DeBERTa models produce nonsense fill-mask output #22790
Description
System Info
Python version: 3.8.15
Transformers version: 4.24.0
Who can help?
Information
- The official example scripts
- My own modified scripts
Tasks
- An officially supported task in the
examplesfolder (such as GLUE/SQuAD, ...) - My own task or dataset (give details below)
Reproduction
Both on the HF website and using transformers in Python scripts/interpreter, the DeBERTa models seem to produce nonsense outputs in a fill-mask task. This is demonstrated below using a fill-mask pipeline for ease of reproduction, but the same thing happens even when calling the models manually and inspecting the logits. I demonstrate with one model, but the other microsoft/deberta masked language models appear to have the same issue (i.e., not the ones fine-tuned on mnli or whatever, which I wouldn't test against).
>>> from transformers import pipeline
>>> test_sentence = 'Do you [MASK] the muffin man?'
# for comparison
>>> bert = pipeline('fill-mask', model = 'bert-base-uncased')
>>> print('\n'.join([d['sequence'] for d in bert(test_sentence)]))
do you know the muffin man?
do you remember the muffin man?
do you mean the muffin man?
do you see the muffin man?
do you recognize the muffin man?
>>> deberta = pipeline('fill-mask', model = 'microsoft/deberta-v3-large')
>>> print('\n'.join([d['sequence'] for d in deberta(test_sentence)]))
Do you Moisturizing the muffin man?
Do you Kagan the muffin man?
Do youULA the muffin man?
Do you闘 the muffin man?
Do you aplica the muffin man?Here's a screenshot from the HF website for the same model (microsoft/deberta-v3-large):
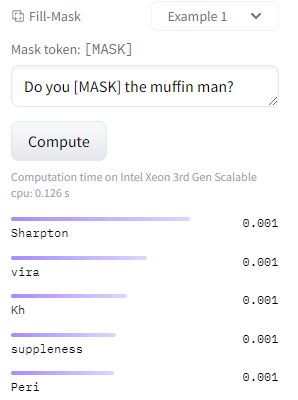
Based on the paper and the documentation on the model cards, it seems like these should be able to be used for masked language modeling out of the box since they were pre-trained on it, but they're clearly not doing a good job of it. Am I missing something about why these models shouldn't be used for MLM without fine-tuning, or is there a bug with them?
Expected behavior
I'd expect sensible predictions for masked token locations (assuming these models can indeed be used for that without additional fine-tuning).