TensorIterator cuda launch configs update #16224
Conversation
Summary: Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible block dimension to improve efficiency for reduction cases with small fast dimension. Previously TensorIterator launches blocks with fixed 32x16 threads. For cases like: import torch torch.randn(2**20, 4, device='cuda').sum(0) The fixed launch config does handle coalesced memory access efficiently. Updated launch configure enables flexible block dimension. Combining with improved reduction scheme (using flexible vertical / horizontal reduction instead of limited warp / block reduction in the old code), it ensures optimal memory access pattern even with reduction on dimension with small stride. Possible future improvements: 1. Precise dynamic shared memory allocation. 2. Using warp shuffle for vertical (block_y) reduction.
|
This is my monkey benchmarking. Notice the perf gain for small fast changing dimensions.
|
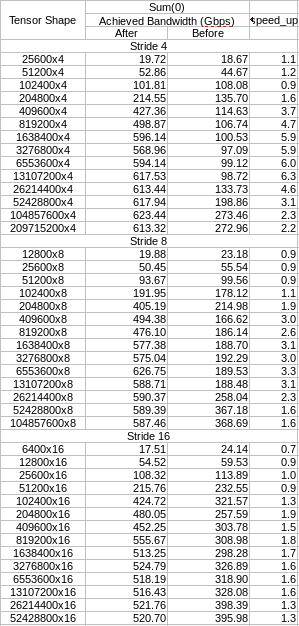
|
For visibility @ngimel @umanwizard @colesbury |
 facebook-github-bot
left a comment
facebook-github-bot
left a comment
There was a problem hiding this comment.
@umanwizard has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
We are getting this error on some internal builds: |
|
My bad. |
facebook-github-bot
left a comment
There was a problem hiding this comment.
@umanwizard has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
I'm somewhat worried about the slowdowns. Why are we getting rid of warp reductions? Aren't those supposed to be fast? |
|
I'm not getting rid of warp reduction. Keeping them as necessary for the old launch config where block dimension as 32x16: https://github.com/pytorch/pytorch/pull/16224/files#diff-662693ef7b7f32fa32d7179b6614fc16R379 Renaming warp_reduce to block_x_reduce because as we have flexible block dimension. Given the cases where blockDim.x > 32, it requires a hybrid of shared memory reduction and warp reduction, because not all threads are in the same warp. |
|
Test failure doesn't seem to be relevant. Merging ToT to see if it goes away |
facebook-github-bot
left a comment
There was a problem hiding this comment.
@soumith is landing this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
Summary: Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible block dimension to improve efficiency for reduction cases with small fast dimension. Previously TensorIterator launches blocks with fixed 32x16 threads. For cases like: import torch torch.randn(2**20, 4, device='cuda').sum(0) The fixed launch config does handle coalesced memory access efficiently. Updated launch configure enables flexible block dimension. Combining with improved reduction scheme (using flexible vertical / horizontal reduction instead of limited warp / block reduction in the old code), it ensures optimal memory access pattern even with reduction on dimension with small stride. Possible future improvements: 1. Precise dynamic shared memory allocation. 2. Using warp shuffle for vertical (block_y) reduction. Pull Request resolved: pytorch/pytorch#16224 Differential Revision: D13806753 Pulled By: soumith fbshipit-source-id: 37e45c7767b5748cf9ecf894fad306e040e2f79f
|
just fyi @jjsjann123 this is being reverted, we are seeing "illegal memory exception" and |
|
I think I figured out the issue. It's me overlooking the old heuristics for inter-block vs inter-warp reduction. Surprised this doesn't get caught by CI tests. Working on a fix. Will also add tests that covers it. |
update:
1. global_reduce check for should_block_y_reduce first.
This avoids the enabling global_reduce without block_y_reduce. Leading to
accessing shared memory during global reduce without allocation.
2. updating block_y_reduce heuristics. Improves perf on tiny tensors
3. adding test case covering old cases where illegal memory access might occur
TensorIterator cuda launch configs update (pytorch#16224)
Summary:
Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible
block dimension to improve efficiency for reduction cases with small fast
dimension.
Previously TensorIterator launches blocks with fixed 32x16 threads.
For cases like:
import torch
torch.randn(2**20, 4, device='cuda').sum(0)
The fixed launch config does handle coalesced memory access efficiently.
Updated launch configure enables flexible block dimension. Combining with
improved reduction scheme (using flexible vertical / horizontal reduction
instead of limited warp / block reduction in the old code), it ensures optimal
memory access pattern even with reduction on dimension with small stride.
