Add unit state cache to mitigate the iteration between fleet and systemd - dbus #1418
Conversation
|
I performed a different experiment, this time we had 6 inactive units per host with a total of 18 inactive units in the whole cluster. We used our benchmarking tool called fleemmer (as done above) and deployed 900 units, which were stopped/destroy after a fixed timeout. CPU usage WITHOUT unit state cache:
CPU usage using our implementation of an UNIT STATE CACHE:
CONCLUSION: There is a slight increment in the CPU usage due to the inactive units approx. 7-8% CPU usage increment. However, the CPU usage always increases in a higher percentage when scheduling units how shown in the spikes. |


|
@hectorj2f thank you very much for the detailed information, we will read it again carefully and try to push it forward. For the moment I'm just a bit curious, you say "We decided to build a cache to reduce the amount of calls from systemd to dbus. Fleet periodically performs operations to gather the state of the units in the cluster, so for each inactive unit located in a host, a read operation is triggered to obtain the state from dbus. Therefore, you could have an impression of how this operation could use more resources than the desired." and later you also say that it can be solved by updating go-dbus, for me that's the best solution. Your patches seem clean and they don't touch lot of code. However I would first ask if we can support notification from systemd ? subscribe() then get UnitNew() and UnitRemoved() signals https://www.freedesktop.org/wiki/Software/systemd/dbus/ systemd supports notification and it should not trigger any load at all... is this currently not possible ? Thank you! |
|
@tixxdz Subscriptions are already used in the function The dbus Subscribe() function you mentioned, it reacts against any systemd dbus event. I believe it is not what we would want. We want to define subscribers for specific fleet units, (similar to what subscriptor set offers) but in a smart way. The subscribers should be asynchronous to report whenever a state changes instead of done via for loops querying all the states and filtering the units. Indeed, my long-term proposal was to refactor go-dbus to report state updates only when the state changes and not by constantly querying its state. |
|
For a little history: this was previously purely event-driven - similar to how we previously used etcd - but as with etcd, we could end up missing events and have no way to sanely recover, so we ended up moving this to the reconciliation model as well. |
|
@jonboulle Thanks for the information :). Then it makes more sense to me cause it made it better regarding data consistency and failure recovery. Unfortunately we also found some situations on which fleet had a different state than the one in systemd, but that is another issue. @jonboulle Do you think the current solution could have similar problems ? or do you refer to the implementation of dbus watchers ? This PR aims to reduce the workload caused by this periodic unit state calls for all the subscribed units. @tixxdz the state of the subscribed units is collected via dbus |
|
Do you see any blocker or potential issue coming out when using this caching approach @jonboulle ? |
|
Hi @hectorj2f Thank you! |
bbfca9a to
dc449f3
Compare
|
@tixxdz Done. However there is an error that seems to be unrelated :/ . |
|
ping @tixxdz |
|
@hectorj2f yes thank you for the update! the failing is due to travis-ci. Hopefully we will give it more time next week as it is in the 0.13 priority. Thanks! |
dc449f3 to
e905d4b
Compare
e905d4b to
d0221a8
Compare
|
@tixxdz test are passing, what's next ? |
|
@hectorj2f to be honest, I think the main hurdle is that we are still pretty new to this, and it's hard for any of us to judge whether such a change is indeed a good idea... (While @jonboulle doesn't really have the time to think about this too much I guess.) I haven't really looked into this myself; one thing that comes to mind though is that AIUI the cache gets out of sync if a unit state changes because of "external" factors, not at a direct request of fleet?... How does that deal with crashing units for example, or unit dependencies fleet is not aware of? BTW, this is a bit tangential, but there is one bit in your original message I do not agree with: "Obviously we declined this solution as it required the modification of third party software used by fleet." To quote a certain Lennart Poettering: "You own the entire stack." This is free software -- you never have to take limitations in underlying infrastructure as granted, and work around them. Fix problems at the source. |
|
@hectorj2f hi sorry for delay, we had to handle some other issues, at the same time I'm reviewing this issue #478 since it relates the one exposed here, just trying to get the whole context from your comments and @jonboulle ones ;-) |
|
@tixxdz Thanks
@antrik Well, that has a very simple answer. This cache won't interfere as the state of the systemd units remains with the same logic than before. Please have a look on line 242 in |
fleetd/fleetd.go
Outdated
| cfgset.Bool("disable_watches", false, "Disable the use of etcd watches. Increases scheduling latency") | ||
| cfgset.Bool("verify_units", false, "DEPRECATED - This option is ignored") | ||
| cfgset.String("authorized_keys_file", "", "DEPRECATED - This option is ignored") | ||
| cfgset.Bool("enable_unitstate_cache", true, "Enable an unit state cache to minimize the systemd and dbus communication overhead.") |
There was a problem hiding this comment.
Could this be made false by default ?
There was a problem hiding this comment.
Yes at least when it's merged we let it false by default others can run it if they want and after some time it can be switch to true. Thanks
e37c1b4 to
e03de2e
Compare
|
@tixxdz PRs seem to fail. Please, ping me when it is fixed to push it again. Thx |
e03de2e to
76990b6
Compare
|
@hectorj2f just an update, we are making the functional tests run when state cache is set and not, will merge the functional test change first, then later this PR. I may add some minor comments. Thank you! |
|
So more notes:
So we have a new cache_hashes with two fields where we unload the unit we don't remove it but we put the state into the inactive state, the other code should check if the state is always active and the addition should check if the state is inactive. This will allow us to use the same cache but in the other way I'm not sure if it will really scale ? cause with the current implementation we just forget about the old cache https://github.com/coreos/fleet/pull/1418/files#diff-561bbb797eb2f941c1384271efe28c0bR273 which will be collected and the
It will allows us to hide the logic and maybe improve the cache later ? So 1) needs further thinking, do you think it makes sense ? I need more time to came up with something that can work, otherwise just use what's already here and improve it later. And for 2) and 3) it would be awesome to update the PR based on these! and just matter of time before we merge this ;-) Thanks for your patience. |
|
Also, squashing the commits where it's possible would be nice. btw we merged more functional tests for unit states these past days, I guess that's enough or do you think that there are corner cases that can be added to assert the functionality ? |
|
@tixxdz I like the idea but I need to think about the corner cases. Regarding 2) and 3), they are feasible and understandable :). |
|
@hectorj2f for 1) if it's too much, then please don't bother. Without it, the feature will be an option disabled by default, later if it can be done then it could be enabled by default for every one. At the same time if you use or depend on this PR #1556 would be nice to test it, confirm. Thank you! |
|
@hectorj2f I'm not quite sure, but I suppose this improvement should be done in low-level side. I've started to implement systemd-dbus optimizations withing this PR: #1564 |
|
@kayrus My concern are mainly the |
|
@hectorj2f I've reworked my patch a bit and created systemd pull request. If you wish to test systemd v225 which is currectly used by stable CoreOS, please use this patch: endocode/systemd@1fdb12b I'll try to implement new d-bus method which will optimize |
Instead of retrieving all properties for each units, we will pass list of units to GetUnitsStates method and receive units' states. Resolves coreos/fleet#1418
This new method returns information by unit names. Instead of ListUnitsByPatterns this method returns information of inactive and even unexisting units. Moved dbus unit reply logic into a separate shared function. Resolves coreos/fleet#1418
This new method returns information by unit names. Instead of ListUnitsByPatterns this method returns information of inactive and even unexisting units. Moved dbus unit reply logic into a separate shared function. Resolves coreos/fleet#1418
|
Let's consider this on hold in favour of #1564 |
Unit state cache:
Motivation: Inactive units induce an overload to systemd-dbus communication which linearly increases proportionally to the amount of existing inactive units. Therefore, we decided to research about solutions to minimize the workload of fleet caused by this issue. We decided to build a cache to reduce the amount of calls from systemd to dbus. Fleet periodically performs operations to gather the state of the units in the cluster, so for each inactive unit located in a host, a read operation is triggered to obtain the state from dbus. Therefore, you could have an impression of how this operation could use more resources than the desired.
Nevertheless, we thought about another optimal solution during the development of this cache. This solution requires to modify the
go-dbuslibrary implementation to provide an event-driven mechanism. This event-driven mechanism would notify every time an operation affects the state of a unit. These notifications would enable to know when the state of a unit change without having to constantly query systemd to get its state. Obviously we declined this solution as it required the modification of third party software used by fleet.Implementation
We added a new flag
enable_unitstate_cachethat will activate the usage of the unit state cache and therefore to minimize the usage of the system resources. The unit state cache is used to give the state of inactive units whenever no operation has been recently triggered over them. Otherwise the system will query to dbus in order to get its final state. Consequently, we register operations that are being triggered over the units in order to decide whether or not to use its cached state.Test scenario:
Metrics analyzed:
Savings deducted from these experiments:
A brief and quick summary:
Experiment 1:
Without any iteration in the cluster, we evaluated how 3 inactive units could use the system resources of a host.
