.py
We can just run the optimization pass, and iterate over the graph to check the change after the optimization. Here are some examples how we check the optimizer work in ONNX: https://github.com/onnx/onnx/blob/master/onnx/test/optimizer_test.py#L137
test/onnx/verify.py
Outdated
There was a problem hiding this comment.
can we just call _jit_flatten unconditionally?
There was a problem hiding this comment.
I tried all the tests in test_pytorch_onnx_caffe2.py and nothing seems to break when we call _jit_flatten unconditionally. Conditional removed.
torch/onnx/utils.py
Outdated
There was a problem hiding this comment.
Document the argument do_constant_folding like other arugments?
There was a problem hiding this comment.
Can we change run_model_test's interface as well? both run_actual_test and run_debug_test will need to add do_constant_folding argument.
There was a problem hiding this comment.
Vestige from older version. Removed.
There was a problem hiding this comment.
usually, the optimization pass should not directly throw exception. And axes are optional... we should handle such cases. Probably just skip the node.
There was a problem hiding this comment.
OK. Removed the exception, just skipping node instead.
There was a problem hiding this comment.
check axis exist before running?
torch/onnx/utils.py
Outdated
There was a problem hiding this comment.
We can also check whether the opset is supported by our constant folding. Op spec may change, and the optimization may not be applicable any more.
There was a problem hiding this comment.
Yes, good point. Now checking for opset version (opset 9).
There was a problem hiding this comment.
can we extract this as a helper function?
There was a problem hiding this comment.
We can put everything into anonymous namespace except ConstantFoldONNX. So they don't need to be static i think.
There was a problem hiding this comment.
I think both are viable and have the same effect. But your suggestion is cleaner. Updated with anonymous namespace.
fabd6d3 to
fed8e27
Compare
|
@houseroad and @suo - Thanks for your feedbacks. I have updated the PR. Could you please review and see if this is good for merge. |
@houseroad - As per your suggestion, I have added tests in I could not add test for individual ops because if we create a minimal model with a given op, then the Between the two test points added to |
facebook-github-bot
left a comment
There was a problem hiding this comment.
@houseroad has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
7514985 to
4954cb0
Compare
|
@houseroad - as per your suggestion, I have now added unit tests for each individual node type supported for constant folding ( @houseroad and @suo - could you please review and see if this is ready for merging. Thanks! |
facebook-github-bot
left a comment
There was a problem hiding this comment.
@houseroad has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
The changes look good to me overall, we just need to figure out why |
|
Wasn't able to repro the test failure on my side. But based on a hunch, I updated the PR with a fix related to |
|
@houseroad, @suo - Fingers crossed, but the failing platform from previous runs is passing now. The issue seems to have been in setting the opset version using I will wait for the all the runs to finish, and if all green I will update the PR to clean up the debugging instrumentation I added in last commit. |
|
@spandantiwari the tests are passing now :-) |
@houseroad - Yes. And I have updated the PR to clean up any debug-related messages too. |
|
lint please |
facebook-github-bot
left a comment
There was a problem hiding this comment.
@houseroad has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
@suo, friendly ping for another review :-) |
|
This looks good to merge |
|
@houseroad merged this pull request in a64cce3. |
Summary: Rewritten version of pytorch/pytorch#17771 using graph C++ APIs. This PR adds the ability to do constant folding on ONNX graphs during PT->ONNX export. This is done mainly to optimize the graph and make it leaner. The two attached snapshots show a multiple-node LSTM model before and after constant folding. A couple of notes: 1. Constant folding is by default turned off for now. The goal is to turn it on by default once we have validated it through all the tests. 2. Support for folding in nested blocks is not in place, but will be added in the future, if needed. **Original Model:**  **Constant-folded model:** 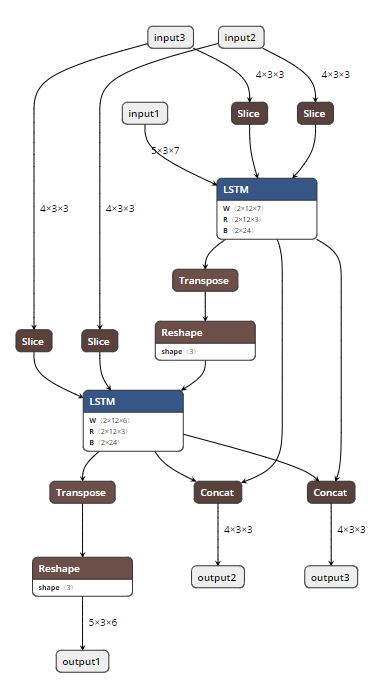 Pull Request resolved: pytorch/pytorch#18698 Differential Revision: D14889768 Pulled By: houseroad fbshipit-source-id: b6616b1011de9668f7c4317c880cb8ad4c7b631a
{kind=link}
{kind=link}
