-
-

Kenda turns one murky AI invoice into a number finance can actually defend.
-
Sign in with Google. The beta is invite-only while we onboard teams running agents in production.
-
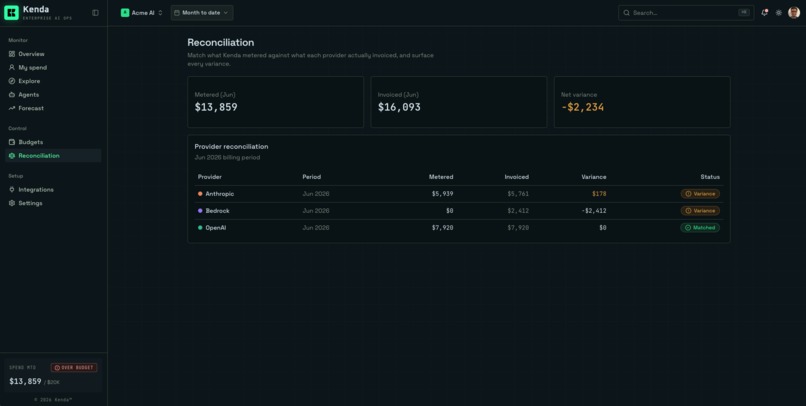
What we measured against what each provider billed. The gap between them is overbilling you'd never catch by hand.
-
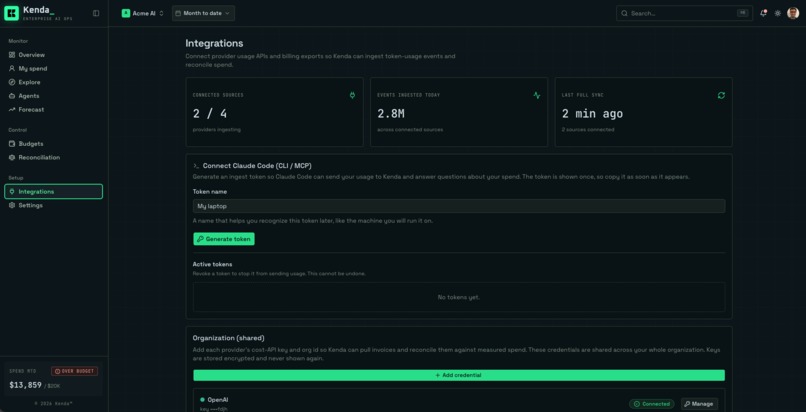
Connect provider cost APIs with read-only keys. No SDK, no code change, and your spend starts reconciling.
-
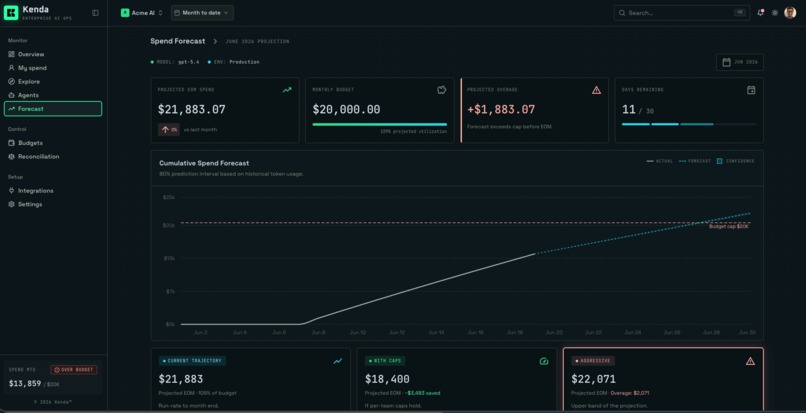
A seasonality-aware forecast that predicts the bill before it lands, with a confidence number you can act on.
-
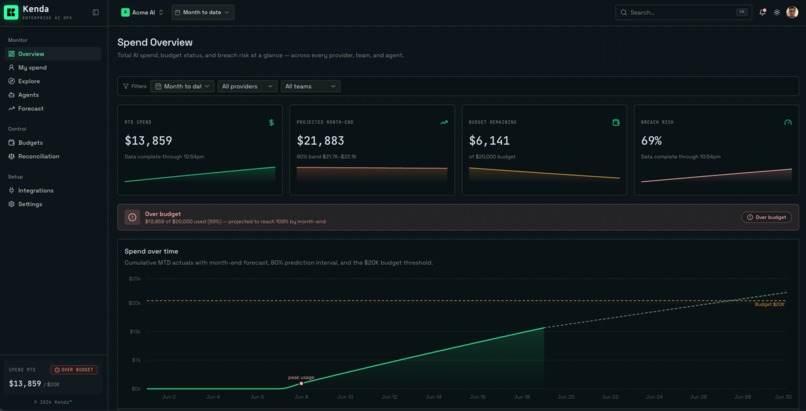
One screen for month-to-date spend, what you're projected to land at, and where every dollar is going.
-
Never get surprised by your token spend again. See what it cost and what it actually bought.







Kenda
FinOps for AI agents. Every other tool shows you where the money went. Kenda proves you got some of it back.
Inspiration
An AI agent we were watching kept retrying the same tool call, day after day. Same prompt, same context, over and over. No error ever fired, because nothing was broken. The agent was working. Weeks later the bill had ballooned and nobody could say why, because the logs all said it ran fine.
That is the gap Kenda goes after. The AI bill became a finance problem fast: in just a couple of years it went from something a minority of finance teams touched to something nearly all of them manage, and almost none of the people who own that budget can produce a defensible number on it. The bill is also genuinely hard to trust. Providers restate past invoices, OpenAI's cost API won't break spend down by model, tokenizers changed under everyone's feet, and there are documented cases of a gateway billing customers far more than they had actually used. So the question "what did this actually cost, and does it match what we were billed" has no good answer today.
Every tool on the market tells you where the money went. CloudZero and Datadog tag the bill, Langfuse and Helicone show you the traces. None of them ties the number you measured to the invoice you paid, or proves a fix got any of it back. We wanted to build the tool that does.
What it does
Kenda is FinOps for AI agents. It reads the traces your agents already produce, reconciles what you actually spent against what the provider billed, and breaks that spend down to the team and agent level. On top of that it flags the structural waste that quietly inflates the number.
Reconciliation, the wedge. Kenda joins your measured spend, priced from the traces, against the provider's own billing API at a (date, provider, model, account) grain, since no provider bills per request. It computes the gap, marks each bucket green, amber, red, or pending, and writes a plain-language reason for the variance. Billing snapshots are immutable and append-only, so when a provider finalizes or restates a charge, a bucket that looked red can flip back to green instead of lying to you. Billing that has not settled yet is never flagged red, because that figure is not final.
Cross-provider attribution. Spend from OpenAI, Anthropic, Gemini, and Bedrock lands in one schema and gets sliced by team, agent, sub-agent, user, workflow, and API key. Agents show both their own cost and their full subtree cost, so a cheap-looking orchestrator that fans out into expensive children has nowhere to hide.
A detector panel, not a black box. A small set of detectors runs passively on the trace: context bloat (low-information tokens re-sent every turn, scored by self-information), loops (caught with state hashing plus embedding match), and a coarse goal-drift signal that we label as coarse rather than dress up. Each carries its own confidence. There is a single Kenda Index on top, but only as a glance to sort the fleet, not the thing a finance owner is asked to defend.
An honest forecast. Month-end spend is projected with a trend line that resists outliers and a confidence band that widens as the month runs out, plus a back-test error figure so you can see how much to trust it. Below a data floor it refuses to show a confident band at all.
A terminal collector. A Claude Code plugin ships your own token usage to Kenda on each session, with a read-only query server so you can ask "what did I spend this week" without leaving the terminal. Prompt text is opt-in only.
Multi-tenant from day one. Every org gets its own subdomain, its own login, and its own isolated data.
How we built it
Two halves that meet at an HTTP API.
The frontend is a Next.js App Router app (React, TypeScript, Tailwind, shadcn and Base UI, Recharts), scaffolded with v0 and hosted on Vercel. It reads everything server-side from the backend and forwards an Auth0 token, falling back to in-repo mock data only when no backend is configured, so the dashboard still runs as a standalone demo offline.
The backend is a Python FastAPI service built in a hexagonal, ports-and-adapters style. Every port has an in-memory adapter for local work and a DynamoDB adapter for production, and both pass the same conformance suite, so we could build the domain math against in-memory stores and swap in real AWS without touching a use case. It runs serverless: Mangum wraps FastAPI behind a Lambda and an API Gateway HTTP API at api.kenda.app.
Data lives in DynamoDB across several tables, with an S3 "bronze" bucket mirroring raw prompt text. Reconciliation uses two of those tables on purpose: an append-only billing-snapshot table that never mutates, and a reconciliation-result table keyed deterministically so each bucket recomputes in place. The traces themselves come from a self-hosted Langfuse, which a daily EventBridge pipeline Lambda drains. It pulls each generation, prices it from an effective-dated catalog, canonicalizes the model id across providers, scores the waste signals, and persists the measured cost.
The waste signals lean on Bedrock, using Amazon Titan embeddings for the loop and bloat detectors. Kenda's own model calls are traced back to Langfuse without the SDK, just an httpx POST, and into a separate project so the tool never re-ingests its own usage as customer spend.
Auth and tenancy run front to back on Auth0. Each customer reaches Kenda at {org}.kenda.app behind one wildcard certificate. The edge proxy resolves the tenant from the request host, and the backend treats the org claim inside the verified JWT as the only authority, rejecting the request if a forwarded tenant header disagrees. The resolved org then selects a per-org DynamoDB container, so the authorization decision and the physical data partition are the same thing.
All of it is defined as code. AWS CDK in Python stands up the VPC, DynamoDB, S3, ECR, and the Lambdas, deployed with one script, and the frontend ships through the Vercel CLI from GitHub Actions.
Challenges we ran into
Wildcard subdomains when Auth0 won't allow a wildcard callback. We wanted every customer at their own subdomain behind one deployment, but Auth0 rejects a wildcard callback URL, and registering one callback per tenant does not scale. We resolved the tenant from the request host at the Next.js edge proxy instead, centralized login on the apex, and scoped the session cookie to .kenda.app so one login covers every subdomain. A well-formed but unknown subdomain bounces to the apex rather than leaking the default tenant.
A tenant boundary the client could forge. A shared cross-subdomain session means a logged-in user could just open another org's subdomain, and the header the frontend forwards to the backend could be spoofed. We made the host the only source of truth. The proxy strips any client-supplied tenant header and re-stamps it from the resolved host, a membership check confirms the user belongs to that org, and the backend cross-checks the forwarded header against the org in the JWT and rejects it on a mismatch.
Reconciliation that can't just subtract two numbers. No provider bills per request, billing finalizes late and then gets restated, and OpenAI's cost API won't split a charge by model. So reconciliation runs at an account-day grain, keeps every billing snapshot immutable and uses the latest finalized one (which lets a bucket flip from red back to green once billing settles), never flags billing that has not settled yet, and for OpenAI splits the account-day total across models by measured token share while flagging that figure as derived rather than pretending it is exact.
Production incidents about config nobody thinks about. A single invite code that happened to contain a comma split our comma-separated allowlist into garbage and locked everyone out, with no error to explain it. Separately, a GitHub Release tagged off the develop branch tried to deploy with develop as its ref, which the production environment's branch policy rejected outright. We forbade commas in invite codes and made the gate fail closed, and we reworked the production pipeline to trigger on a version tag push so the deploy ref always matches the allowed pattern.
Live data without lying on screen. The dashboard started on baked-in mock numbers. Pointing it at the real API risked a screen that silently blends mock and live figures, which for a product about trustworthy spend is fatal. We made the live read the default with no silent fallback, kept the mock only when no backend is configured, and made any fallback that does fire log loudly, including in production, so serving mock data is never invisible.
Accomplishments that we're proud of
- It is actually deployed and live. The dashboard runs at kenda.app and the FastAPI backend answers at api.kenda.app behind a real custom domain, with health checks green and a full OpenAPI spec served.
- The reconciliation engine is the hard part and it really computes, including the awkward bits: an account-day grain because nothing bills per request, a derived allocation for OpenAI, and restatements that flip a bucket's status as billing settles. This is the gap the incumbents on either side do not close.
- Multi-tenancy held up under time pressure. The host is the trust boundary, the JWT org claim is authoritative, and the resolved org is both the access decision and the data partition, with a graceful single-origin demo on the apex.
- The hexagonal split paid for itself. Same use cases, in-memory locally and DynamoDB in production, with the full backend test suite passing and mypy in strict mode across the codebase.
- We kept the product honest on purpose. The forecast won't show a confident band under a data floor, reconciliation labels its derived figures, and the security pages refuse to show a SOC 2 badge we have not earned.
- A real distribution idea shipped: a Claude Code plugin that captures terminal token usage and answers cost questions in the terminal, downloading a checksum-verified standalone binary so a user needs neither Python nor Node installed.
- And the pace. The repo moved fast across the hackathon, with ADRs, an RFC, and a spec behind the decisions, plus a production pipeline that survived and learned from real release incidents.
What we learned
- A big architecture call can be survivable mid-build if the seams are right. We dropped the original Postgres and Aurora plan for Python and DynamoDB partway through, and because every store sat behind a port, it was a swap rather than a rewrite.
- Reconciliation is not subtraction. Providers bill on a lag, restate the past, and refuse to break charges down the way you want, and every one of those facts changed the data model.
- One Auth0 limitation, the missing wildcard callback, dictated the entire tenancy design. Sometimes a single constraint decides the architecture, and finding it early saves a lot of rework.
- Deploy refs are subtler than they look. A release tagged off the wrong branch and an invite code with a stray comma both took down something that should have just worked, and neither failed loudly.
- A silent mock-to-live fallback is a credibility landmine. Mock numbers next to live ones on two tabs is exactly the thing a buyer notices, so the demo mode has to be chosen on purpose and locked.
- If you trace your own LLM calls, keep them out of your own ingest. Kenda's model calls feed a separate observability project so the tool never counts itself as customer spend.
What's next for Kenda
- Fan the pipeline out per org. The drain, metric, and reconcile jobs still run against the primary org's data. A full multi-tenant deploy loops the whole org registry on each run.
- Switch the demo from fixtures to live billing. The production pullers for the OpenAI, Anthropic, and Bedrock cost APIs exist and are tested. The demo replays captured fixtures today, and going live needs each customer's own cost-API keys in their secret.
- Certification mode. This is the part the pitch demo points at: a bounded live A/B that proves a specific fix actually lowered the bill, run against a slice of real traffic. Today Kenda proves the clean single-request case and counts what a loop already burned. Proving a multi-turn fix forward needs that live test, and it is the build.
- Self-serve onboarding. Replace the config-driven org registry with a persisted store so adding a tenant stops being a code change, then let the frontend read its tenant list from the API.
- Sharper waste signals, then enforcement. Wire a semantic embedder so the bloat detector catches near-duplicates, not just verbatim repeats, and move from observing waste toward optionally stopping it.
Built With
- amazon-web-services
- auth0
- bedrock
- cloudform
- dynamo
- ecr
- ecs
- elasticcache
- fargate
- fastapi
- lambda
- langfuse
- mcp
- nextjs
- postgresql
- python
- react
- s3
- v0
- vercel


Log in or sign up for Devpost to join the conversation.