Internal worker state transitions #4413
Description
In #4360 various deadlock situations are investigated where some of them are connected to the way valid states and state transitions of the worker[1] TaskState objects are defined.
The current documentation is slightly outdated since dependencies and runnable tasks where consolidated in #4107. The current state transitions are now following the pipeline (omitting long-running, error, constrained for the sake of clarity [2])
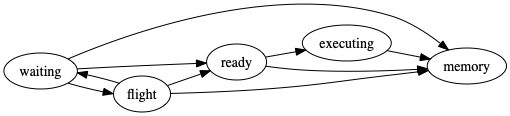
What's remarkable about this transition pipeline is that virtually all states allow a transition to memory and there are multiple allowed transition paths which are only allowed in very specific circumstances and only upon intervention via the scheduler. For instance, a task in state flight may be transitioned via ready to executing but this is only possible if the worker actually possess the knowledge about how to execute a given task, i.e. the TaskState object possesses a set attribute runspec. This attribute is usually only known to the worker if the scheduler intents for this worker to actually execute the task. This transition path is, however, allowed since a dependency, i.e. a task without the knowledge of how to compute it, is reassigned by the scheduler for computation on this worker. This may happen if the worker where the task was intended to be computed on originally is shut down.
This ambiguity is essentially introduced by not distinguishing between dependencies and runnable tasks anymore. What I would propose is to make this distinction explicit in the state of the tasks. Consider the following pipeline
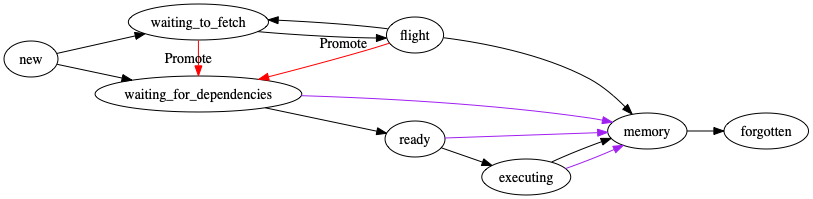
Every task starts off in new. This is effectively a dummy state and could be omitted. It represents a known task which hasn't been classified into "can the worker compute this task or not". Based on the answer of this question it is put into the states
waiting_for_dependencies : This task is intended to be computed by this worker. Once all dependencies are available on this worker, it is supposed to be transitioned to ready to be queued up for execution. (No dependencies is a special subset of this case)
waiting_to_fetch : This task is not intended to be computed on this worker but the TaskState on this worker merely is a reference to a remote data key we are about to fetch.
The red transition is only possible via scheduler interference once the scheduler reassigns a task to be computed on this worker. This is relatively painless as long as the TaskState is in a valid state (in particular runspec is set)
Purple is similar but in this case the worker was already trying to fetch a dependency. It is similar to the red transition with the exception that a gather_dep was already scheduled and this worker is currently trying to fetch a result. If that was actually successful we might be in a position where we fast track the "to be executed" task.
I believe defining these transitions properly is essential and we should strive to set up a similar, if not identical, state machine as in the scheduler (w/ recommendations / chained state transitions). This is especially important since there are multiple data structures to keep synchronized (e.g. Worker.ready, Worker.data_needed, Worker.in_flight_workers to name a few) on top of the tasks themselves.
Last but not least, there have been questions around how Worker.release_key works, when it is called and what data is actually stored in Worker.data (is it always a subset of tasks or not). I believe settling the allowed state transitions should help settle these questions.
Alternative: Instead of implementing red/purple we could just reset to new and start all transitions from scratch. that would help reduce the number of edges/allowed transitions but would pose similar problems as the purple path in case the gather_dep is still running
My open questions:
- How would speculative task assignment fit into this?
- How is work stealing mapped here? (That's kind of the reverse of red/purple, isn't it?)
- Do Actors impact this in any kind of way?
cc @gforsyth
[1] The TaskState objects of the scheduler follow a different definition and allow different state transitions. I consider the consolidation of the two out of scope for this issue.
[2] Especially the state error is very loosely defined and tasks can be transitioned to error from almost every start state
Possibly related issues
#4724
#4587
#4439
#4550
#4133
#4721
#4800
#4446