Possible future improvements:
1. Precise dynamic shared memory allocation.
2. Using warp shuffle for vertical (block_y) reduction.
Pull Request resolved: pytorch#16224
Summary:
update:
1. global_reduce check for should_block_y_reduce first.
This avoids the enabling global_reduce without block_y_reduce. Leading to
accessing shared memory during global reduce without allocation.
2. updating block_y_reduce heuristics. Improves perf on tiny tensors
3. adding test case covering old cases where illegal memory access might occur
TensorIterator cuda launch configs update (#16224)
Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible
block dimension to improve efficiency for reduction cases with small fast
dimension.
Previously TensorIterator launches blocks with fixed 32x16 threads.
For cases like:
import torch
torch.randn(2**20, 4, device='cuda').sum(0)
The fixed launch config does handle coalesced memory access efficiently.
Updated launch configure enables flexible block dimension. Combining with
improved reduction scheme (using flexible vertical / horizontal reduction
instead of limited warp / block reduction in the old code), it ensures optimal
memory access pattern even with reduction on dimension with small stride.
Possible future improvements:
1. Precise dynamic shared memory allocation.
2. Using warp shuffle for vertical (block_y) reduction.
Pull Request resolved: #16224
Pull Request resolved: #17040
Differential Revision: D14078295
Pulled By: umanwizard
fbshipit-source-id: ecc55054a5a4035e731f0196d633412225c3b06c
Summary:
update:
1. global_reduce check for should_block_y_reduce first.
This avoids the enabling global_reduce without block_y_reduce. Leading to
accessing shared memory during global reduce without allocation.
2. updating block_y_reduce heuristics. Improves perf on tiny tensors
3. adding test case covering old cases where illegal memory access might occur
TensorIterator cuda launch configs update (#16224)
Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible
block dimension to improve efficiency for reduction cases with small fast
dimension.
Previously TensorIterator launches blocks with fixed 32x16 threads.
For cases like:
import torch
torch.randn(2**20, 4, device='cuda').sum(0)
The fixed launch config does handle coalesced memory access efficiently.
Updated launch configure enables flexible block dimension. Combining with
improved reduction scheme (using flexible vertical / horizontal reduction
instead of limited warp / block reduction in the old code), it ensures optimal
memory access pattern even with reduction on dimension with small stride.
Possible future improvements:
1. Precise dynamic shared memory allocation.
2. Using warp shuffle for vertical (block_y) reduction.
Pull Request resolved: pytorch/pytorch#16224
Pull Request resolved: pytorch/pytorch#17040
Differential Revision: D14078295
Pulled By: umanwizard
fbshipit-source-id: ecc55054a5a4035e731f0196d633412225c3b06c
Summary:
update:
1. global_reduce check for should_block_y_reduce first.
This avoids the enabling global_reduce without block_y_reduce. Leading to
accessing shared memory during global reduce without allocation.
2. updating block_y_reduce heuristics. Improves perf on tiny tensors
3. adding test case covering old cases where illegal memory access might occur
TensorIterator cuda launch configs update (pytorch#16224)
Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible
block dimension to improve efficiency for reduction cases with small fast
dimension.
Previously TensorIterator launches blocks with fixed 32x16 threads.
For cases like:
import torch
torch.randn(2**20, 4, device='cuda').sum(0)
The fixed launch config does handle coalesced memory access efficiently.
Updated launch configure enables flexible block dimension. Combining with
improved reduction scheme (using flexible vertical / horizontal reduction
instead of limited warp / block reduction in the old code), it ensures optimal
memory access pattern even with reduction on dimension with small stride.
Possible future improvements:
1. Precise dynamic shared memory allocation.
2. Using warp shuffle for vertical (block_y) reduction.
Pull Request resolved: pytorch#16224
Pull Request resolved: pytorch#17040
Differential Revision: D14078295
Pulled By: umanwizard
fbshipit-source-id: ecc55054a5a4035e731f0196d633412225c3b06c
Summary:
Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible
block dimension to improve efficiency for reduction cases with small fast
dimension.
Previously TensorIterator launches blocks with fixed 32x16 threads.
For cases like:
import torch
torch.randn(2**20, 4, device='cuda').sum(0)
The fixed launch config does handle coalesced memory access efficiently.
Updated launch configure enables flexible block dimension. Combining with
improved reduction scheme (using flexible vertical / horizontal reduction
instead of limited warp / block reduction in the old code), it ensures optimal
memory access pattern even with reduction on dimension with small stride.
Possible future improvements: