fix: iswt/idwt performance regression#162
Conversation
|
Good effort, will review tomorrow. I'm not a huge fan of the Perhaps this should be re-based onto the ASV commit, with some appropriate benchmarks? That would give a nice way of analysing the performance impact. I'd started working on moving SWT to C, and decided I should get benchmarks running before that and then got sucked into the setuptools hole. It's still planned. |
|
Would it work (and help) if only first array element is checked with |
|
According to the numpy docs, |
|
when I did line profiling, it did not seem like I still have a line profiling output up on the screen from after the first commit above and the The code now has new features relative to v0.2.2 and those are not entirely without cost:
|
|
Another micro-optimization would be to move the axis checks into the |
|
@kwohlfahrt |
|
The reason I'm asking is that when I profiled, the |
|
Here is an ASV plot of the iswt benchmark proposed in #158. These plots show 4 commits with the leftmost being current master (10b13cb) and the next three are the 3 commits proposed above. The biggest gain which (for both Python 2 and 3) is due to the first commit above. For some reason the third commit above has a substantial benefit on Python 3, but not so much on 2. Here is Here is The first commit here also improves the Here is the and Based on these results it seems avoiding declaring as a memory view followed by np.asarray() has a pretty substantial benefit. I don't think there is a strong need for memory views as we are not using any fancy indexing or anything in the cython code for |
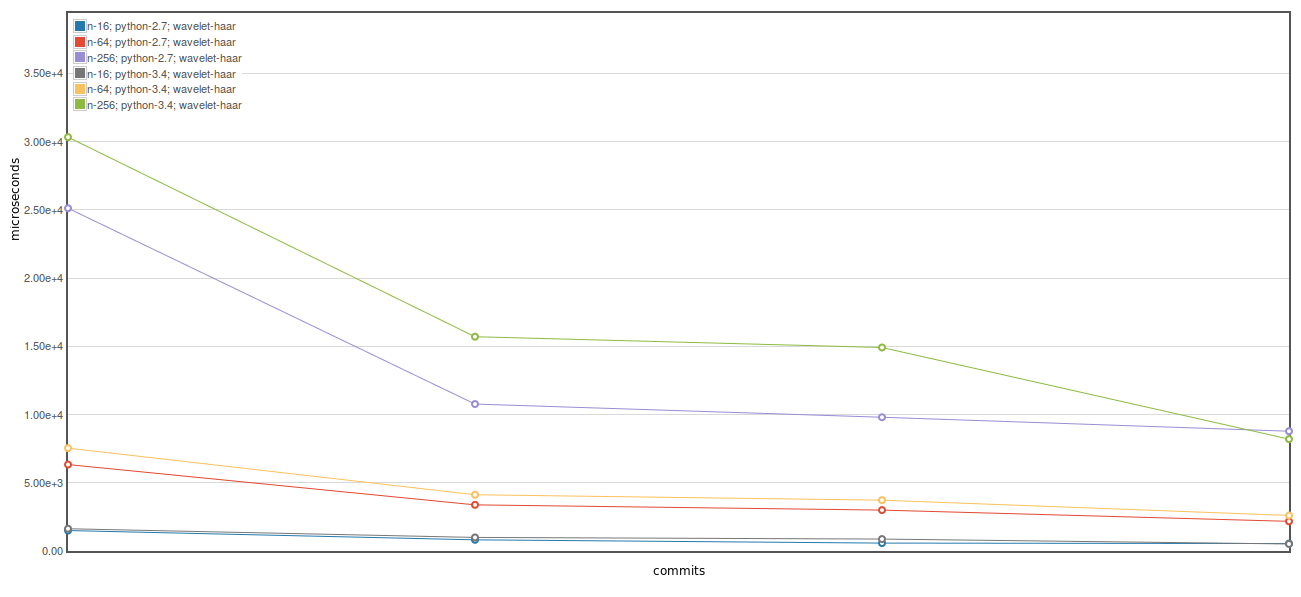
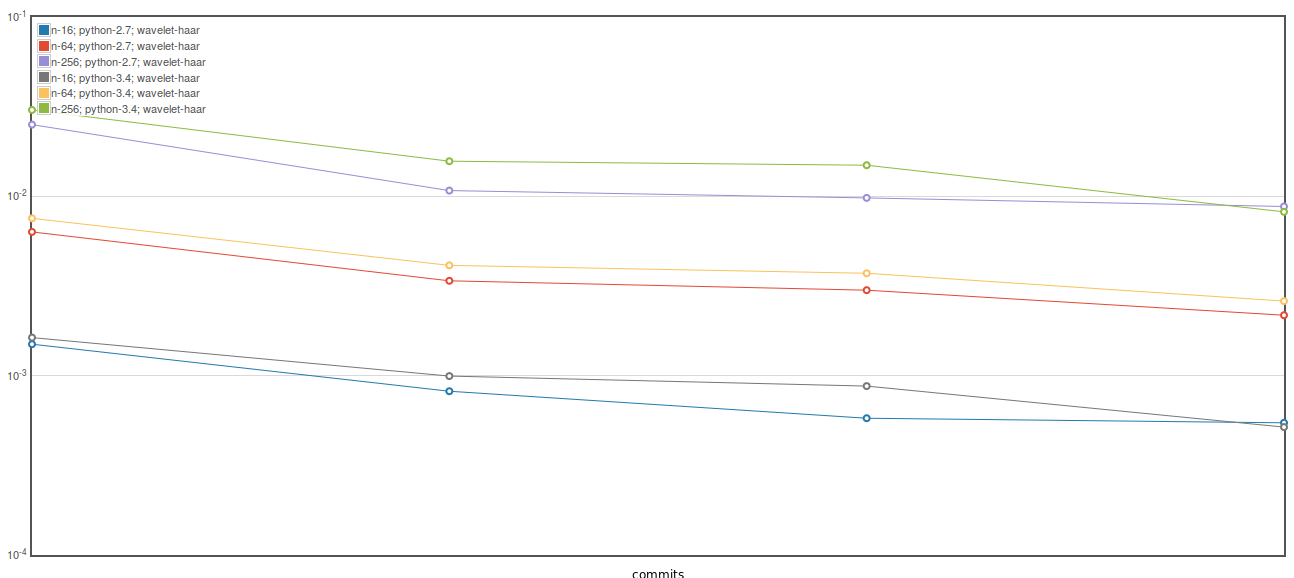
|
I rebased off of #158 to generate the figures above, but haven't pushed the rebased branch here. I can do so if you think it is useful, but it is trivial to do the rebase on your end if you want to test it out since there are no overlapping changes between the branches. |
|
Damn. Oh well, looks like the first commit is too big to ignore. If I find a way to use memoryviews that is equally fast I'll do that, but I don't have time to look into it at the moment. The second one is sensible even if it doesn't give much performance benefit, so I'm happy to merge that too. Still not a fan of the last one, I really don't like making |
|
Okay. I rebased without the 3rd commit |
…of dwt_single or idwt_single
|
|
||
| cpdef idwt_single(data_t[::1] cA, data_t[::1] cD, Wavelet wavelet, MODE mode): | ||
| cdef data_t[::1] rec | ||
| cpdef idwt_single(np.ndarray cA, np.ndarray cD, Wavelet wavelet, MODE mode): |
There was a problem hiding this comment.
Can you double check whether there is any performance impact to using a memoryview for the inputs? The advantage is that Cython will automatically check to make sure the dtypes match.
There was a problem hiding this comment.
Actually, I've just checked this and it looks like idwt_single currently works correctly with different types for the input arrays. Which according to the documentation should not be the case.
Edit: Missed a bit - it says it can choose the biggest corresponding numerical type here. I'm surprised that applies to arrays as well!
There was a problem hiding this comment.
If I recall correctly, it used to be (prior to Cython 0.21 or so) that using fused types created code for all possible combinatorial combinations of the input types, but usually that wasn't desired so it was changed to the present behavior.
There was a problem hiding this comment.
I guess that if the types are already being checked then I can remove the cA.dtype != cD.dtype check I had added.
I will check later this evening or weekend if changing just the inputs back to memory views has any effect.
There was a problem hiding this comment.
I have Cython 0.23 installed, which is why I am confused that the following works:
>>> import pywt, numpy as np
>>> w = pywt.Wavelet('haar')
>>> m = pywt.Modes.zero
>>> a = np.arange(10, dtype='double') ** 2
>>> cA, cD = pywt.dwt(a, w, m)
>>> pywt._extensions._dwt.idwt_single(cA.astype('float'), cD.astype('double'), w, m)
<MemoryView of 'ndarray' at 0x7f92de51c398>
>>> np.asarray(_)
array([ 0., 1., 4., 9., 16., 25., 36., 49., 64., 81.])
>>> a
array([ 0., 1., 4., 9., 16., 25., 36., 49., 64., 81.])
My impression was that it shouldn't, and if something was going wrong (i.e. a buffer of floats interpreted as doubles) the result should be incorrect.
There was a problem hiding this comment.
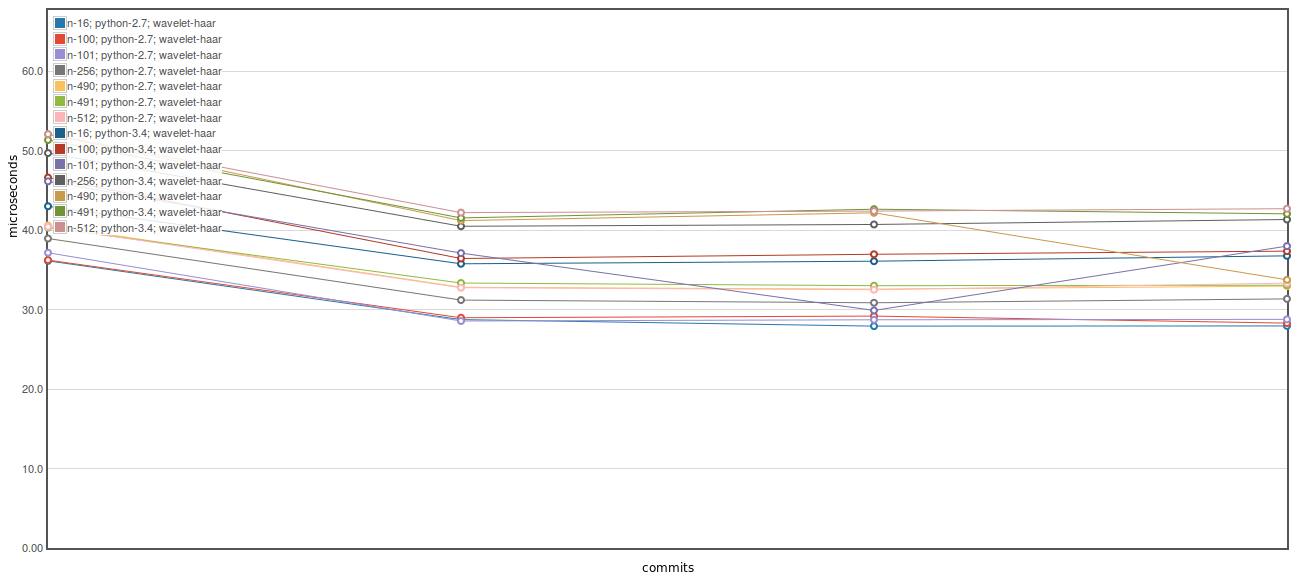
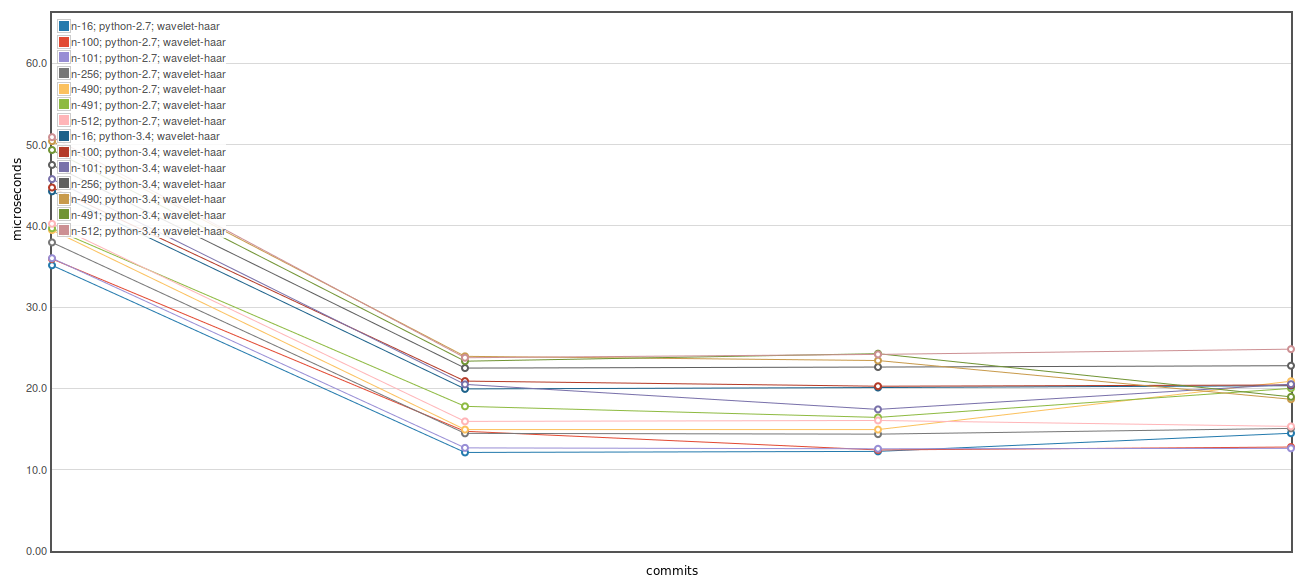
I tried just using a memoryview for the inputs to idwt_single, but leaving the result as np.ndarray, but this did negated a large portion of the speedup (final commit of the plot below):
For time_idwt

There was a problem hiding this comment.
Huh, very odd. Leave it in then, I'll investigate it later. Thanks for checking it out though.
There was a problem hiding this comment.
Also, I figure out why your example above succeeds. .astype('float') and .astype('double') both give arrays with dtype as np.float64 since the default float is 64-bit in python.
