
🤗 reasonrank-7B | 🤗 reasonrank-32B
🤗 reasonrank_data_13k | 🤗 reasonrank_data_sft | 🤗 reasonrank_data_rl
- [Feb 24, 2026]: 🔥 We released our reasoning-intensive reranker reasonrank-8B which is trained using backbone LRM Qwen3-8B.
- [Sep 22, 2025]:🔔 The brief introduction of our ReasonRank can be found on platforms like X and WeChat.
- [Sep 5, 2025]: 🔔 Our ReasonRank has been integrated into the RankLLM framework. You can use the codes of RankLLM to run our ReasonRank.
- [Sep 4, 2025]: 🔔🔔🔔 For more convenient reproduction of our ReasonRank (32B) in your own codes, we have merged the LoRA parameters of ReasonRank (32B) into corresponding checkpoint shards, so now everyone only needs to load the checkpoint shards of 🤗reasonrank-32B without the LoRA adapter anymore. The LoRA adapter directory has been removed from the model directory.
- [Aug 16, 2025]:🏆 Our ReasonRank (32B) has achieved SOTA performance 42.85 on R2MED leaderboard!
- [Aug 15, 2025]:🔥 We released our datasets and models on ModelScope!
- [Aug 9, 2025]: 🏆 Our ReasonRank (32B) has achieved SOTA performance 40.8 on BRIGHT leaderboard!
- [Aug 9, 2025]: 📄 We uploaded our paper to the arXiv and Hugging Face.
- [Aug 9, 2025]: 🔥 We released our 🤗full reasonrank training data (13k), 🤗cold-start SFT data and 🤗RL data.
- [Aug 9, 2025]: 🔥 We released our reasoning-intensive reranker 🤗reasonrank-7B and 🤗reasonrank-32B.
- [Aug 9, 2025]: 🚀 We released our full codebase, including inference, SFT training, and RL training.
- 1. ReasonRank
- 2. The Introduction of ReasonRank Training Data
- 3. Quick Start
- Citation
ReasonRank is a reasoning-intensive passage reranker tailored for reasoning-intensive ranking tasks. To train it, we first design an automated reasoning-intensive training data synthesis framework and synthesize 1.3k high-quality training data.
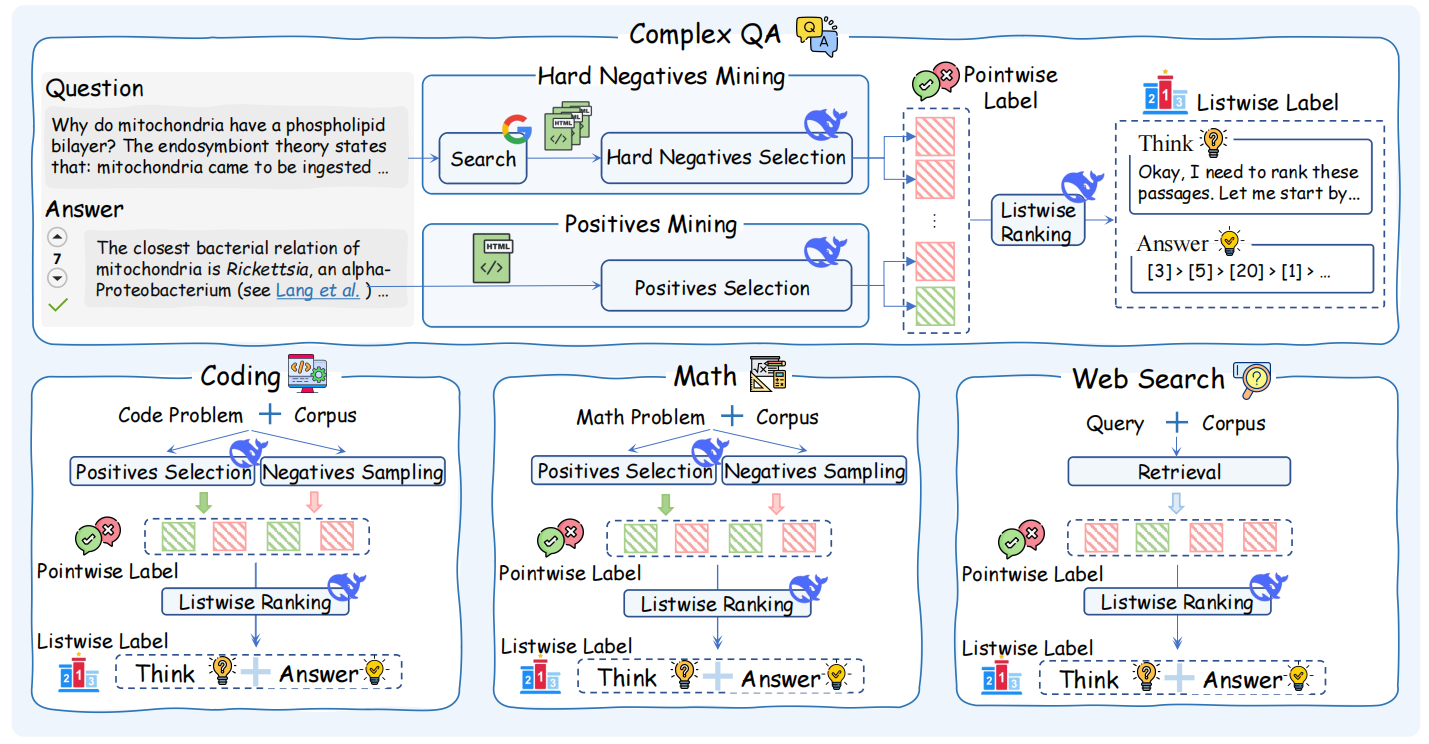
Based on the training data, we design a two-stage training approach including cold-start SFT and multi-view ranking reward RL to inject listwise ranking ability to our ReasonRank.

When using ReasonIR as initial passage retriever, our ReasonRank demonstrates strong overall ranking performance on BRIGHT benchmark, while showing superior efficiency compared with pointwise reasoning-intensive reranker Rank1.
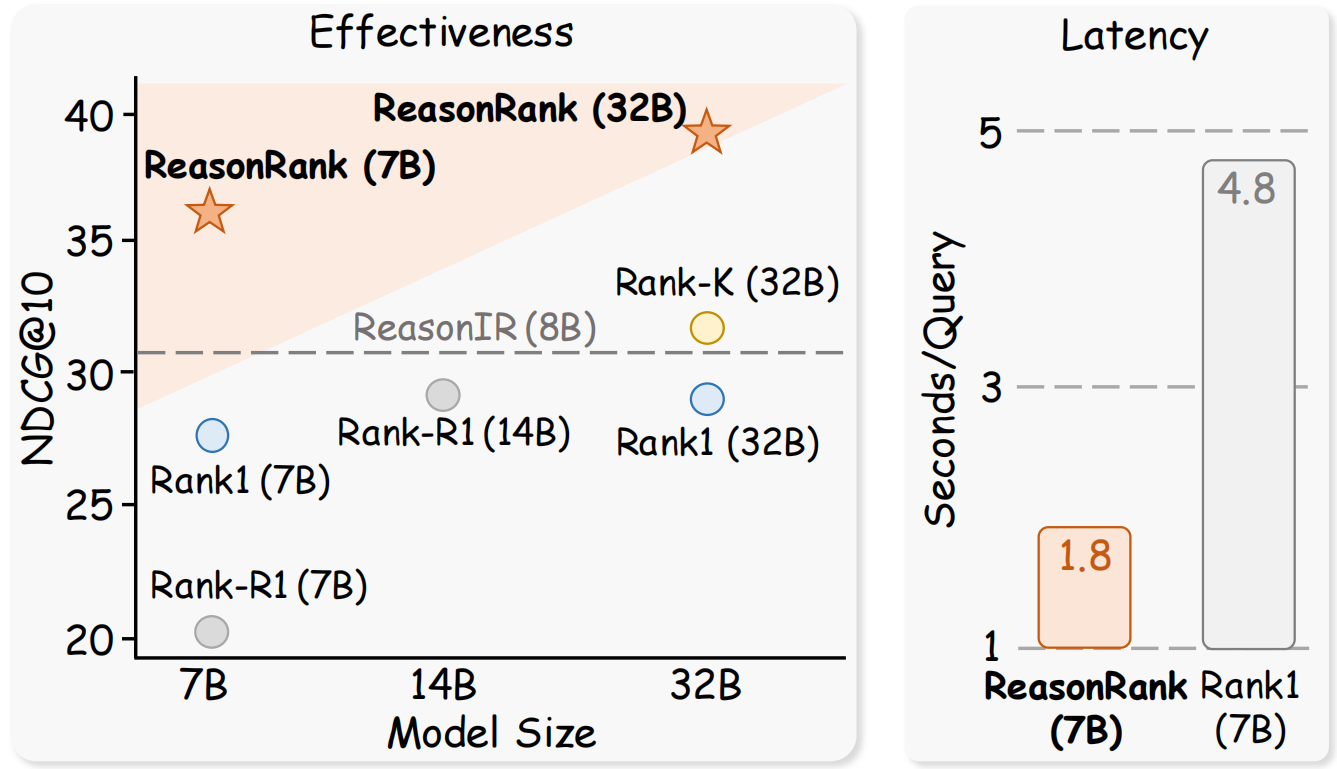
Besides, when using a higher-quality retrieval results (RaDeR + BM25 hybrid, provided by RaDeR), our ReasonRank (32B) achieves SOTA performance 40.8 on BRIGHT leaderboard.
An important contribution of our work is our reasoning-intensive training data (reasonrank_data_13k). The dataset fields of training_data_all.jsonl are as follows:
dataset(str)- The dataset name of each piece of data (e.g.,
"math-qa").
- The dataset name of each piece of data (e.g.,
qid(str)- The query ID. The content is provided in
id_query/directory.
- The query ID. The content is provided in
initial_list(List[str])- The initial list of passage IDs before DeepSeek-R1 reranking. The content of each passage ID is provided in
id_doc/directory.
- The initial list of passage IDs before DeepSeek-R1 reranking. The content of each passage ID is provided in
final_list(List[str])- The re-ranked list of passage IDs after listwisely reranking with DeepSeek-R1.
- Reflects the improved ranking based on reasoning-enhanced relevance scoring.
reasoning(str)- A step-by-step reasoning chain outputted by DeepSeek-R1 while performing the listwise reranking.
relevant_docids(List[str])- The ids of relevant passages in
initial_listmined by DeepSeek-R1. The remaining passage ids ininitial_listare irrelevant ones. - Note that
relevant_docidsare not necessarily ranked at the top offinal_listby the DeepSeek-R1, which may stem from inconsistencies in DeepSeek-R1’s judgments. To address this, you can apply the self-consistency data filtering technique proposed in our paper to further select higher-quality data (i.e., evaluating the NDCG@10 of final_list using relevant_docids and only keep the ones with NDCG@10 higher than a threshold. Note that the threshold is set as 0.4 in our paper, you could try to increase it for constructing higher-quality data if you want.).
- The ids of relevant passages in
The statistics of dataset is shown in the figure below:

{
"dataset": "math-qa",
"qid": "math_1001",
"initial_list": ["math_test_intermediate_algebra_808", "math_train_intermediate_algebra_1471", ...],
"final_list": ["math_test_intermediate_algebra_808", "math_test_intermediate_algebra_1678", ...],
"reasoning": "Okay, I need to rank the 20 passages based on their relevance...",
"relevant_docids": ["math_test_intermediate_algebra_808", "math_train_intermediate_algebra_1471", "math_train_intermediate_algebra_993"]
}- Training passage reranker: Given the reranked passage list, one can use our data to train a listwise reranker
- Training passage retriever: Using the
relevant_docidsand the remaining irrelevant ids, one can train a passage retriever.
In this step, we will describe the required packages for inferencing with ReasonRank. Please install the following packages.
# recommend:
# Python: Version >= 3.10
# CUDA: Version >= 12.0
pip install vllm==0.8.5.post1+cu121
pip install ftfy
pip install pyserini==0.20.0
pip install dacite
pip install pytrec-eval
pip install packaging
pip install rbo
pip install openai
pip install tenacity
pip install datasets
pip install faiss_gpu==1.7.3
pip install qwen_omni_utils
pip install blobfilea. After installing the necessary packages, remember to update the WORKSPACE_DIR and PROJECT_DIR (both should be absolute paths) in config.py. These two parameters will be used both in our inference codes and training codes. Here is a recommended directory structure:
{WORKSPACE_DIR}
├── trained_models
│ ├── reasonrank-7B
│ └── reasonrank-32B
├── data
│ ├── bright
└── {PROJECT_DIR} (i.e., {WORKSPACE_DIR}/reasonrank)
├── run_rank_llm.sh
└── run_rank_llm.py
└── LLaMA-Factory
└── ...b. Download the bright and r2med which contain the corpus of BRIGHT and R2MED datasets, unzip these two directory and put them under {WORKSPACE_DIR}/data directory respectively. (Modelscope download links are also available: bright and r2med)
c. Install jdk (we use jdk-11.0.8 in our work, other versions will also be okey)
For running reasonrank-7B, reasonrank-32B and reasonrank-8B, please run the following command under {PROJECT_DIR}.
Note that for reasonrank-8B which is trained based on Qwen3-8B, the parameter prompt_mode is set as rank_GPT_qwen3.
bash run_rank_llm.shThe script run_rank_llm.sh includes the running command for both models. Note that the results of reproducing ReasonRank may vary slightly due to the randomness of sampling strategy and different versions of vllm.
To inference with custom retrieval results, you need to put the TREC-format retrieval result files under directory runs/{dataset}/{file_name}. The file_name of each dataset must be the same, such as custom.txt. Then specify the parameter retrieval_results_name as {file_name}. The whole script is shown in run_rank_llm.sh file.
The core codes for constructing our ReasonRank prompt is shown in create_prompt function in rerank/rank_listwise_os_llm.py file. If you reproduce ReasonRank in your own project, please strictly use the same method for constructing the prompt to ensure ReasonRank's performance.. Note that the parameter prompt_mode used for our ReasonRank is PromptMode.RANK_GPT_reasoning.
def create_prompt(self, result: Result, rank_start: int, rank_end: int) -> Tuple[str, int]:
query = result.query.text
qid = result.query.qid
query = self._replace_number(query).strip()
num = len(result.candidates[rank_start:rank_end])
max_length = self.max_passage_length
#################### core codes for constructing the input ####################
messages = []
if self.args.prompt_mode == str(PromptMode.RANK_GPT_reasoning): # for our ReasonRank model as well as some non-reasoning models such as qwen2.5-instruct
messages.append({"role": "system", "content": self.prompt_info['system_prompt_reasoning']})
elif self.args.prompt_mode in [str(PromptMode.RANK_GPT), str(PromptMode.RANK_GPT_qwen3)]:
messages.append({"role": "system", "content": self.prompt_info['system_prompt']})
prefix = add_prefix_prompt(promptmode=self.prompt_mode, query=query, num=num)
rank = 0
input_context = f"{prefix}\n"
for cand in result.candidates[rank_start:rank_end]:
rank += 1
content = convert_doc_to_prompt_content(self._tokenizer, cand.doc, max_length, truncate_by_word=False)
input_context += f"[{rank}] {content}\n"
input_context += add_post_prompt(promptmode=self.prompt_mode, query=query, num=num)
messages.append({"role": "user", "content": input_context})
prompt = self._tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
prompt = fix_text(prompt)
#################### core codes for constructing the input ####################
num_tokens = self.get_num_tokens(prompt)
return prompt, num_tokensIn this step, we will describe how to perform a cold start SFT using the Llama Factory repository. Please first set up the environment for Llama Factory.
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation- Download our SFT dataset from 🤗reasonrank_data_sft and place it in
LLaMA-Factory/data/reasonrank_sft-data.json. We have pre-define the dataset indataset_info.json. - For full training (i.e., reasonrank-7B), complete the path information in
LLaMA-Factory/examples/train_full/qwen_full_sft.yaml. The file content should be as follows:
### model
model_name_or_path: {YOUR_BACKBONE_MODEL_PATH}/Qwen2.5-7B-Instruct
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: full
deepspeed: examples/deepspeed/ds_z3_config.json # choices: [ds_z0_config.json, ds_z2_config.json, ds_z3_config.json]
### dataset
dataset: reasonrank_sft-data
template: qwen
cutoff_len: 23552
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: {YOUR_MODEL_SAVE_PATH}
logging_steps: 10
# save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: true
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 5e-6
num_train_epochs: 5.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
save_strategy: epoch After completing the information, you can fine-tune the model using the following command:
cd LLaMA-Factory
bash run_train.sh- For lora training (i.e., reasonrank-32B), complete the path information in
LLaMA-Factory/examples/train_lora/qwen_lora_sft.yaml. The file content should be as follows:
### model
model_name_or_path: {YOUR_BACKBONE_MODEL_PATH}/Qwen2.5-32B-Instruct
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 32
lora_alpha: 32
lora_target: all
deepspeed: examples/deepspeed/ds_z3_config.json
### dataset
dataset: reasonrank_sft-data
template: qwen
cutoff_len: 23552
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: {YOUR_MODEL_SAVE_PATH}
logging_steps: 10
# save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: true
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 7.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
save_strategy: epoch After completing the information, you can fine-tune the model using the following command:
cd LLaMA-Factory
bash run_train_lora.shIn this step, we will load the cold-start model for GRPO training. We use VERL frameworks for RL training.
you can install our additional environment as follow:
cd verl # we use verl==0.4.0
bash scripts/install_vllm_sglang_mcore.sh
USE_MEGATRON=0 bash scripts/install_vllm_sglang_mcore.sh
pip install --no-deps -e .Our multi-view ranking reward is implemented in the
verl/verl/utils/reward_score/ranking.py.
a. Remember to update the pattern file path in verl/verl/utils/reward_score/ranking.py with the absolute path of our project reasonrank.
pattern = toml.load('{YOUR_PROJECT_DIR}/listwise_prompt_r1.toml')['pattern']b. Update the YOUR_PROJECT_DIR in verl/scripts/merge.sh with the absolute path of our project reasonrank.
c. Download our RL dataset from 🤗reasonrank_data_rl and place the training set file and validation file in verl/data/.
d. Run the following command to train ReasonRank (7B):
bash train_grpo.shRemember to change the actor_rollout_ref.model.path to the path of your SFT model and trainer.default_local_dir to the model saving path.
e. Run the following command to train ReasonRank (32B) with lora:
bash train_grpo_lora.shRemember to change the actor_rollout_ref.model.path to the path of your SFT model and trainer.default_local_dir to the model saving path.

If you find this work helpful, please cite our papers:
@article{liu2025reasonrank,
title={ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability},
author={Liu, Wenhan and Ma, Xinyu and Sun, Weiwei and Zhu, Yutao and Li, Yuchen and Yin, Dawei and Dou, Zhicheng},
journal={arXiv preprint arXiv:2508.07050},
year={2025}
}}The inference codes and training implementation build upon RankLLM, Llama Factory and verl. Our work is based on the Qwen2.5 model series, and we sincerely thank the Qwen team for their outstanding contributions to the open-source community.
This project is released under the MIT License.
For any questions or feedback, please reach out to us at [email protected].