|
@houseroad @suo - thank you for your review and all the work on this. Much appreciated. |
Summary: This is a follow up PR of pytorch#18698 to lint the code using clang-format. Pull Request resolved: pytorch#19398 Differential Revision: D14994517 Pulled By: houseroad fbshipit-source-id: 2ae9f93e66ce66892a1edc9543ea03932cd82bee
…rch#18698) Summary: Rewritten version of pytorch#17771 using graph C++ APIs. This PR adds the ability to do constant folding on ONNX graphs during PT->ONNX export. This is done mainly to optimize the graph and make it leaner. The two attached snapshots show a multiple-node LSTM model before and after constant folding. A couple of notes: 1. Constant folding is by default turned off for now. The goal is to turn it on by default once we have validated it through all the tests. 2. Support for folding in nested blocks is not in place, but will be added in the future, if needed. **Original Model:**  **Constant-folded model:**  Pull Request resolved: pytorch#18698 Differential Revision: D14889768 Pulled By: houseroad fbshipit-source-id: b6616b1011de9668f7c4317c880cb8ad4c7b631a
Summary: This is a follow up PR of pytorch#18698 to lint the code using clang-format. Pull Request resolved: pytorch#19398 Differential Revision: D14994517 Pulled By: houseroad fbshipit-source-id: 2ae9f93e66ce66892a1edc9543ea03932cd82bee
| assert node.kind() != "onnx::Concat" | ||
| assert node.kind() != "onnx::Cast" | ||
| assert node.kind() != "onnx::Constant" | ||
| assert len(list(graph.nodes())) == 1 |
There was a problem hiding this comment.
@spandantiwari, this is a very late comment, but I don't understand what this test is doing. To me, it looks like you are tracing a program that returns a single constant, and what I expect to happen here is to get a graph with a single node that returns a constant. But what I get instead is:
graph(%8 : Float(1, 3),
%9 : Float(2, 3)):
%6 : Float(2, 3) = onnx::Add(%8, %9), scope: ConcatModule # test/onnx/test_utility_funs.py:143:0
return (%6)
This is extremely unexpected! What happened to the constant folding?
There was a problem hiding this comment.
After filing #28834 I think I understand why the output is the way it is. But I still think the way this test is written, versus the way the optimization pass is written, is very strange. According to the optimization pass, you never move just Constant nodes to the initialization graph. But then you assert that the optimized output should never have Constant node in it. Which one is it? In the current master implementation, this "happens" to work because every constant node always has a cast immediately after it. But they really shouldn't!
There was a problem hiding this comment.
@ezyang - I would love to be able to improve this test point (or constant folding for that matter), but I am not sure I fully understand the question.
First, as I asked in #28834 also (I saw that issue before I saw your comment here), I am not sure I understand what is meant by initialization graph.
The goal of this test is simple. I have a graph where I have two constants feeding into a Concat node, followed by an Add op. Regarding the Cast op, I recall that they were not intentionally part of this test, but appeared in the graph when we set _disable_torch_constant_prop=True. However, since Cast is supported in constant folding they get folded too. Anyway, this test was supposed to test that the Concat node is constant folded (together with Cast op). The new folded constant after collapsing the onnx::Constant and the onnx::Concat node shows up as onnx initializer and not onnx::Constant in the final ONNX graph. This is why we check that there are no onnx::Constant, cast, or concat nodes.
As an aside - looking back at this I feel this test would be better if I use the input x to the forward() method in the model. I think it will make things clearer. I will try to update the test.
There was a problem hiding this comment.
what I expect to happen here is to get a graph with a single node that returns a constant.
Forgot to mention - we do not support Add in constant folding yet, but if we did you are right in that the Add op should have been folded too. You would be left with a single intializer in the final ONNX graph.
There was a problem hiding this comment.
LEt's move this discussion to the issue
Rewritten version of #17771 using graph C++ APIs.
This PR adds the ability to do constant folding on ONNX graphs during PT->ONNX export. This is done mainly to optimize the graph and make it leaner. The two attached snapshots show a multiple-node LSTM model before and after constant folding.
A couple of notes:
Original Model:


Constant-folded model: