Andrej Karpathy wrote a great post last year on how to train a neural network to play the Atari game Pong by using the Policy Gradients reinforcement learning (RL) algorithm. Given the game’s state as input, the neural network outputs a probability with which we should move the Pong paddle up or down.
I converted Karpathy’s NumPy-only approach to TensorFlow inside a Jupyter notebook. I also created a class to represent the agent playing the game–I stuck all of the code to run the Pong simulation inside that class. Here’s the Github gist, which is best viewed by clicking the link below the embedding 🙂
Here’s a short GIF of some gameplay. The neural-network agent is on the right, and the built-in AI is on the left.

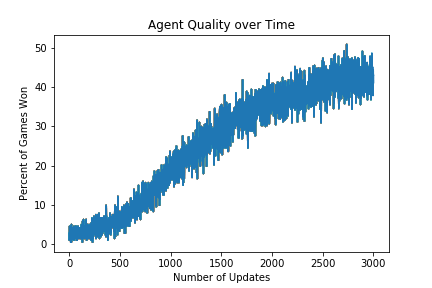
After ~3,000 parameter updates, the Pong-playing neural network can beat the built-in AI more often than not. What’s interesting to me is that this network looks simpler than one that you’d use for MNIST, and it doesn’t require data with labels to learn!