Array4: __cuda_array_interface__ v3#30
Merged
ax3l merged 9 commits intoAMReX-Codes:developmentfrom Oct 17, 2022
Merged
Conversation
0e72782 to
44eb90c
Compare
44eb90c to
d2937d0
Compare
7c0289a to
f3ff788
Compare
Member
Author
|
Update: patch that unlocks that broken compiler range in pybind/pybind11#4220 cmake -S . -B build -DAMREX_GPU_BACKEND=CUDA -DpyAMReX_pybind11_repo=https://github.com/ax3l/pybind11.git -DpyAMReX_pybind11_branch=fix-nvcc-11.4-11.8 |
Member
Author
|
@RemiLehe build logic from README.md is this:
So concretely: # Python packages if not already installed as described
python3 -m pip install -U pip setuptools wheel
python3 -m pip install -U cmake pytest
python3 -m pip install -U -r requirements.txt
# depending on what you try
python3 -m pip install cupy-cuda11x
python3 -m pip install numba
python3 -m pip install torch
# configure once (unless changing backend or versions heavily)
cmake -S . -B build -DAMReX_GPU_BACKEND=CUDA \
-DpyAMReX_pybind11_repo=https://github.com/ax3l/pybind11.git \
-DpyAMReX_pybind11_branch=fix-nvcc-11.4-11.8
# rinse & repeat: builds, packages & runs pip install
cmake --build build --target pip_install -j 8and tests: # Run all tests
python3 -m pytest tests/
# Run tests from a single file
python3 -m pytest tests/test_array4.py
# Run a single test (useful during debugging)
python3 -m pytest tests/test_array4.py::test_array4_cupy
python3 -m pytest tests/test_multifab.py::test_mfab_ops_cuda_cupy
# Run all tests, do not capture "print" output and be verbose
python3 -m pytest -s -vvvv tests/test_array4.pyand with nsight: GUI: |
Merged
Member
Author