If I modified the call as follows we see the expected failure:
pywt._extensions._dwt.idwt_single(cA.astype(np.float32), cD.astype('double'), w, m) File "pywt/_extensions/_dwt.pyx", line 101, in pywt._extensions._dwt.idwt_single (pywt/_extensions/_dwt.c:5454)
File "pywt/_extensions/_dwt.pyx", line 112, in pywt._extensions._dwt.idwt_single (pywt/_extensions/_dwt.c:4961)
ValueError: Coefficients arrays must have the same dtype.
There was a problem hiding this comment.
Ah, I'm an idiot. Mystery solved!
…ient length attributes in C function calls
|
The last commit removes a bit of yellow from the |
|
OK, +1 from me. Making a note to investigate memoryviews & efficiency later (after we've sorted out the benchmarking issue). |
fix: iswt/idwt performance regression
This is an attempt to address the performance regression in #157
Altogether this gives me an approximately 3-fold speedup relative to current master for the test script provided by @zstomp in #157. Roughly half the improvement is from the first commit and most of the rest is from the third.
I am not a big fan of the third commit here, so would appreciate if anyone else has a cleaner solution.
apologies to @kwohlfahrt if you had already started working on this, but perhaps you will have found other areas for improvement that I missed!
probably the most obvious next step to improve perfomance for
iswtwould be moving the loops over to the C/Cython side as was done fordwtnandidwtnin v0.4.0, but I don't currently have time to work on that.