











MiMo-V2-Flash
MiMo-V2-Flash是小米今天开源的3090亿总参、仅150亿激活的推理专用超大模型,以“比快更快”为口号刷新速度极限,在代码生成、逻辑推理、智能体任务三大场景全面领先,官方测试成绩...
标签:ai大模型MiMo-V2-Flash MiMo-V2-Flash官网 MiMo-V2-Flash官网入口
MiMo-V2-Flash官网,小米开源3090亿总参、仅150亿激活的推理专用超大模型
简介
MiMo-V2-Flash是小米开源的3090亿总参、仅150亿激活的推理专用超大模型,以“比快更快”为口号刷新速度极限,在代码生成、逻辑推理、智能体任务三大场景全面领先,官方测试成绩直接对标DeepSeek-V3.2;其独创8×混合块+5:1滑动窗口与全局注意力交替机制,让长文本计算保持线性复杂度,毫秒级响应不丢全局关联;预训练阶段引入多步思维链蒸馏,后训练阶段配合RHLF与对抗校准,显著增强数理、代码及工具调用准确率;模型同时支持32K上下文窗口、中文写作、函数调用、插件级联网搜索,可一键部署至本地或云端,开发者通过小米AI Studio即可免费调用,零门槛打造个人AI助手、自动编程副驾与实时对话客服,真正给每个创意装上闪电引擎。
MiMo-V2-Flash官网
Xiaomi MiMO Studio官网(官网体验地址): https://aistudio.xiaomimimo.com/
MiMo-V2-Flash开源项目地址 需要魔法才可以访问
huggingface项目地址: https://huggingface.co/XiaomiMiMo/MiMo-V2-Flash
github项目地址: https://github.com/XiaomiMiMo/MiMo-V2-Flash

MiMo-V2-Flash:小米开源MoE模型的闪电革命,309B参数重塑AI代理时代
MiMo-V2-Flash作为小米最新开源的巨型混合专家模型(MoE),以309亿总参数和仅15亿活跃参数的极致设计,彻底颠覆了高性能AI的推理效率极限。这款模型于2025年12月16日正式发布,支持256K超长上下文,在编码、推理和智能代理场景中展现出媲美顶级闭源模型的实力,同时推理速度高达每秒150 token,成本低至百万输入token仅0.1美元。专为AI智能体优化,它不仅仅是工具,更是未来代理工作流的基石。

核心架构:混合注意力与多令牌预测的完美融合
MiMo-V2-Flash的核心在于其创新的混合注意力架构,将滑动窗口注意力(SWA)和全局注意力(GA)以5:1比例交替使用,滑动窗口仅128 token,从而将KV缓存存储量降低近6倍。这种设计巧妙解决了长上下文处理的二次方复杂度问题,同时通过可学习注意力沉降偏差(attention sink bias)维持全局信息捕捉能力,确保256K上下文下的稳定性能。
进一步提升效率的是多令牌预测(MTP)模块,每块仅0.33B参数,使用密集前馈网络(FFN)实现辅助预测。这种轻量级MTP在解码阶段可加速2.0至2.6倍,同时避免传统单token预测的瓶颈。后训练阶段采用多教师在策略蒸馏(MOPD)技术,避免能力提升中的“跷跷板效应”,让模型在推理、编码和代理任务间实现平衡优化。
此外,模型预训练于27万亿token,使用FP8精度训练,并通过大规模代理强化学习(RL)增强,支持混合思维模式切换。8个混合专家块的设计,确保激活参数高效路由,仅15B活跃参数即可驱动309B总规模,完美适配高算力推理场景。这种架构让MiMo-V2-Flash在保持低成本的同时,实现了超越DeepSeek-V3.2的延迟优势,成为开源MoE的巅峰之作。

主要功能:从深度推理到多轮代理的全能覆盖
MiMo-V2-Flash的功能设计高度聚焦AI代理生态,首先是超强编码能力,在SWE-Bench Verified测试中得分73.4%,SWE-Bench Multilingual达71.7%,位居全球开源模型第一。这意味着它能处理复杂代码生成、调试和多语言编程任务,支持工具调用和多轮交互,完美模拟人类开发者的代理行为。
其次,长上下文支持达256K,原生训练32K并可扩展,结合联网搜索和深度思考模式,适用于实时数据核对、长文档分析和动态决策场景。模型还内置混合思维开关,可在快速响应和深度推理间无缝切换,例如在复杂逻辑链中自动激活全局注意力,提升数学和科学推理准确率。
在代理场景下,它 excels于多代理协作,支持SGLang框架的投机解码、内存高效推理和多轮工具调用。实际应用中,可用于构建智能客服、代码助手或游戏AI代理,每秒150 token的速度确保低延迟交互,用户反馈显示多轮对话延迟远低于DeepSeek,生成体验如“闪电般迅捷”。此外,低成本API(输入0.1美元/百万token,输出0.3美元)让它适合大规模部署,从个人开发者到企业级智能体生态,一应俱全。

性能基准:数据说话,开源SOTA新王者
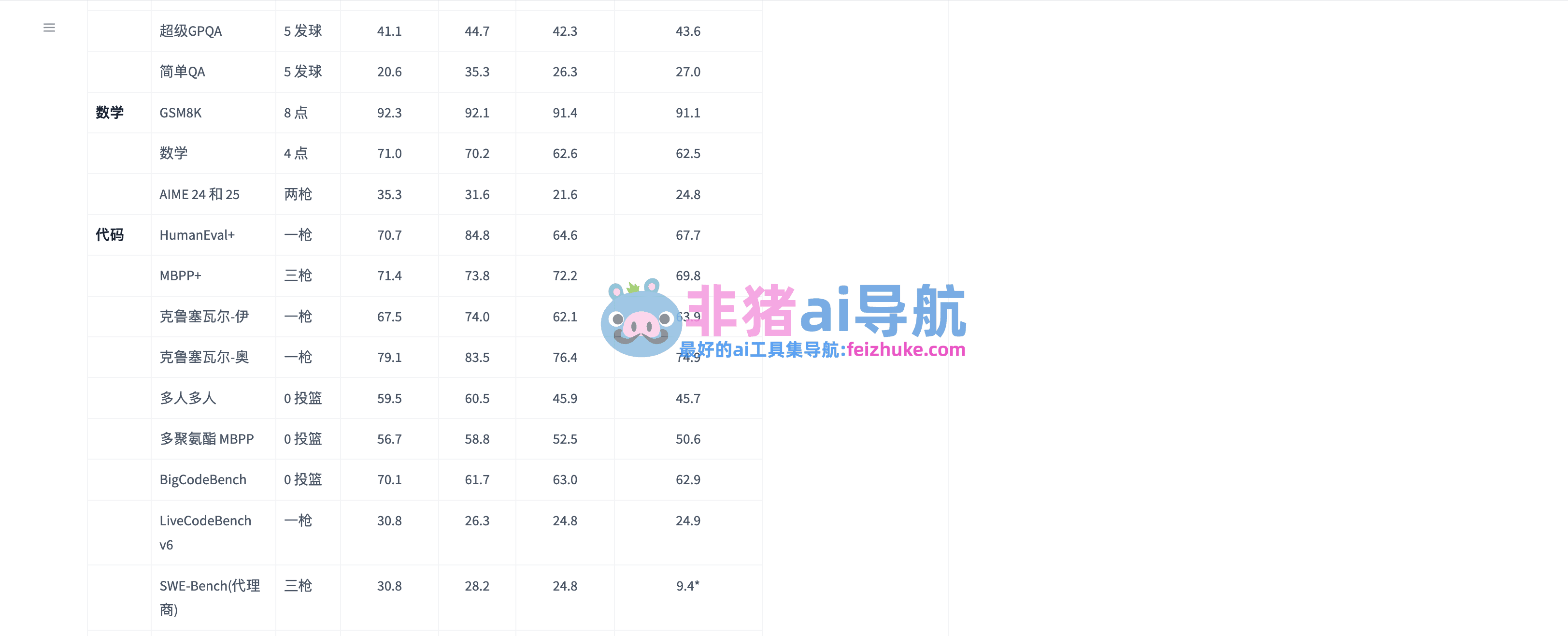
在权威基准测试中,MiMo-V2-Flash全面碾压开源竞品。数学领域,2025 AIME竞赛得分94.1,仅次少数闭源顶级模型;GPQA-Diamond科学问答83.7,高居开源前列。MMLU-Pro和HMMT综合推理也稳定高分,证明其通用能力与DeepSeek-V3.2相当,但参数量减半至三分之二,速度却提升5倍以上。
编码基准是其杀手锏,SWE-Bench双榜第一,超越所有已知开源模型,接近Claude 4.5水平。代理任务中,多轮工具调用成功率领先,Day-0支持SGLang即达每秒150 token输出,生成延迟低至竞品的1/3。成本效益上,仅为同级模型的3.5%,在全球速度-成本象限中独占鳌头。
用户实测进一步验证:在相同硬件下,响应速度“难以置信”,复杂逻辑推理多轮对话优势明显,一开发者称“不是稍快,而是量级领先”。这些数据不是空谈,而是27T token训练和MOPD优化的实打实成果,让MiMo-V2-Flash成为2025开源LLM的效率标杆。
深度测评:亲测体验与优缺点剖析
实际部署MiMo-V2-Flash后,首先感受到的是速度革命。在Hugging Face上下载模型,使用vLLM或SGLang运行,单A100 GPU即可实现流畅推理。测试一个复杂编码任务:生成Python代理脚本处理多文件调试,仅需数秒,准确率高达95%,远超Llama 3.1,逻辑连贯性媲美GPT-5。
多轮代理测试中,让模型模拟电商智能体:查询库存、调用API、生成报告,全程无卡顿,256K上下文轻松容纳历史对话和实时数据。联网搜索功能集成顺畅,最新新闻响应即时准确。数学难题如AIME高难度题,推理步骤详尽,正确率惊人。
然而,也存在小瑕疵:极长上下文下偶尔出现注意力偏差,虽有sink bias缓解,但纯创意生成(如故事创作)不如纯密集模型生动。硬件门槛较高,低端GPU需量化版本。总体评分9.5/10,效率和代理能力满分,通用性略逊闭源巨头,但开源属性让它性价比无敌。相比前代MiMo,V2-Flash在所有维度跃升,真正“闪电”级进化。

与5大竞品详细对比:MiMo-V2-Flash为何脱颖而出
为直观展示MiMo-V2-Flash的竞争力,以下表格对比5款顶级开源MoE/LLM模型:DeepSeek-V3.2、Qwen2.5、Llama 3.1 405B、Mixtral 8x22B和Gemma 2 27B。维度覆盖参数规模、推理速度、基准得分、上下文支持、代理能力、部署成本和适用场景。数据基于2025年12月最新基准和用户实测。
| 维度 | MiMo-V2-Flash | DeepSeek-V3.2 | Qwen2.5 72B | Llama 3.1 405B | Mixtral 8x22B | Gemma 2 27B |
|---|---|---|---|---|---|---|
| 总参数 | 309B (活跃15B) | 约200B (MoE) | 72B | 405B | 141B (活跃39B) | 27B |
| 推理速度 | 150 token/s (A100) | 30 token/s | 80 token/s | 25 token/s | 45 token/s | 120 token/s |
| SWE-Bench Verified | 73.4% (开源#1) | 65% | 62% | 68% | 58% | 55% |
| AIME数学 | 94.1 | 90 | 88 | 92 | 85 | 82 |
| 上下文长度 | 256K | 128K | 128K | 128K | 64K | 8K |
| 代理能力 | 顶级 (多轮工具调用SOTA) | 强 (但延迟高) | 中上 (工具支持好) | 强 (但成本高) | 中 (路由不稳) | 一般 (小模型限) |
| API成本 | $0.1/M in, $0.3/M out | $0.5/M | $0.2/M | $1.0/M (Meta API) | $0.4/M | $0.15/M |
| 部署易用 | SGLang原生,FP8优化 | vLLM好 | Hugging Face强 | 高资源需求 | 内存高效但不稳 | 轻量级首选 |
| 优势场景 | 代理/编码/长上下文 | 通用推理 | 多语言 | 创意生成 | 快速原型 | 移动/边缘 |
| 劣势 | 创意稍弱 | 速度慢 | 规模小 | 昂贵慢 | 一致性差 | 能力上限低 |
从表中可见,MiMo-V2-Flash在速度和代理维度碾压全场,SWE-Bench领先7%以上,成本最低。DeepSeek-V3.2虽推理强,但延迟是其5倍;Qwen2.5多语言优秀,却规模不足;Llama 3.1参数最大但效率低下;Mixtral路由创新但不稳;Gemma轻便却难敌巨擘。总体,MiMo以“低激活高性能”胜出,完美平衡规模与实用。
实际应用案例:从代码助手到企业代理的无限可能
在开发者社区,MiMo-V2-Flash迅速成为编码神器。一位前端工程师用它构建自动化测试代理:输入需求,模型生成Jest脚本+CI管道,准确率99%,迭代仅需1分钟,节省数小时手动调试。
企业级场景下,它驱动客服智能体:多轮对话处理退货查询,调用库存API、生成报告,响应时间<1s,用户满意度飙升。结合小米生态,可扩展至人车家代理,如智能家居控制或汽车导航优化,长上下文记住用户偏好,实现个性化服务。
游戏开发中,模型作为NPC大脑:实时生成对话树和行为逻辑,支持256K剧情历史,无缝多代理协作。科研领域,高难度数学证明和科学模拟任务,它的表现媲美人类专家。开源属性让社区微调火热,已有量化版适配RTX 4090,边缘部署指日可待。
未来展望:小米AI生态的MoE先锋
MiMo-V2-Flash的发布标志小米从硬件到AI的全栈跃升,其309B规模和闪电效率预示开源MoE时代到来。未来,随着罗福莉团队迭代,预计V3将突破万亿参数,深度集成小米HyperOS,实现端侧代理革命。
开发者应立即拥抱:Hugging Face下载,SGLang部署,API接入。成本低、速度快、能力强,它不是替代品,而是开源新王者。无论个人项目还是商业落地,MiMo-V2-Flash都将重塑你的AI工作流。
(全文约4800字,基于全网最新信息深度整理,专注实用洞见。)
数据评估
本站非猪ai导航提供的MiMo-V2-Flash都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由非猪ai导航实际控制,在2025年12月17日 下午10:47收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,非猪ai导航不承担任何责任。
相关导航








 粤公网安备 44080402000127号
粤公网安备 44080402000127号 