RFC: Lightweight deletes for MergeTree-family tables. #19627
Description
Update (2022-08-01): everything described below is outdated and irrelevant.
Requirements:
- we want to delete data from MergeTree-family tables efficiently.
- The cost of those deletes should be close to the cost of a simple SELECT, which matches the same conditions.
and
SELECT count() WHERE <list of conditions>should also take a similar amount of time.DELETE ... WHERE <same list of conditions> - we can have many
DELETEs (same limitations on the number ofDELETEs as for the number ofINSERTs are ok). DELETEs should be synchronous (on a single node), and eventual (go together with replication queue) in a replicated systemDELETEs should not reprocess significant amounts of data - we don't want to rewrite gigabytes of data to remove a single row.
That means we need to store a mask of deleted rows instead of deleting them immediately. Real data deletion should happen eventually during normal background operations (merges etc.).- Once we calculate the mask of deleted rows (calculation can be expensive), we should use that mask in a very efficient/close to zero cost during further selects.
SELECT count() FROM table; DELETE FROM table WHERE <conditions expensive to calculate>; <-- that may take a lot of time, it's ok SELECT count() FROM table; <-- that should be fast (i.e., we don't want to reapply the same conditions with every select) - data parts should be immutable during
DELETEs - that is 'must-have' for replication. - standard SQL syntax
Concept
Generally, that means that we need
- when
DELETEfired - calculate a mask of deleted rows for every data part (for complicated conditions calculation can be costly) - instead of deleting anything, do an insert in some special place the following information
data_part_name, mask_of_deleted_rows + may be some meta (like max block number) - selects / merges should check that 'special' place when selecting data, applying it as a row mask (applying the mask should be very cheap)
- we need to run some upkeeping procedures that will
- consolidate those masks in the background: if frequent
DELETEs happen, we still want
to keep a minimum number of masks - ideally one per part, and merge several masks into a single mask efficiently - remove the masks for parts that were already merged and deleted - to keep that 'special place' compact.
- consolidate those masks in the background: if frequent

Illustration using existing abstactions
Illustration using existing abstactions
Note: it's just an illustration. Obviously, the feature should be implemented inside MergeTree engine itself, and live together with that as a single logical table, w/o any extra tables.
- we have some
my_tabletable withengine=MergeTreeand we want to run DELETEs there. - We need to be able to calculate the offset of the row (from part beginning).
imagine we have it as a virtual column named_part_offset - we have some special storage to store masks for our
my_table
CRATE TABLE _deleted_rows_mask.my_table (
part_name String,
mask AggregateFunction(groupBitmap, UInt32)
) engine=AggregatingMergeTree ORDER BY part_name;
- deletes work like
INSERT INTO _deleted_rows_mask.my_table SELECT _part, groupBitmapState( _part_offset) FROM my_table WHERE ...
- now MergeTree reader should be able to apply those masks while reading the part
SELECT * FROM my_table
WHERE (_part, _part_offset) NOT IN
(
SELECT part_name, arrayJoin( bitmapToArray( groupBitmapMerge( mask ) ) )
FROM _deleted_rows_mask.my_table
GROUP BY part_name
);
Implementation details (updated)
How mutations work
PARTITION_MINBLOCK_MAXBLOCK_LEVEL + mutation_XXX = PARTITION_MINBLOCK_MAXBLOCK_LEVEL_XXX
for example:
20100101_1_1_0 + mutation_2.txt = 20100101_1_1_0_2
Disadvantages:
Even a single row update require 'touching' all the parts (renaming them)
Creates a lot of inactive parts
Makes backups problematic.
ALTER DELETE is always IO (read/write) and CPU (unpack/pack) heavy
Lightweight delete:
get the number in every partition (Replicated) / for a table (nonReplicated) exactly the same as mutation.
Share numbering with mutations: so after mutation nr. 2, the lightweight mutation will get a number nr. 3.
Works very similar to mutation, and share some invariants, but the result of lightweight mutation is stored 'aside'.
20100101_1_1_0_2 + lightweight_mutation_3.txt = 20100101_1_1_0_2 + deleted_rows_masks_3.bin ( internally it store a mask for part 20100101_1_1_0_2 )
Obviously, masks need to be stored persistently. (fsyncs?)
So we will have one file deleted_rows_masks_3.bin (mutable, appendable) inside the table data folder for every 'lightweight_mutation'.
Lightweight_mutation mask for lightweight_mutations N+1 includes a mask for lightweight_mutations N (and all previous).
This way we single lightweight_mutation will write a single file only, and we can keep the last N files.
The last lightweight_mutation number is always stored in RAM together with other part metainformation.
The last mask may also be stored in RAM to make usage of it efficient (questionable - masks for large old parts can be big, so maybe smth like LRU cache + or some smart memory structures may be needed for that).
We also need a nice way to read deleted_rows_masks_3.bin for a particular part, so we may also need smth like deleted_rows_masks_3.idx
So the how that 'lightweight_mutation' work
DELETE FROM TABLE ...fired- we get the block number(s) for delete (just like with ALTER DELETE), let's say 100
- work very similar to mutation (part by part), but instead of writing new parts - it
producesdeleted_rows_masks_100.bin- to achieve speed similar to SELECT - it may be needed to use
max_threadshere.
- to achieve speed similar to SELECT - it may be needed to use
- if we get part 'younger' than 100 (for example from another replica, from a merge scheduled before DELETE) we should
calculate mask for it when the part is added to a working set. - merge on 2 parts ( 20100101_1_1_0 + 20100101_2_2_0 ) which have mutation id 3 and masks in
deleted_rows_masks_3.bin will produce a part with masks applied, and number in the part name, i.e.
20100101_1_1_0 + 20100101_2_2_0 + deleted_rows_masks_3.bin = 20100101_1_2_1_3 (and no mask).
Existing invariant for mutations:
'every part which has block numbers and mutation_nr younger than last mutation id considered unmutated' get changed to
'every part which has block numbers and max( mutation_nr || deleted_rows_masks_last_mutation ) younger than last mutation id considered unmutated'
In replicated:
-
every replica pays the same price for lightweight_mutation and applies it on its own set of parts.
state ofdeleted_rows_masks_X.bincan differ on different replicas (and will differ, because set of parts on every replica can differ), but eventually, they will get in sync. (after all known parts with block numbers younger than mutation will be processed). -
extend FETCH part to send also latest mask together with part. ( Alternatively: introduce deleted_rows_masks exchange, so if some replica has missing masks for some reason it can request from other replica masks for any of parts existing on that replica.)
Steps
A. Plain MergeTree implementation
- Prepare simple in-memory storage for masks + API around (mask getter per part, mask setter per mutation_id)
- parser for SQL deletes, write lightweight mutation to files (similar to mutationXXX.sql)
- Create a mutation mode that uses lightweight_mutationXXX.sql and creates masks
- Make MergeTreeReader aware of deleted rows bitmask on SELECT.
<-- MVP (deletes w/o persistancy) - Add serialization for masks to file, pick the best format supporting appending, checksum validation, and indexing for a mask. (reuse the writers from Log family?), support fsync.
- Cleanup of obsolete mask files
<-- + persistancy - Review / adjust various places where part checks/manipulation happen (server start, merges, normal mutations, alters, etc).
<-- cover complex scenarios - Consider in-memory optimization for mask storage (LRU cache with fixed size?)
- Consider multithreaded execution of lightweight mutations
<-- performance optimizations
B. ReplicatedMergeTree implementation
- Extend replication queue with a new type of task.
- Extend part sending to send also mask (preserve backward compatibility for older ClickHouse)
- Review / adjust various places where part checks/manipulation happen (server start, merges, normal mutations, alters etc).
- Extend part-exchange to be able to recover masks from other replicas.
Implementation details (older, rejected version)
Implementation details (older, rejected version)
Declaimer: it's just a concept. Details should be rechecked/reviewed.
Every MergeTree table currently has a set of data parts inside (it as a structure defined by a user, and can carry a big amount of data), we want to introduce a new set of deleted_rows_masks parts with a fixed and predefined structure and normally it will be tiny. It can be one more 'MergeTreeData' object attached to Storage, or just a special 'service' partition with another structure. The deletes will be transformed into inserts to deleted_rows_masks parts (see below).
We will need to add to MergeTreeReader option to apply that mask automatically (so both selects and merges will work).
In the future, we can also consider adding some optimizations to skip whole ranges during PK analysis.
deleted_rows_mask parts
Those deleted_rows_mask parts can live in a subfolder deleted_rows_masks, inside table data directory. Or live together with other parts (but with some other partition name).
Internally it can have a logical structure similar to:
(
part_name String,
part_state Enum8('active' = 0, 'eol' = 1), /* once there is scheduled merge for a part we need to store it's state separately */
delete_ids AggregateFunction(groupArray, UInt32) /* ids of all deletes / may be just max will be enough */
mask AggregateFunction(groupBitmap, UInt32),
deleted_timestamp SimpleAggregateFunction(max, DateTime),
) engine=AggregatingMergeTree
ORDER BY (part_name, part_state)
TTL deleted_timestamp + 1 HOUR
For storing masks of deleted rows per part roaring bitmaps sounds like a good choice:
- they are compact if not too many rows were deleted
- will be able to store up to
MAX_UINT32offsets for every part (~4 bln, I guess should be enough). - do 'bitwise or' automatically (needed to merge multiple deletes into a single row per part)
- can be slower/bigger when a lot of random rows were deleted, but that sounds acceptable.
Alternatively, simple arrays can be used.
deleted_rows_masks parts should be registered in zookeeper the usual way (just like one more 'service' partition), and share the same/single replication queue (this way, we can preserve the proper sequence of INSERTs / DELETEs / merges).
The last state of deleted_rows_masks may also live in RAM to avoid reading those parts with every select, so when you add a new part into deleted_rows_mask we update that state in RAM.
DELETE process for ReplicatedMergeTree
-
add DELETE to the replication queue. It stored block_number from every partition (just like mutations)
-
each replica having received a DELETE from the replication queue must apply it to its active set of data parts.
-
Each part "younger" (by its block number) than DELETE must have a mask for this part next to the data part in the version corresponding to the DELETE that occurred. To build that:
-
iterate data parts sequentially
-
for every part with max_block_number lower than DELETE block number we:
- first check for non-fetched yet parts deleted_rows_mask partition and fetch them.
- if we don't have a delete mask for pair of <part_name, DELETE with number X> in a special place (deleted_rows_mask partition) then execute the DELETE to calculate the mask.
- if there is a merge for that part in the queue we insert it as 'eol' (merges can use only part_state=active).
-
skip parts with min_block_number greater than DELETE block number
-
if we have a situation: min_block_number < delete block number < max_block_number, and no mask in deleted_rows_mask partition - I guess it should be a logical error / should be just forbidden (by preventing the execution of the merges from the queue out of order with deletes, and by extra logic in merge), see also "merges execution" below.
-
after iterating all the parts form an insert into deleted_rows_mask partition. If other replicas already did that - it's ok, deletes are idempotent.
After the DELETE record has been successfully processed by all replicas (and the corresponding masks have been created),
and all merges which were scheduled before DELETE were finished, then the DELETE record is no longer needed anymore in the replication queue. Now we store the history of deleted rows only as a mask. -
execution of merges
-
Merge could have been assigned before DELETE or after.
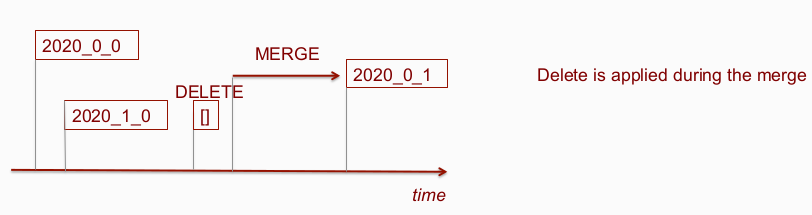

-
Merges start depending not only on the source data parts but also on deletes that were executed BEFORE the merge. So we can not start the merge if one of the source parts is not yet ready, or if some DELETE assigned before the merge is not finished.
-
Any merge should read data by applying "on the fly" masks of all DELETEs assigned earlier (i.e. with part_state='active') physically deleting and ignore the masks of those DELETEs that were assigned later than the merge started. Thus, even the lagging merges will produce parts with the same checksums.
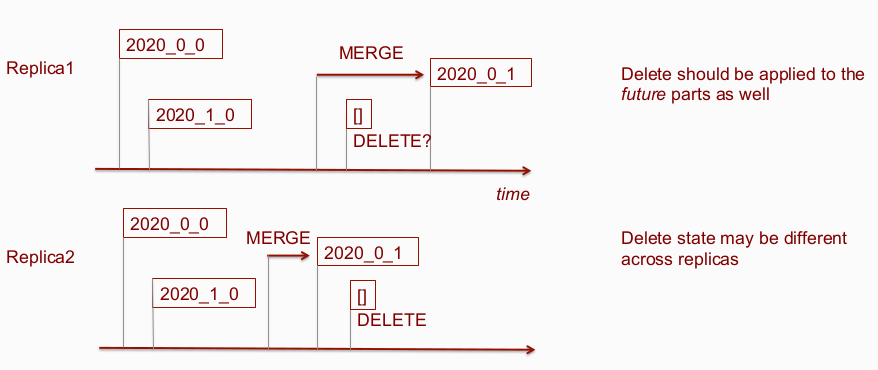
-
After the end of the merge, before adding a part to the active set, we should make sure that for the new (merged)
part there are masks for all DELETE operation launched AFTER the merge assignment. If some of them are missing - they need to be downloaded or calculated.

background operations on deleted_rows_mask partition
We want masks to be compact and cheap to use.
-
multiple replicas can add the same row to the partition with masks at the same time (no big deal, deletes are idempotent)
-
masks for the same part are divided into two groups
- related to DELETE operations fired BEFORE the merge, which should end the lifetime of that part (they will be applied during the merge)
- and related to DELETE operations fired after the merge is assigned (they will not be applied during the merge but will be applied during the selections).
-
several lines containing masks for the same part can be combined into one line (bitwise OR on masks) within these two groups.
Example. If 100 deletes happened before the merge was assigned and 25 more after it was assigned. Then you can combine
all 100 in one general mask, and 25 in a separate mask.
- after the part has been removed (as a result of a merge or similar operation), we can safely remove it and related masks
- replica can safely exchange parts with masks just like regular parts.
whatever
UPDATEs?
Executing a 'proper' update requires access to the previous state of the row, which may be not available (or can be outdated) due to eventual consistency on any concrete replica.
The quite easy thing is a special kind of UPDATE similar to UPSERT (internally DELETE as above + INSERT, w/o accessing the previous state of the row).
Alternatives:
- wait for
n-1replication state (finishing all merges/fetches etc assigned before the update) - it can be very long delays. - apply on the fly till
n-1replication state will be reached. That may end up with quite strange behavior, when different rows are affected by same update depending on replication state. Questionable: i guess users expect smth similar to ACID rdbms