又一个兔子洞(笑)。
ReplayGain和响度
故事开始前,大概得先讲讲到底什么是ReplayGain,以及为什么我们需要它。
响度规格化
一言以蔽之,ReplayGain是用来规格化(Normalize)音乐,或者说数字音频文件,的响度(Loudness)的。但是这里要非常小心术语,因为规格化这个词有很多不同的应用。控制动态范围——即“最响”和“最安静”之间的差别,这个有时候也叫作“规格化”(例如在PotPlayer中),但是在音频世界里,更常用的说法叫“压缩”(Compress)。可以看到,一个音频在单纯经过“压缩”之后,其平均响度可能并不会变,但动态范围会变小。这可以解决诸如“电影声效太大,人声小到听不见”之类的问题(但是注意:这并不是一个“正确”的解决方案。至少对我个人来讲,多数动态压缩滤镜听感极差),不过在混音界 Compressor 更常用的用法是指控制输出的范围,便于后期处理。可以看到,一个音频如果经过压缩,其声音特征就改变了。比如艺术家的本意就是这里是悄悄话,那里是爆炸声,结果压缩之后两者的差距就缩小了。因此,在播放音乐时,一般是不应该引入压缩的。
响度规格化,包括ReplayGain,则不同,它要解决的是这么一个问题:不同音轨之间的平均 响度差别很大,用户播放时需要不停地调整音量来获得一个相对舒适的响度。在经过响度规格化之后,一个音轨本身的动态范围理想情况下应该不变,但是会整体地提升或者降低,从而达到音轨于音轨之间相对一致的响度。
既然知道了目标,那实现原理其实就不难理解:只要找到一种测量平均响度的方法,然后分别测量每个音轨的响度,然后再设定一个标准(Reference),比较两者不同,补上差值就行了。
不过这里有俩问题:一个是如何测量响度,一个拿什么当标准。ReplayGain作为音量规格化的一种实现,其实就是解决了这两个问题。
响度的测量
我之前一直以为,ReplayGain的响度测量其实就是单纯测量了一下音频信号的平均强度。
这里稍微赘述一下,(解码后的)音频信号其实表示起来非常简单,就俩量:一个是采样率(每秒多少个点,一般音频是44100 Hz),一个就是按照该采样间隔一字排开的一组时序的数据,每个代表当时的信号强度(当然,存储的时候这系列数据是逐个量化成一定位长的二进制)。至于强度的的范围,有多种表示方式,不过最常用的是是[-1, 1]。绝对值越大,理论上声音也就越响。其中最大的绝对值,一般叫做“Full Scale”,缩写FS。一个点的值既可以写成单纯的一个数字,也可以用dB来表示,例如如果是0.5,就可以写成-6.0206 dB relative to full scale,一般简称dBFS。这里有个计算器 可以用(注意这里针对场量和功率量中dB的算法不同,这里应该用和电压、电流一样的场量的算法)。
说回“平均强度”。学过信号与处理的应该都知道(虽然我并没学过w),在这里是测量信号的方均根(Root mean square ,RMS),而不是平均值或者绝对值平均。RMS这个度量,可以更好地反映比较不同音轨之间的“能量”差别。例如,一个幅值为1的正弦波的RMS就是 0.7071,这个值也可以写成dbFS的形式,这里就是-3.0103 dBFS(这个值很重要,我们后面还会遇到)。它的能量,就应该和峰值为0.7071的方波一致。同理,音乐文件多是多个波形(多为正弦波)的叠加,最简单的方法度量其“能量”的方法就是对所有的点求RMS。
公平地讲,用音频文件的RMS(物理特性)来表示响度,不算是个太坏的方式。响度和能量,两者本身就是非常相关的。不过由于人的听觉感应曲线并不是直线一根,对于不同频率的声音,敏感程度不同,还是应该有更先进的模型。“Loudness”这个词本身的含义其实就包含了人的主观感应在里面的,如果单纯讲物理特性一般会有其他的术语,这个一会再说。
ReplayGain的实现
关于ReplayGain的具体实现方式,其实在当年(2001年?)的Proposal 里面讲得很清楚(这是另外一个版本 ,排版稍微好一点)。总体而言,分为三步:
先利用等响度曲线,通过滤镜对不同的频率部分的进行修正,给与不同的权重;
再讲音频分为每个50ms的段落,测量每段的的RMS;
将所有段落的RMS进行排序,然后选取位于95%处的RMS,作为整个音频的“代表RMS”。在这步作者的理论是,人类的感知响度其实和其中比较响的部分有关,而不是整个音轨的RMS。例如对于对话类型的音频,其中大部分时间都是空白因此总体RMS会很低,但是人只对有声音的地方敏感,所以并不会这么觉得。
最后,只要把这个代表RMS的dBFS值和标准进行比较,然后增加/减少其中的差值就行了。可以看到,整个过程很好理解,而且其本质上还是基于RMS。另外从算法中显然可见,如果放大整个音轨几个dB,其“代表RMS”也会提升对应的dB,所以要调整某个音频的响度,也非常地简单。
能量、声压、响度、RMS的关系
这里再废言几句。我们前面已经说了RMS是对音轨“平均”能量的一种度量,于是这里顺便讲讲感知响度/声压/能量的关系。说到声音大小,最常听说的说法就是“分贝”。其实准确而言,这里的分贝是dB SPL,即声压级(Sound pressure level )。我们知道dB是一个比较量,这里就是指相对于一个标准化了的基准声压,20 μPa(有时称为听阈 )的dB值。声压级是个场量,所以20 dB = 10倍。而声音的能量,一般可以用声音能量密度(Sound intensity)或声功率(Sound power)(这两者之间就差了一个面积)来表示。这是另外一个不错的度量声音强度的方法。其和声压的对应关系是:声音能量密度扩大100倍,声压扩大10倍。不过由于声音能量密度和声功率都是功率量,所以如果也表示成级(Level)的话,是每扩大10倍=10 dB,或者20 dB等于变大100倍。因此,假设一个基准声音为1 [单位]的声压和1 [单位]的声音能量密度,那么一个有20 dB声压级的声音也正好会有20 dB的声音能量密度级——不过绝对数值上,分别会是10 [单位] 声压和100 [单位] 声音能量密度。
回到RMS的话,可以观察到,RMS的量纲是和波形的点的数值一致的场量(因为又开方过了),而非功率量。因此,和RMS对应的其实应该是声压级——也就是说,两个RMS差了10倍的音频,其“声压级”会差10倍(假设你的音响完全无其他损耗),“能量密度”或“功率”则其实应该是差了100倍。不过和上面一样,如果都用dB表示,数值则都是一样的,20dB。也就是说如果你整体提升一个音轨所有点的值2 dB,其RMS也会提升2dB(自己算算就知道),声压级和声能密度级也都会提升2dB。
到此为止,都是纯粹的物理量。牵扯到(感知)响度就复杂起来。说到响度,其实搜了一下相关的文献以外地少,连维基百科都说的很模糊。网上比较常见的是sengpielaudio的一系列文章([1] 和[2] ),这里也以此为基准。我们知道,人的各种感知和对应的物理强度,一般都是呈指数级关系(Stevens’ power law )。其中比较有名的是视觉(对光的敏感程度),这个话题我原来在知乎谈过一次,什么时候也可以整理一下发个blog。听觉自然也不例外,但是“指数级”的指数到底是多少呢?
一般而言,长度不过短、频率适中的声音,可以经验地认为声压级(SPL)每扩大10倍(即20dB),感知响度扩大4倍。也就是说,响度L正比于声压SP^0.6。如果换成声音能量密度,那就是L正比于SI^0.5*0.6=SI^0.3(因为声压和声能密度是开方关系)。换句话说,就是每10dB,响度翻倍(别忘了对于SI和SP,dB数是一样的)。
这里无耻地盗一张图来说明。
响度/声压/声音能量密度对应表 Source:http://www.sengpielaudio.com/calculator-levelchange.htm
OK,既然我们知道了响度至少和能量、声压、甚至常说的dB数都不是线性而是指数关系,那么为啥我们还用RMS?仔细想想就会发现,我们的目的只有一个:使音量保持在一个水平线上。所以,不论他们之间的关系是啥,线性还是不线性,只要都是正相关的就可以:如果俩文件的RMS(或者是ReplayGain算出来的“代表RMS”)经过加减dB之后相同,那至少我们可以说,他们的响度也类似。毕竟,我们并不需要准确知道“A比B响多少”。其实就像我们说RMS是音频“能量”的代表,但也不是RMS大10倍能量就大10倍(而是100倍)。这就好比我们用摄氏度表示物体的冷热程度,你也不能说10度比1度热10倍一样(即使你换算成K,这种说法也不一定成立)。但是如果仅用来比较两者孰大孰小,就没问题。
响度的基准
现在,我们解决了第一个问题——如何测量响度。第二个问题自然就是选取标准。在当时,音响行业并没有任何相应的规范,于是RG的作者从电影行业——电影电视工程师协会(SMPTE)那里借来了一个规范:RMS是-20 dBFS的粉噪音 ,应该(在听众的位置上)呈现为83dB SPL 。仔细解读这句话的话,你会发现它其实讲的是信号强度和实际声压的对应关系。你也可以说成“-15 dBFS的粉噪音应该呈现为88dB SPL”,关系依然不变。不过,这两个数也不能认为是任意选取的——粉噪音用-20 dBFS,是因为这个RMS级别的声音在电影、电视中比较典型,所谓“Alignment level ”。“平均”强度是-20 dBFS,意味着在单侧有着20 dB的动态空间(即“headroom”)。这个强度的声音会被呈现为83dB SPL,大概也是认为83dB SPL是一个比较舒适的数值(这里有一份解读 )。不过这里要注意,这个标准的本意是电影院用的,而电影院的音量,观众是不可调的,所以有一个规定的声压大小(83 dB SPL)很有意义。但是换成家庭媒体,意义就不大了:用户无论是在软件还是硬件,都有额外的Gain或者Volume可以调,这个数字并无太大意义。真正有意义的,是前半部分:-20 dBFS。
但是搞笑之处在于,ReplayGain自己觉得这个数太小(即平均音量太小),而且一般音乐也用不着这么大的headroom,于是自行加了6dB,变成-14 dbFS RMS粉噪音——作为RG的目标。那么,如果假设对应关系不变,那自然这个声音在理想的电影院环境里也就会被呈现为89 dB SPL了。这也就是你为什么会在各种地方看到,RG的目标是89 dB这种说法。但是可以看到,“89 dB”这个数字本身已经并没有任何实际意义了:在RG处理音轨的时候,纯粹是根据上面三步走,算出一个音轨的代表RMS,然后和-14 dbFS RMS的粉噪音的代表RMS比较而已。
事实上,RG1.0的原始代码都可以在这里 下到,是MATLAB写的。里面也包括了一个ref_pink.wav文件,不过这还个是-20 dBFS RMS的,没有修改成-14 dBFS RMS。由于代码非常陈旧(2001年的…),MATLAB的一些函数已经发生了变化。所以,我进行了一些修改,发了个能用的版本在GitHub 。对ref_pink.wav进行RG,可以看到得出的reference vRMS(前面我叫作“代表RMS”的那个东西)是-31.5。也就是说,如果是一个-14 dBFS RMS的粉噪音,就应是-25.5了。在真正的RG的实现中,无论是89/83还是-14/-20,其实都不需要参与计算,只要有这个-31.5/-25.5在就可以了。用同样的函数处理随便一个音频,得到其对应的vRMS为-14.9,也就是说我们需要降低16.6 dB,来使得其vRMS和reference(粉噪音)一致(如果换成-14 dBFS,那就是降低10.6dB)。
dBFS RMS的定义
这里又㕛叒叕得插播一段。如果你好奇地计算一下那个ref_pink.wav的RMS:
[y, Fs] = audioread(‘ref_pink.wav’);
会发现……他并不是-20 dBFS,而是-23.0103 dBFS 。这又是怎么回事?原来,dbFS 又有“传统定义 ”和“数学定义”之分。所谓数学定义,就是我们这里计算的。但是在音响业中,经常用另外一种传统定义:因为音频大多是正弦波的叠加,故所谓的Full scale并无法达到。真正能达到的(在不发生削波的前提下),是一个幅值为1的正弦波的RMS,也就是0.7071。是不是觉得眼熟?前面出现过。这个数字换算成相对于数学上的Full sacle(通过方波可以达到),就刚好是-3.0103 dB。所以,经常情况下,业内说的“Full scale”,或者dBFS,是以这个值作为基准(0 dB)的。因此,一个数学上是-23.0103 dBFS的音频,在传统定义下,就变成了-20 dBFS了。这个定义一般只用于讨论RMS ,在讨论波形上某个点、或者峰值时,FS依然是以1为基准。
ReplayGain——实战篇
OK,在彻底厘清了ReplayGain的今生前世,和相关的一些容易混淆的概念,我们终于可以进入实际应用,以及其中会遇到的问题——这也正是我要写此文的初衷。
响度竞赛
前面说过RG的目的是音量规格化,那就么具体到音乐,其问题来自于从90年代开始的“响度竞赛 ”。简单来说,商业公司发现,如果一个音轨明显比别人音量大,观众会心理上觉得更好听。因此,混音业开始悄悄地渐渐提升音频的响度,以求和别人一起放时“更突出”。
要提升响度,第一步自然是“maximize”——也就是把增益整个音频直到峰值(peak)达到1(或者0 dBFS)。不过要知道,几乎所有的商业混音本身就已经这么做了,那自然就没有上升空间。要进一步提高响度,唯有压缩动态范围——从而可以得到更高的平均响度(RMS)。因此,响度竞赛最大的影响其实并不只是响度增加,而是歌曲的动态范围也减小,起伏变小了(这里有一篇蛮长的文章 ,认为响度竞赛并没有导致动态范围减少。我没细看,不过在RMS level和峰值的差值这个语境下,动态范围变小是不争的事实)。
举例而言,おニャン子クラブ在1985年发行的专辑《KICK OFF》,随便选取一轨“真赤な自転車”,其RMS分别是(左右声道)[-19.6993 -20.3342](此处为“数学定义的”RMS,下同);如果拿它去跑ReplayGain,结果是-3.7319 dB(-14 dBFS粉噪音为基准,下同)。至于其峰值,是0.918945(或-0.7342 dBFS),甚至都没有max’d out(不过整张专辑的峰值确实是1就是了),单边动态范围约是19dB左右。
而前年发售的“ときめきポポロン♪”,RMS是[-11.5458 -11.5820],足足比上面的大了快9dB!峰值是1,也就是说从RMS到峰值的单边动态范围,只有11dB。如果拿这个去跑RG,算出来需要降低9.7776 dB。
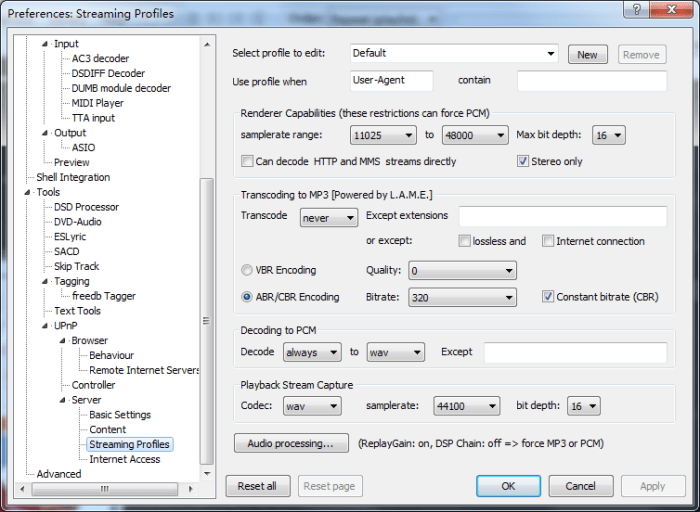
在foobar2000中使用ReplayGain
可以看到,如果要想平衡所有的音量,最简单的办法当然全部都跑一遍RG,那自然也就都均衡了。不过这有俩问题:
跑所有的音乐实在是太不现实了。我本地的音乐足足有8 week+长,全部都跑一边的话大概要累死,而且这个计算其实还是挺慢的。
从上面的计算可以看到,RG默认的reference,实在是响度太低了。连以今天的标准来说声音小到不行的“真赤な自転車”,居然计算出来的是-3.7 dB,也就是还要再小3.7 dB!虽然我们可以通过其他途径再对结果进行增益,例如音量滑块或者音响的音量旋钮,但是这样的话就很难掌握foobar2000和其他程序相互的音量差。
然而,foobar2000内置的增益的目标响度是不可调的[*]。因此,我想到一种折衷的方法,利用foobar2000带的pre-amp选项。Pre-amp是一个RG之外的额外选项,可以在RG之后 再加减一个dB,可以分别给有RG信息的音轨和无RG信息的音轨的设置不同的数值。我先选取大量近年的音乐,也就是音量合适不会太小、不用调整的音乐,然后全部视为一个整体进行RG计算。算出来的结果,大约是-9.5 dB。也就是说,近年的音乐的vRMS比RG的基准,平均来说高了9.5 dB。我们这里记住这个数,但是取消不保存,因为这些音乐并不需要任何处理。相反,对于那些音量偏小的老CD,我们先去真的跑RG:跑完之后的结果自然是一个一致、但是较低的音量。不过,我们只需要在pre-amp里设为+9.5 dB,所有的音乐就一样响了。而且,因为老CD毕竟是少数,这样也不用跑太多次。
—
[*] Foobar2000的RG的目标(-18 LUFS)是不能调的。在选项的高级里,确实倒有个选项可以设target volume level (dB)(默认89,呃至于这个数字怎么来的前面说了,这里你就理解为你修改后的数值和89的差值加到那个-18 LUFS就是),但是那个只对文件转换有用,对播放器内播放没用。
Clipping 和 True peak
和所有的增益有关的东西都需要注意一个点,就是clipping (削波)。我们知道信号的极限就是0 dBFS,如果你通过上述的RG+pre-amp之后,峰值超过了0,那就会被削波——这是我们不愿意看到的。事实上,前面也说了,80年代的音乐虽然RMS很低,但是峰值依然也是接近1的(毕竟,几乎所有的商业CD,出厂前都会max’d out)。经过我们上面的RG+pre-amp的处理,很容易地就超过了1。例如,“真赤な自転車”的峰值是-0.7342 dB,加上RG的-3.7 dB,和pre-amp的+9.5 dB,峰值就变成了+5.1 dB。这也是为什么RG同时也会扫描并且在元数据里记录峰值,便于事后再降低(fb2k里有选项)来防止clipping的缘故。
虽说一般而言,对少数峰值的削波,人耳并不敏感,不过还是尽量要避免这种情况。但是别忘了,在音频输出到mixer之前,还要经过“音量”的计算。一般而言,我的音量都设在-10到-20 dB之间,因此理论上来讲,应该不会有任何削波的问题。
呃,其实说到峰值和削波,还得插播一段讲讲true peak 的问题。如果把数字形式的音乐(即一串数字)还原成模拟信号,相当于从一堆离散的采样点还原出波形。根据采样定理,在遵守原始的频带限制(频率不超过采样频率的一半)下,每一组离散点只能还原出唯一的波形信号 (注:非科班出身的弊端又体现了,我原来一直没能真正理解采样定理。直到今天听到这句把常见说法“2倍于信号的频率采样可以完美采样”反过来的说法才豁然开朗。推荐看Xiph.org的这个视频 ,说的非常 清楚,是科普的典范)。但是,能完美还原波形,不代表波形中的峰值就在我们的采样点中会出现(所以我上面说信号的极限就是0 dBFS也不太准确):
曲线是过采样点的唯一的波形,但是峰值高于采样点 Source: https://techblog.izotope.com/2015/08/24/true-peak-detection/
因此,如果我们仅仅测试采样点的数值,来选取peak,可能会相差甚远。因此,更高级的峰值检测,一般会把信号还原之后再过采样2x甚至4x,从而来找到更准确的峰值。foobar2000的RG也自带oversample factor的选项,在advanced里的tools里。至于这个峰值搞这么准确到底有什么用(毕竟,我们的采样点本身并没有溢出嘛),就要牵扯到DAC了,这里就不赘述。
Windows mixer 的隐藏 Limiter 问题
不过,理论和实践总是不一样的 。在我用上述方案播放音乐时,每当放到那些经过RG+pre-amp的老歌的大动态区域,总有一种很奇怪的感觉——嗯对,就是像被动态压缩过一样,听起来非常不适。百思不得其解之下,我决定把某首歌的RG和pre-amp硬编码进去(也就是说,彻底地修改波形,合成进去RG和pre-amp。RG本身则只是通过元数据的方法,并不真的修改波形文件本身)。虽然这样自然也会产生削波了,不过播放时的最终输出响度应该和有RG tag的原始文件一致。那么,现在播放这俩文件(原始文件+RG tag+re-amp)和转码后的文件,我惊奇地发现,听上去响度居然不一致:原始文件+RG+pre-amp的组合,要明显的小很多。
在实在没有思路的情况下,我斗胆去Fb2k的论坛发了一贴 (要知道这种论坛,一般大牛脾气都不好)。不过惊喜地是,居然得到了答案。
原来,Windows的默认音频输出(Direct Sound,DS)混音器,有一个内置的“Limiter”。当输出音频超过一定值(这个值具体是多少不清楚,一说是0 dBFS)时,Windows会自行降低响度来防止削波。至于降低的方式不明,不过从我的感觉上来讲,不是整体降低音量,应该是类似于动态压缩的方式,即在一定的buffer内遇到超过1的峰值就降低,算法不是很高级从而产生不适感。
前面说过,考虑了音量之后明明根本不会超过0 dBFS才对。但是Foobar2000现在是用Windows自带的mixer来处理音量的(你改fb2k的音量,会发现右下角音量控制里面的foobar程序的音量也会跟着改),结果这个Limiter作用的时间早于音量(会检测音量调整前的峰值),结果就导致了这个现象。至于我自己压制的那个对比的文件,因为溢出的部分已经削波削掉了,自然就不会被Windows限制。不过,这个(limiter作用于音量前的问题)似乎是个Windows的bug :只有Win 7或者Win 8.1会有这个问题,在Win 10中,已经得到修复。另外,如果使用WASAPI之类的输出绕过DS,就完全不会触发这个Limiter,无论你真的溢出了没。
既然知道了原理,那解决方案也很显然了:我把所有没有RG信息的pre-amp设成-9.5 dB,有RG的设为0 dB,就可以保证两者依然均衡;但是总体音量偏小的问题,则只能通过把foobar的音量提升到0到-10 dB,还好之前留的余量足。其实,我也试过有RG信息的设成+3 dB(另外一个对应设成-6.5 dB),好像也不会被限制(虽然明明有少许溢出0 dbFS的peak),这就搞不明白了。
不过,往移动设备上转换的时候,我依然用的是新音乐原封不动、老音乐硬编码进RG+9.5 dB的方式。否则用我的解决方案播放转换过的文件,音量反而会变小了。虽然这样做可能会导致削波(因为转换时自然不会考虑音量进去),不过移动设备听不太出来。更好的方案应该是再加一层DSP,用fb2k自带的Advanced Limiter,把超过的部分智能地调整到0 dBFS以内;虽然有点像动态压缩,但是算法更高级 ,完全没有一般动态压缩的不适感。
顺便一提,根据某个帖子的说法,一般动态压缩的不适感似乎是来源于压缩“释放”得不够快,或者开始得太早的缘故:例如,你有一个音轨一直是很小声突然一个巨响,然后又恢复到很小声。我们想要压缩的自然是这个巨响,但是一般的动态压缩在检测到巨响(会有一个buffer预先检测)之后,会释放的比较慢,从而导致后面紧接着的“小声”部分会有个从小变大的过程,听起来就很不舒适了。
ReplayGain 2.0
故事到此,似乎也就告一段落。但是别急,还有最后一个爆炸性消息:fb2k的“ReplayGain”,并不(再)是ReplayGain 。或者准确地说,并不再是原始的、也就是上面提到的算法了。我也是无意发现这件事的:你把之前我提过的ref_pink.wav文件放进foobar2000跑RG,因为是个-20dBFS RMS的而后来的RG标准是-14(见前文),理论上应该跑出来+6dB对不?结果却是:+2.35 dB 。
这又是怎么回事?!原来在2011年,欧洲广播联盟(EBU)提出了一个新规范,EBU R128 (解读 ),其中对响度规格化进行了规范。其中提出,响度规格化的目标应为-23 LUFS。LUFS又称LKFS ,是ITU-R BS.1770中详细规定的一种测量响度的算法。比起RG,这好歹是一个正儿八经的行业协会,经过多年研究得出的规范,所以很快,foobar2000就修改了RG的算法 (又称RG2.0)为ITU-R BS.1770中的算法了。唯一的区别是,为了和原来的RG保持在相当的响度,又“擅自”把目标提升了一些,改成了-18 LUFS。注意这里的“相当的响度”,是基于对大量音乐分析得出的 (另参见当年的各种对比 ),而并不是把原始的pink噪音拿来分析的;事实上,原始的pink噪音(-14 RMS dBFS版)算出来是 -15.36 LUFS,响于-18。(如果想自己测试要注意,我发现bs1770gain对单声道处理和fb2k不同,于是我手动复制了一份声道把它变成了双声道先)。民间也有很多对这个的实现,例如r128gain (后改名为 bs1770gain ,毕竟讲道理,算法的部分是bs1770规定的,而不是r128)、libebur128 (fb2k就是用这个实现修改而成 )等。
另外,除了直接使用ReplayGain之外,fb2k论坛的版主之一kode54开发了一个DSP插件,foo_r129norm ,可以即时地 将音轨的音量规格化。也就是说,如果用了个这个插件,完全傻瓜化,根本不需要单独去给音轨跑RG啦。不过,考虑到转换到移动设备的需求,我暂时并没有用它。顺便,DSP的处理是在RG之后的,也就是说pre-amp的选项就没效了。你要想再在此基础上提升一个音量,得用EQ整体加个dB咯。
结语
本文断断续续写了2天,阅读了大量的资料。不过可以说是很满足的,基本中间遇到的问题都算是想通了。中间看过的帖,我尽量都用链接插入到文章中了,算是便于自己以后查找。