CPU usage of our implementation using an UNIT STATE CACHE:

#### Memory usage of our implementation using an UNIT STATE CACHE:
#### CPU usage WITHOUT unit state cache:
#### Memory usage WITHOUT unit state cache:As shown above, there is a slight difference caused by these periodic queries to dbus in order to get the state of inactive units.
Experiment 2:
We used a benchmarking tool that starts 900 units in the cluster, and consequently stop+destroy all after a timeout.
CPU usage of our implementation using an UNIT STATE CACHE:
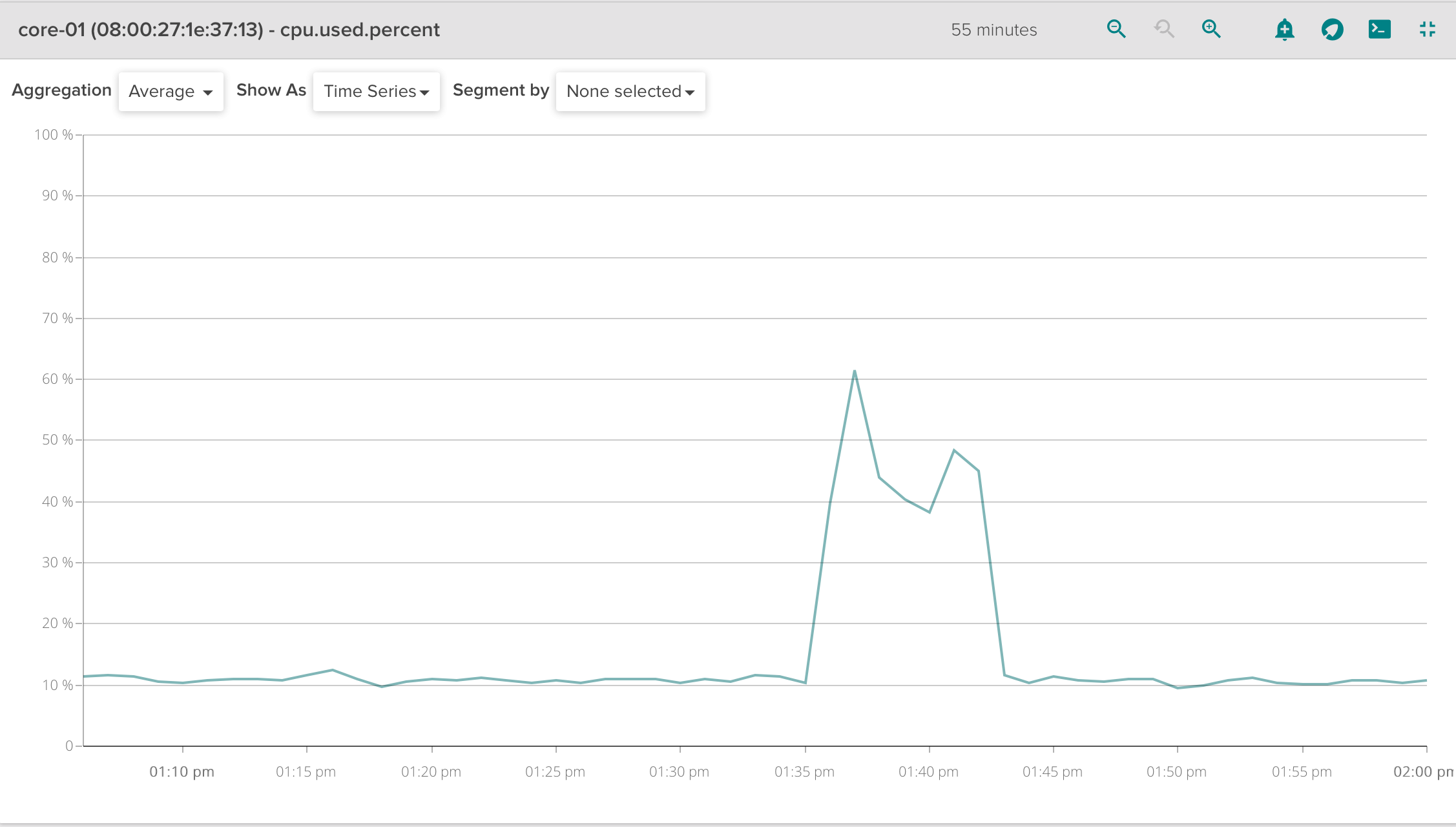
#### CPU usage WITHOUT unit state cache: ##
### Memory usage of our implementation using an UNIT STATE CACHE:
### Memory usage WITHOUT unit state cache: ##
### FS bytes used of our implementation using an UNIT STATE CACHE:
### FS bytes used WITHOUT unit state cache: ##
### Capacity usage of our implementation using an UNIT STATE CACHE: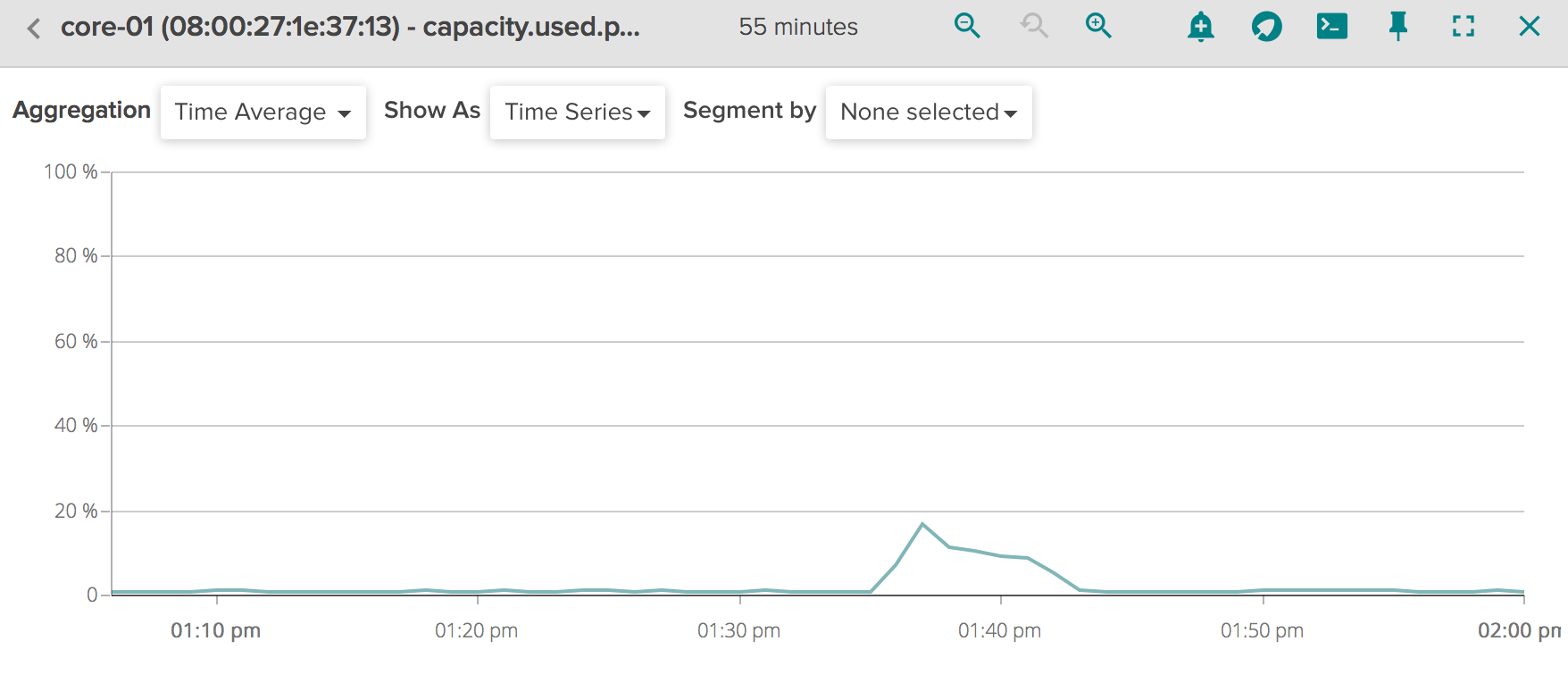
### Capacity used WITHOUT unit state cache: ##
### Net bytes IN of our implementation