f3ff788 to
7fe40bd
Compare
d0f2dec to
5395043
Compare
Member
Author
|
|

ax3l
commented
Oct 7, 2022
5395043 to
df349c5
Compare
ax3l
commented
Oct 7, 2022
5 tasks
Member
Author
|
With the new |
f5138a9 to
a7fc736
Compare
ax3l
commented
Oct 14, 2022
Merged
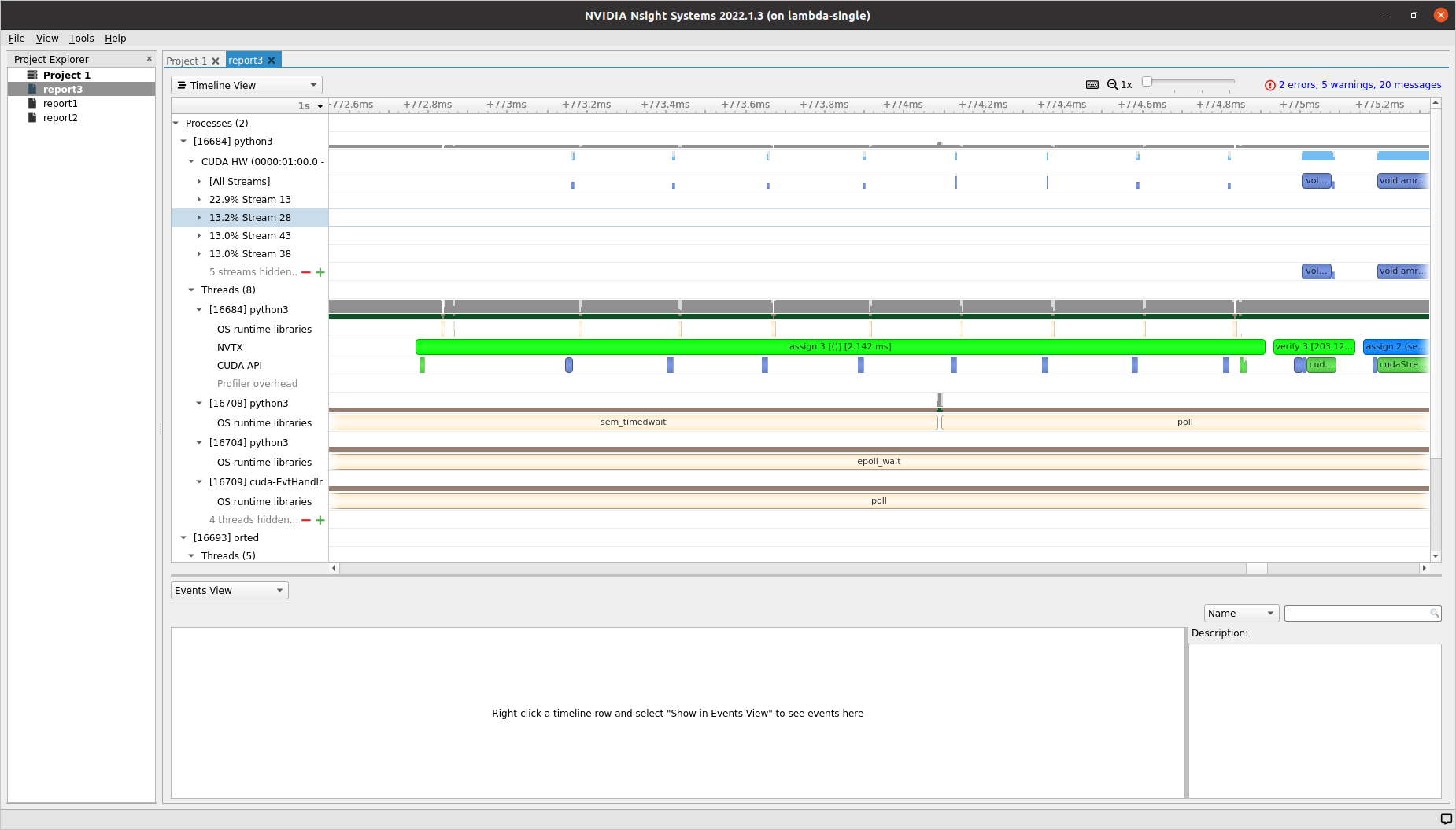
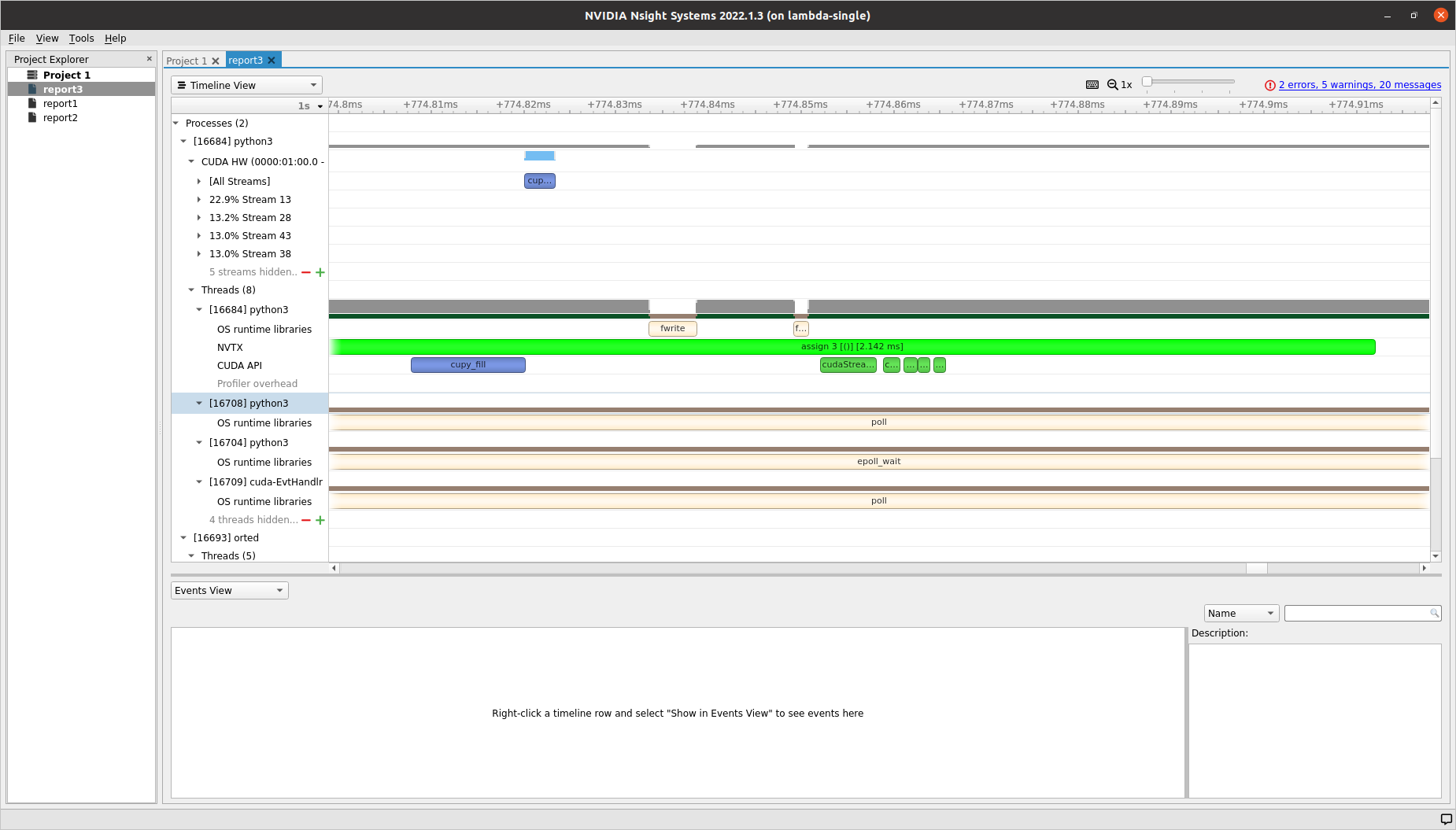
Start implementing the `__cuda_array_interface__` for zero-copy data exchange on Nvidia CUDA GPUs.
Since `for` loops create no scope in Python, we need to trigger finalize logic, including stream syncs, before the destructor of `MultiFab` iterators are called.
incl. 3D kernel launch
f204a6d to
4175194
Compare
ax3l
commented
Oct 17, 2022
a6a1199 to
6eb2da4
Compare
A bit tricky to implement this caster as new constructor. Not currently needed, but adds comments where to do this.
Member
Author
|
Wuup, wuup. First part done. |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Start implementing the
__cuda_array_interface__for zero-copy data exchange on Nvidia CUDA GPUs.Optional: accessing an external
__cuda_array_interface__object in non-owning manner as AMReX Array4:https://github.com/cupy/cupy/blob/a5b24f91d4d77fa03e6a4dd2ac954ff9a04e21f4/cupy/core/core.pyx#L2478-L2514
mfabandmfab_deviceneed to become functions, not fixtures. Otherwise they will be cached and outliveamrex.finalize(): AMReX Initialize/Finalize as Context Manager #81 MultiFab: Fix Fixture Lifetime #84pyamrex/src/Base/MultiFab.cpp
Lines 72 to 75 in 78bbbc7
depends on MFIter::Finalize amrex#2983 and MFIter: Make Finalize Public amrex#2985
ifandfordo not create a scope in Python (they do in C++):