using an UNIT STATE CACHE:
### Net bytes IN WITHOUT unit state cache: ##
### Net bytes OUT of our implementation using an UNIT STATE CACHE: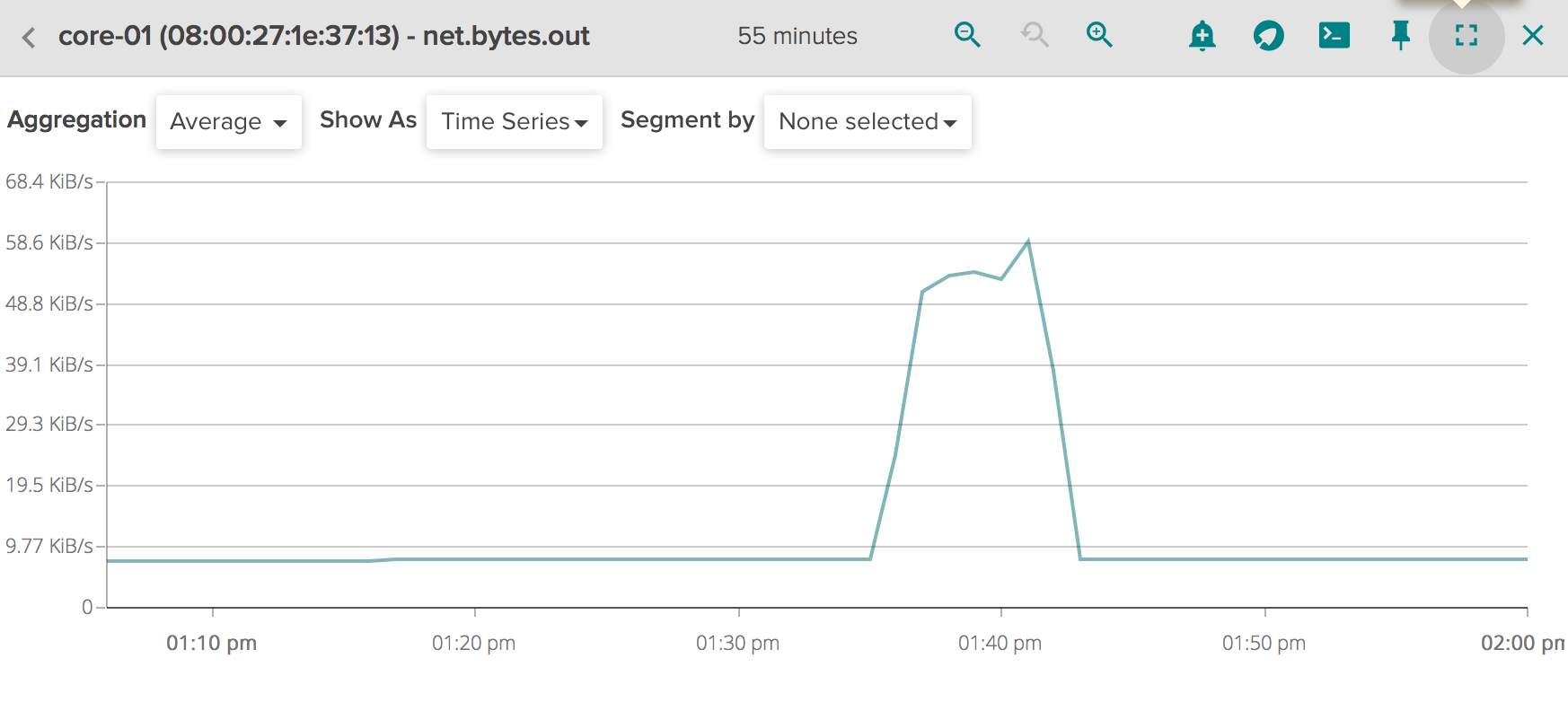
### Net bytes OUT WITHOUT unit state cache:Net bytes total of our implementation using an UNIT STATE CACHE:

### Net bytes total WITHOUT unit state cache:NOTE: As shown in above Figures (CPU usage, Mem usage, ...) there are two spikes that represent the start operation and the stop/destroy operation which is performed after a fixed timeout.